大模型出现涌现能力之后,针对大模型的应用也如雨后春笋般。但是,在大模型真正落地之前,其实还需要做好最后一公里,而这个最后一公里,其中不同应用有着不同的方法。其中prompt、微调和RAG都是其中方法之一。本系列就是针对RAG从入门到落地应用的流程。
目录
- 1 概念
- 2 架构
- 3 代码实现
1 概念
RAG的全称是Retrieval-Augment Generation,即称为检索增强生成。通过特定prompt方式为 LLM 提供了从某些数据源检索到的信息,并基于此修正生成的答案。其中有几个关键的点需要知道:
- 一个是从某些数据源检索到的信息
- 提供特定的prompt
- 修正生成答案
简单用一句话来说就是:利用向量数据库将格外的知识以向量存储,然后在回答用户问题时,先将用户问题在向量数据库中进行相似度查询,将查询结果以prompt的方式扔给大模型,获得最终答案。
那么RAG与prompt、微调(fine-tuning)有何应用场景的不同,以下是整理了RAG与其对比表格:
| prompt | fine-tuning | RAG | |
|---|---|---|---|
| 定义 | 在不改变模型参数的前提条件下,利用提示工程来提升大语言模型处理复杂任务场景的能力 | 通过一个微训练的过程来修改大模型它本身的参数,使模型能更加专业化 | 在不改变大模型参数下,通过大语言模型理解用户的查询需求,并将相关的片段从数据库中检索出来,将提示工程与数据库查询相结合以获得上下文丰富的答案 |
| 解决问题 | 提高回答的精准度 | 更擅长回答特定场景下的相关问题 | 提升生成内容的精准度且保留数据安全 |
| 场景 | 通用且简单的场景,比如普通聊天问答等 | 开放专业领域,比如医疗、法律等场景 | 封闭专业领域,比如企业内部数据场景 |
| 优点 | 无需改变模型;推理耗时低;成本低; | 准确度高;推理耗时低; | 无需改变模型;准确度高;安全性强;及时内容; |
| 缺点 | 准确度低;稳定性低;无及时内容; | 成本高;灵活度低;稳定性低 ; | 流程复杂;成本较高; |
三者都有不同的优缺点,在实践中,可以参考以下图表对你的应用场景进行适配:
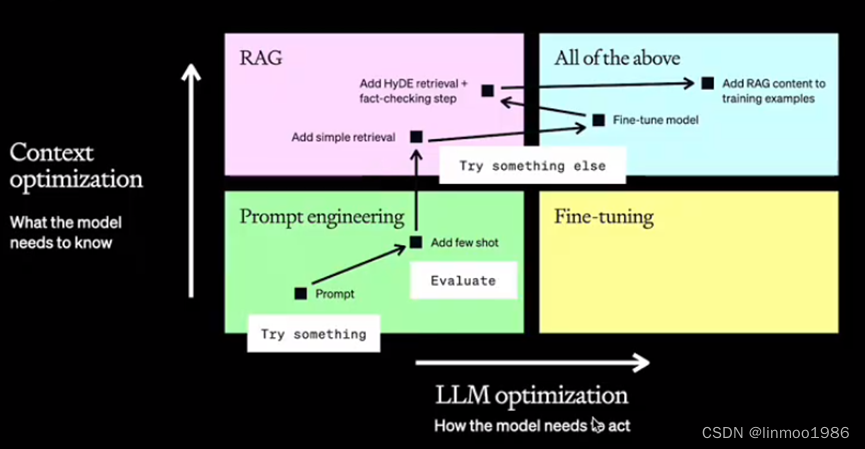
1) 横轴表示LLM本身优化,也就是优化LLM本身按照你想要的表达方式来表达
2) 纵轴表示上下文优化,也就是增加LLM的专业知识
- Prompt engineering:相当于告诉你要考试,但是考试内容没有告诉你
- RAG:相当于给你一本书,在考试的时候你可以查
- Fine-tuning:相当于你学习了知识,然后闭卷考试
- Fine-tuning+RAG:相当于你学了知识的同时开卷考试
2 架构
一个RAG架构应该是怎么样的?你或许见过比较复杂的流程,但是这里先介绍一个RAG最少需要包括哪些部分。(后续会逐步介绍各个模块以及更多优化的流程)

1)专业知识:需要一个专业知识读取,这时候可能是pdf、Excel等不同类型的文档,因此需要一个文档读取工具
2)入库:需要将专业知识入库,而入库的操作就是将专业知识向量化,也就是embedding,因此你需要一个embedding工具
3)数据库:一般使用向量数据库,当然也可以使用其它(但考虑到相似度搜索,向量数据库最合适),其作用就是用于存储格外的专业知识,用于问题做相似度匹配
4)prompt:给特定的prompt,比如:根据以下知识:…(这里填入查询出来的内容),回答:…(这里是问题)。
3 代码实现
本实例是基于text2vec-large-chinese将文档向量化,采用Chroma向量数据库,大模型使用ChatGLM,基础架构使用LangChain。都是本地部署,因此需要做一些前置工作。
前置工作:
1)下载text2vec-large-chinese模型
2)下载ChatGLM3-6B的模型
3)下载ChatGLM3的github源码,运行openai_api_demo/api_server.py文件,启动api服务
from langchain.document_loaders import DirectoryLoader
from langchain.prompts import PromptTemplate
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.huggingface import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.chains import RetrievalQA
from langchain.llms import ChatGLM
import os# 第一步,加载text2vec-large-chinese模型
encode_kwargs = {"normalize_embeddings": False}
model_kwargs = {"device": "cuda:0"}
embeddings = HuggingFaceEmbeddings(model_name='text2vec-large-chinese路径', # 换成自己的embedding模型路径model_kwargs=model_kwargs,encode_kwargs=encode_kwargs
)
# 第二步,创建数据库
if os.path.exists('VectorStore'):db = Chroma(persist_directory='VectorStore', embedding_function=embeddings)
# 第三步,加载文档
loader = DirectoryLoader("documents文档路径") # 换成自己的文档路径
documents = loader.load()
text_spliter = CharacterTextSplitter(chunk_size=256, chunk_overlap=0)
documents = text_spliter.split_documents(documents)
# 第四步,存储文档
database = Chroma.from_documents(documents, embeddings, persist_directory="VectorStore")
database.persist()
# 第五步,创建llm
print("load model api")
llm = ChatGLM(endpoint_url='http://127.0.0.1:8000', # 换成自己的apimax_token=80000,top_p=0.9
)
# 第六步,设置prompt
QA_CHAIN_PROMPT = PromptTemplate.from_template("""根据下面的上下文(context)内容回答问题。
如果你不知道答案,就回答不知道,不要试图编造答案。
{context}
问题:{question}
""")
print("load RetrievalQA")
# 第七步,进行相似度查询数据
retriever = database.as_retriever()
# 第八步,将数据和问题组成prompt格式,扔给大模型获取回答
qa = RetrievalQA.from_chain_type(llm=llm,retriever=retriever,verbose=True,chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
print("running... ...")
print(qa.run("ChatGLM是什么"))