文章目录
- 前言
- 性能优化的原则
- 数据结构优化
- 内存优化
- 磁盘优化
- 网络优化
- CPU优化
- 查询优化
- 数据迁移优化
前言
ClickHouse是一个性能很强的OLAP数据库,性能强是建立在专业运维之上的,需要专业运维人员依据不同的业务需求对ClickHouse进行有针对性的优化。同一批数据,在不同的业务下,查询性能可能出现两极分化。
性能优化的原则
在进行ClickHouse性能优化时,有几条性能优化原则。这几条原则指导了ClickHouse性能优化的方向,在优化方法发生冲突时,应当以如下两条原则为判断标准。
先优化结构,再优化查询
- 合适的表结构和数据类型可以给性能带来非常显著的提升。在尚未进行结构优化的情况下,对SQL语句进行优化,对性能的影响比较小,甚至没有任何影响。ClickHouse的查询性能受底层结构的影响非常大,因此应当先进行结构优化,再进行查询优化。
- 在对结构进行优化时,应当首先对排序键进行优化。ClickHouse通过数据聚集提高查询性能,数据结构带来的加速效应小于数据聚集带来的加速效应。建议按照排序键、数据结构、索引、查询的顺序进行ClickHouse性能调优。
空间换时间
- ClickHouse的特性是查询速度快,因此必然会遇到使用空间换时间的场景。优先对排序键进行优化,排序键优化效果最好的是最左边的第一个排序条件。对于一张宽表,在不同的业务中,排序键优化的顺序不是固定不变的。
- 遇到这种情况,就需要用到空间换时间原则,即将数据按照新的排序键保存一个副本,使用多副本来应对不同的业务需求。
- ClickHouse本身会对数据进行压缩,即使是多个副本,也可能小于真实的数据量。遇到可以使用空间换时间的场景时,可以灵活创建副本,利用冗余实现性能优化。
数据结构优化
数据结构优化指针对表设计、字段类型选择等建表过程进行优化。
ClickHouse使用存储服务于计算的设计理念,其存储引擎和计算引擎绑定,共同协调优化。
由于ClickHouse高性能算法需要底层数据结构的支撑,因此将数据结构优化为适配ClickHouse高性能算法的类型,可以极大提高ClickHouse的查询性能。
巧用特殊编码类型
- 下表列出了ClickHouse支持的几个特殊编码类型,使用特殊编码类型可以极大提高压缩效率,降低数据的大小,从而起到降低磁盘I/O的作用,提高查询性能。
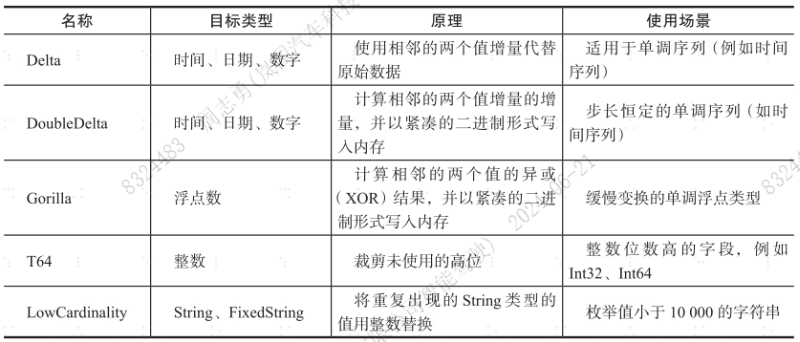
使用特殊编码类型的示例代码如下:
使用复制表作为分布式底层表
- ClickHouse的分布式表的本质是一个本地表的代理,如果其底层本地表有复制的需求,建议用户直接使用复制表,不要使用分布式表引擎提供的复制能力。
- 分布式表引擎的复制能力并不适合所有场景,有可能出现数据在两个副本中不一致的情况,从而导致查询结果出错。
设置字段类型
- 建议用户在使用ClickHouse时,按照字段的实际类型设置数据类型,不要像Hive数仓一样,全部使用String类型。
时间日期字段不要用整型的时间戳
- 在ClickHouse中,已经提供了原生的Date和DateTime类型,这两个类型底层使用时间戳保存数据,不需要针对时间日期进行优化。
- 原生的时间日期类型还可以使用ClickHouse提供的多种时间日期函数,利用ClickHouse的SIMD硬件优化查询性能。
使用默认值而不是Nullable
- ClickHouse使用Nullable标记某个字段列的数据允许为null。ClickHouse在处理null类型的数据时,会使用一个独立的数据文件来记录为null的数据,这会极大增加磁盘空间,增加磁盘I/O时间,降低查询速度。
- ClickHouse官方不建议用户使用Nullable,而是建议用户使用一个特殊意义的值配合表的默认值来处理允许为null的列。
以年龄列为例,可以定义-1为null,然后将年龄列的默认值设置为-1。通过这种方式避免Nullable对性能的影响。
使用字典代替Join操作中的表
- 对于经常参与Join操作的维度表,可以考虑是否使用ClickHouse提供的字典进行保存。
- ClickHouse的每个节点都会将配置文件中的字典载入内存,且支持动态更新字典。
- 在进行Join操作时,由于使用的字典已经预先分布到了集群中的各个节点上,所以Join操作的右表使用字典来代替可以跳过的数据传播过程,提高了查询效率。
内存优化
关闭虚拟内存
- 虚拟内存会降低ClickHouse的速度,也有可能和ClickHouse竞争磁盘I/O,所以在生产环境中最好关闭虚拟内存,以提高ClickHouse的查询性能。
尽可能使用大内存的配置
- ClickHouse在Join操作时默认使用哈希连接(Hash Join)算法,哈希连接算法会将右表载入内存进行操作。
- 如果内存不够,就会因内存溢出而导致查询失败,也可能使Join算法退化为磁盘上的Sort Merge Join算法而导致性能降低。如果业务场景中经常需要进行Join操作,那么用户应当尽可能选择大内存的配置。
磁盘优化
使用SSD
- 使用SSD(Solid-State Drive,固态硬盘)可以极大提高磁盘I/O。在条件允许的情况下,可以将ClickHouse的节点更换为SSD,以获得更好的性能。
冷热分层存储
- 使用全SSD的成本比较高,如果预算不够,那么也可以使用冷热分层存储的方案。
- 下面的代码展示了使用ClickHouse提供的TTL(Time To Live,生命周期)功能实现冷热分层的示例:

使用RAID
- 使用RAID(Redundant Array of Inexpensive Disks,磁盘阵列)提高磁盘I/O,可以防止硬盘损坏导致的数据丢失。
- ClickHouse官方建议在Linux上使用软件RAID。经过测试,建议读者首选RAID6,在保证数据安全的情况下,尽可能提高磁盘I/O速度,起到加速查询的作用。
分区粒度不宜过细
- ClickHouse的数据都在单机上,任务可能触及磁盘、CPU、内存的瓶颈,因此在单机上做并行可能是无效的。分区在ClickHouse上并不能加速查询,读者不应在ClickHouse上将分区粒度设置得太细,否则可能导致原本聚集的数据被打乱,反而影响查询速度。
做好磁盘I/O监控
- 在很多情况下,ClickHouse的瓶颈在磁盘上,建议读者做好磁盘I/O的监控。当磁盘I/O一直处于高位时,可以通过复制表分散一些查询,或者升级磁盘硬件,以获得更好的查询性能。
网络优化
网络优化的核心在于提高网卡带宽和优化网络拓扑布局,需要依照业务实际情况进行规划。
使用万兆或更高带宽的网卡
- ClickHouse集群中数据复制比较频繁,应该对ClickHouse的节点使用高性能网卡。建议使用万兆或更高带宽的网卡,高带宽的网卡可以提高网络传输的效率,提高分布式表的查询性能。
互为副本的机器安排在同一机架上
- 互为副本的集群经常需要进行数据复制,东西流量(East-West traffic)较大,为避免影响整个集群的干线网络,建议将互为副本的机器安排在同一个机架上,这样两个副本可以通过机架上的交换机进行流量传输,避免影响整个机房的带宽。
CPU优化
选择较多内核的CPU
- ClickHouse使用向量化计算引擎,会充分利用CPU的并行能力。
- 由于ClickHouse查询的大量时间都在磁盘I/O上,说明CPU经常处于等待状态,故主频对查询的影响较小。
- 在对ClickHouse硬件进行选型时,首选多核的CPU配置,避免选择CPU主频频率很高但CPU核数少的CPU配置。
选择支持SIMD的CPU
- ClickHouse计算引擎使用SIMD进行向量化加速,应该选择x86架构且支持SSE4.2指令集的CPU。生产环境尽可能不要选择ARM架构的CPU。
查询优化
Join操作时较小的表作为右表
- ClickHouse在Join操作会始终将右表载入内存,进行哈希连接。在编写Join语句时,应当将数据量比较小的表作为右表。
- 同时,在分布式表中,ClickHouse也会始终将右表广播到所有的分片上,将小表作为右表也能减少广播的数据量,提高查询速度。
使用批量写入,每秒不超过1个写入请求
- ClickHouse写入操作的成本比较高,建议使用批量写入的方法,而不要将数据一条一条地写入,尽可能保证每秒只有一个写入请求,也可以通过Buffer表进行缓冲。
对数据做好排序后再写入
- 在写入数据时,建议将数据按照表的排序键进行排序后再写入。鉴于ClickHouse的设计,每次遇到不同分区的数据都会创建一个新的临时分区,分区一旦完成写入,就会成为不可变对象。在极端情况下,未排序的数据多次创建新的临时分区,会引发too many parts的异常。批量写入数据时,事先对数据进行排序可以有效避免上述问题,从而获得很高的查询速度。
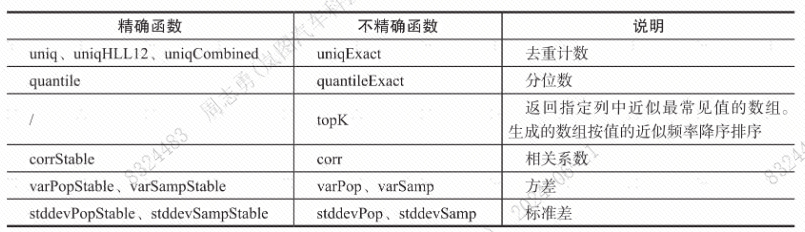
使用不精确函数以提升查询速度
- ClickHouse提供了不精确函数和精确函数两种统计函数。不精确函数只保证数据级准确,不保证精确,但查询速度快;精确函数保证数据的绝对精确,但是查询速度慢,可能触发全表扫描。在一些不需要精确数据的场景下,可以使用不精确函数进行查询。
- 下图展示了几个精确函数和不精确函数:
使用物化视图加速查询
- 物化视图的本质是一张物理表,将数据直接保存到磁盘中以提升查询速度。
- 比物理表更强大的是,物化视图还会检测底层表的变动,并自动将变动同步到物化视图的存储中。下面的代码展示了创建物化视图的方式:

Join下推
- ClickHouse并不适合超大表的Join操作,因此对于复杂的Join操作,建议将Join下推到Spark等大数据集群中实现,只将结果导入ClickHouse中供业务进行即席查询。
- 可以根据自身业务的实际情况,仔细考虑数仓的架构,对于数据量很大的业务场景,没有必要只靠ClickHouse来实现。ClickHouse只能在数据量较小的场景下取代大数据集群。
- 对于数据量庞大的场景,还是应当多种大数据技术并行,共同解决问题。
数据迁移优化
ClickHouse自带的工具具备部署简单、使用方便、维护方便等优点,但ClickHouse的原生数据迁移工具因为简单,无法支撑复杂的应用场景,建议使用Apache SeaTunnel进行数据迁移。
Apache SeaTunnel是一个优秀的高性能分布式大数据集成框架。SeaTunnel对ClickHouse进行了有针对性的优化,可以在大数据场景下更高效地进行数据迁移,为ClickHouse的用户提供了优于原生工具的使用体验。Apache SeaTunnel具备如下优势。
数据源支持丰富
- SeaTunnel定位为新一代的高性能分布式数据集成工具,官方支持二十多种数据源,这意味着使用SeaTunnel可以将多种数据源的数据导入ClickHouse,极大地补充了ClickHouse原生工具的短板。同时活跃的社区也保证工具的质量和对全新数据源的支持速度。
使用简单
- SeaTunnel是一个开箱即用的工具,部署完成后只需要通过向SeaTunnel提供配置文件即可使用,不需要配置数据库连接驱动,也不需要用户编写代码。
完全分布式
- SeaTunnel是一个完全的分布式架构,因此只需要向SeaTunnel提交任务,SeaTunnel会自动将任务进行分布式运行。借助SeaTunnel灵活的任务配置,可以更快速更简单地实现ClickHouse分布式表的数据迁移