第三天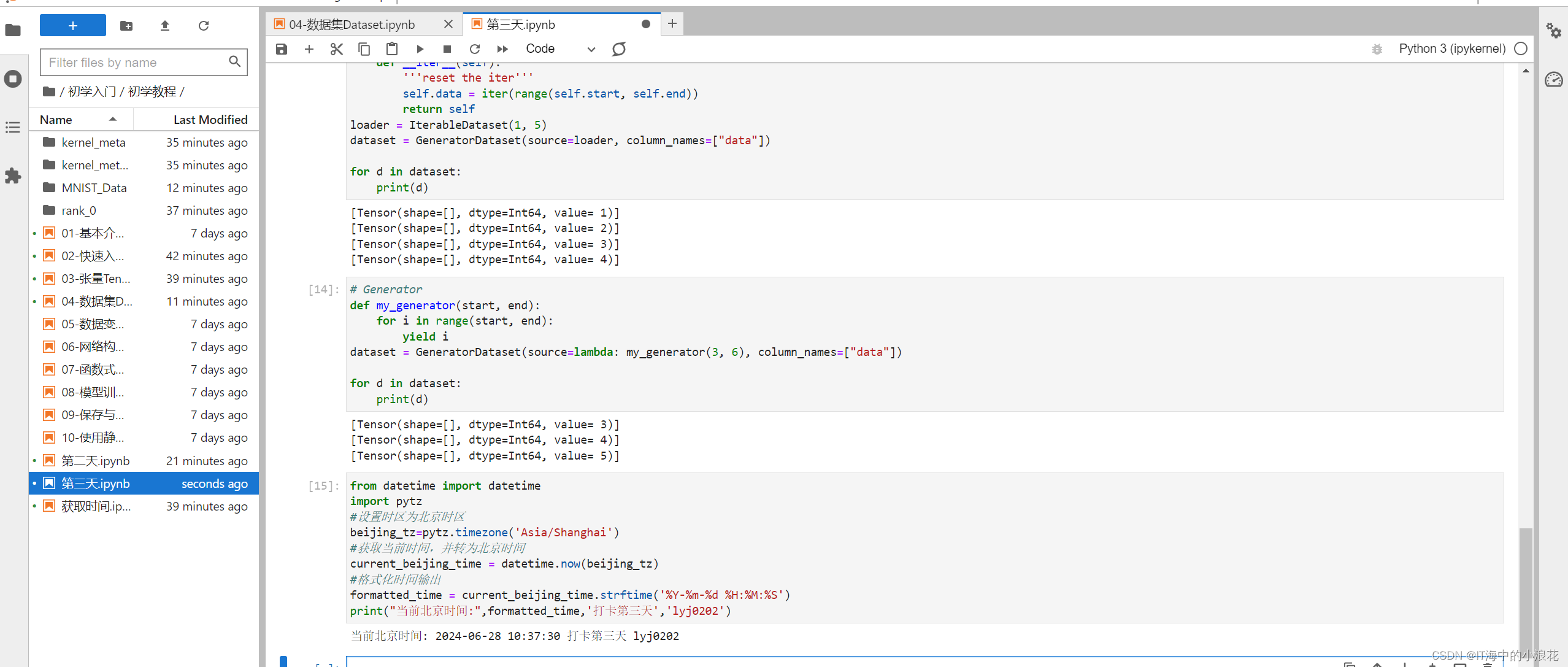
今天学习了不同的数据集加载方式、数据集常见操作和自定义数据集方法。
1.数据集加载。
以Mnist数据集为例。mindspore.dataset提供的接口仅支持解压后的数据文件,因此我们使用download库下载数据集并解压。
2.数据集迭代。
用create_tuple_iterator或create_dict_iterator接口创建数据迭代器,迭代访问数据,访问的数据类型默认为Tensor;若设置output_numpy=True,访问的数据类型为Numpy。
3.数据集常见操作:
3.1数据集随机shuffle可以消除数据排列造成的分布不均问题。
3.2map操作是数据预处理的关键操作,可以针对数据集指定列(column)添加数据变换(Transforms),将数据变换应用于该列数据的每个元素,并返回包含变换后元素的新数据集。
3.3将数据集打包为固定大小的batch是在有限硬件资源下使用梯度下降进行模型优化的折中方法,可以保证梯度下降的随机性和优化计算量。
4.自定义数据集
4.1可随机访问数据集
4.2可迭代数据集
4.2.1生成器
《昇思25天学习打卡营第3天 | 昇思MindSpore数据集 Dataset》
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/362985.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

摒弃反模式:使用Kotlin委托优化Android BaseActivity
摒弃反模式:使用Kotlin委托优化Android BaseActivity
在Android开发中,许多开发者习惯于创建名为“BaseActivity”或“BaseFragment”的基类,以便在所有Activity或Fragment中共享一些通用行为。这种方法乍一看似乎是个好主意,但实…
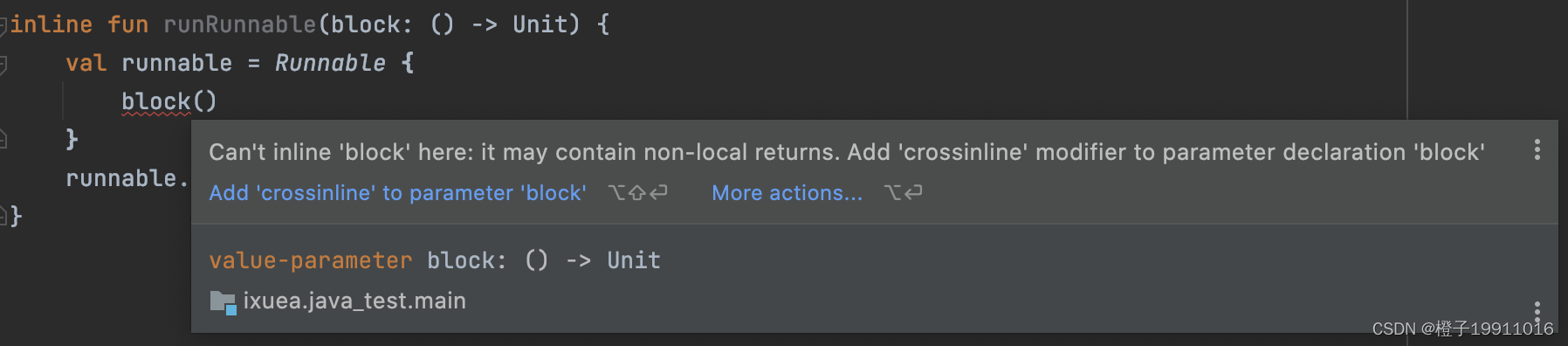
Kotlin 中的内联函数
1 inline
内联函数:消除 Lambda 带来的运行时开销。
举例来说:
fun main() {val num1 100val num2 80val result num1AndNum2(num1, num2) { n1, n2 ->n1 n2}
}fun num1AndNum2(num1: Int, num2: Int, operation: (Int, Int) -> Int): Int …
Docker 安装最新版本 Jenkins
目录
1、下载、启动容器、更新到最新版本
2、查看初始密码两种方式:
3、默认安装的部分未汉化,删除默认的汉化插件。重启容器,重新安装汉化插件
4、安装 Publish over SSH、docker-build-step 、Docker Commons 插件
5、配置服务器连接信…

【红帽战报】6月RHCE考试喜报!
往期战报回顾:
点击查看【战报】5月RHCE考试喜报!通过率100%
点击查看【战报】4月份红帽考试战报!
点击查看【战报】PASS!PASS!2023年终来一波RHCE考试 微思网络-红帽官方授权合作伙伴!面向全国招生&…
Python爬取中国天气网天气数据.
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称
名称:Python爬取中国天气网天气数据
2.主题式网络爬虫爬取的内容与数据特征分析
本次爬虫主要爬取中国天气网天气数据
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
reques…
![[火灾警报系统]yolov5_7.0-pyside6火焰烟雾识别源码](https://img-blog.csdnimg.cn/img_convert/246ade3c09797e47af69d416f0b27504.jpeg)
[火灾警报系统]yolov5_7.0-pyside6火焰烟雾识别源码
国内每年都会发生大大小小的火灾,造成生命、财产的损失。但是很多火灾如果能够早期发现,并及时提供灭火措施,将会大大较小损失。本套源码采用yolov5-7.0目标检测算法结合pyside6可视化界面源码,当检测到火灾时,能否发出…

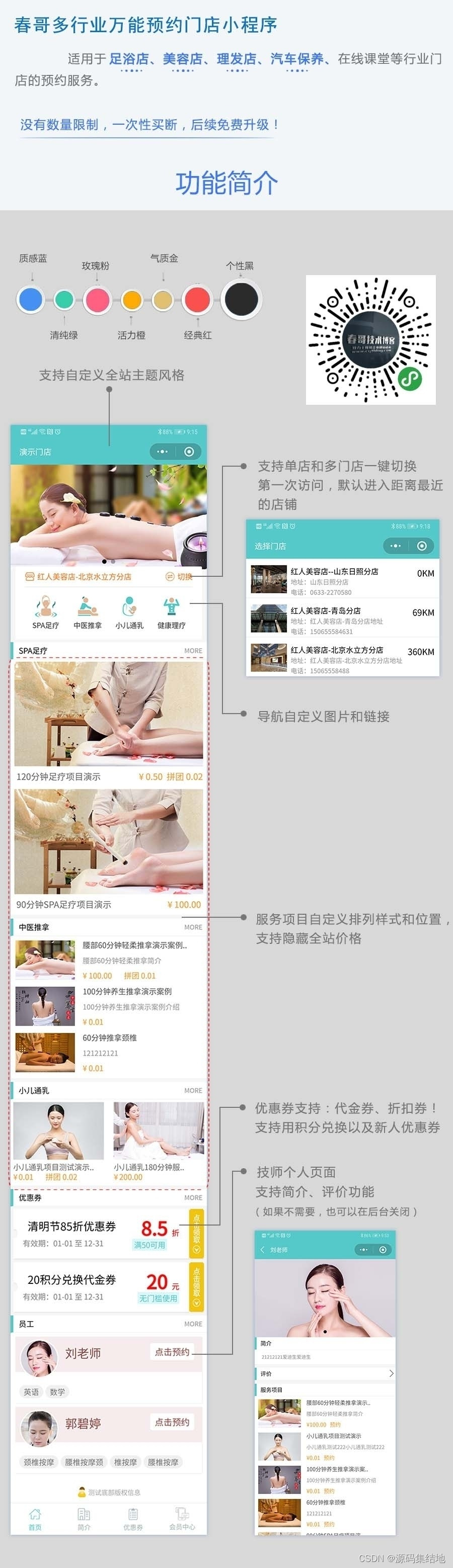
多行业预约门店服务小程序源码系统 支持多门店预约 带完整的安装代码包以及搭建教程
系统概述
该系统基于先进的云计算和大数据技术,采用模块化设计,具有高度的可扩展性和可定制性。无论是餐饮、美容美发、健身房还是其他服务行业,都可以通过该系统轻松实现多门店预约功能。同时,我们还提供了丰富的接口和插件&…

STM32-hal库学习(4)--usart/uart通信 (同时显示在oled)
前言:
关于usart详解:
stm32-USART通信-CSDN博客
因为在oled上显示,我们直接在上一个工程进行修改:
STM32_hal库学习(3)-OLED显示-CSDN博客 其他配置与oled显示工程保持不变,打开oled文件的…

html渲染的文字样式大小不统一解决方案
React Hooks 封装可粘贴图片的输入框组件(wangeditor)_react 支持图片拖拽的输入框-CSDN博客
这篇文章中的wangediter可粘贴图片的输入框,输入的文字和粘贴的文字在dangerouslySetInnerHTML渲染后出现了字体不统一的情况
在html中右键检查可…
短视频利器 ffmpeg (2)
ffmpeg 官网这样写到
Converting video and audio has never been so easy.
如何轻松简单的使用: 1、下载
官网:http://www.ffmpeg.org
安装参考文档: https://blog.csdn.net/qq_36765018/article/details/139067654 2、安装
# 启用RPM …
基于Java微信小程序火锅店点餐系统设计和实现(源码+LW+调试文档+讲解等)
💗博主介绍:✌全网粉丝10W,CSDN作者、博客专家、全栈领域优质创作者,博客之星、平台优质作者、专注于Java、小程序技术领域和毕业项目实战✌💗 🌟文末获取源码数据库🌟感兴趣的可以先收藏起来,还…
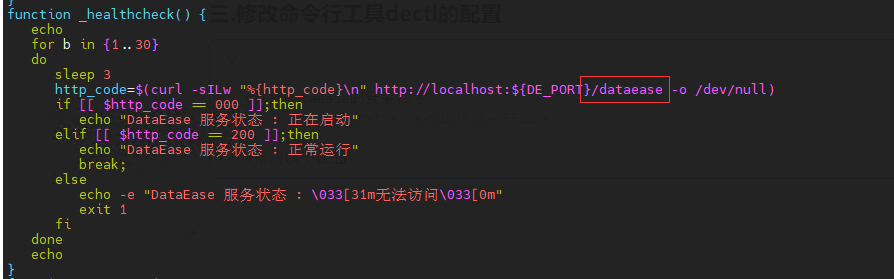
Dataease配置Nginx代理
Dataease配置Nginx代理
一.修改前端静态资源地址和后端接口地址
**1.**修改应用程序的上下文路径
配置文件地址:backend/src/main/resources
找到文件application-whole.properties,做如下修改: **2.**修改前端静态资源路径和打包配置
配…
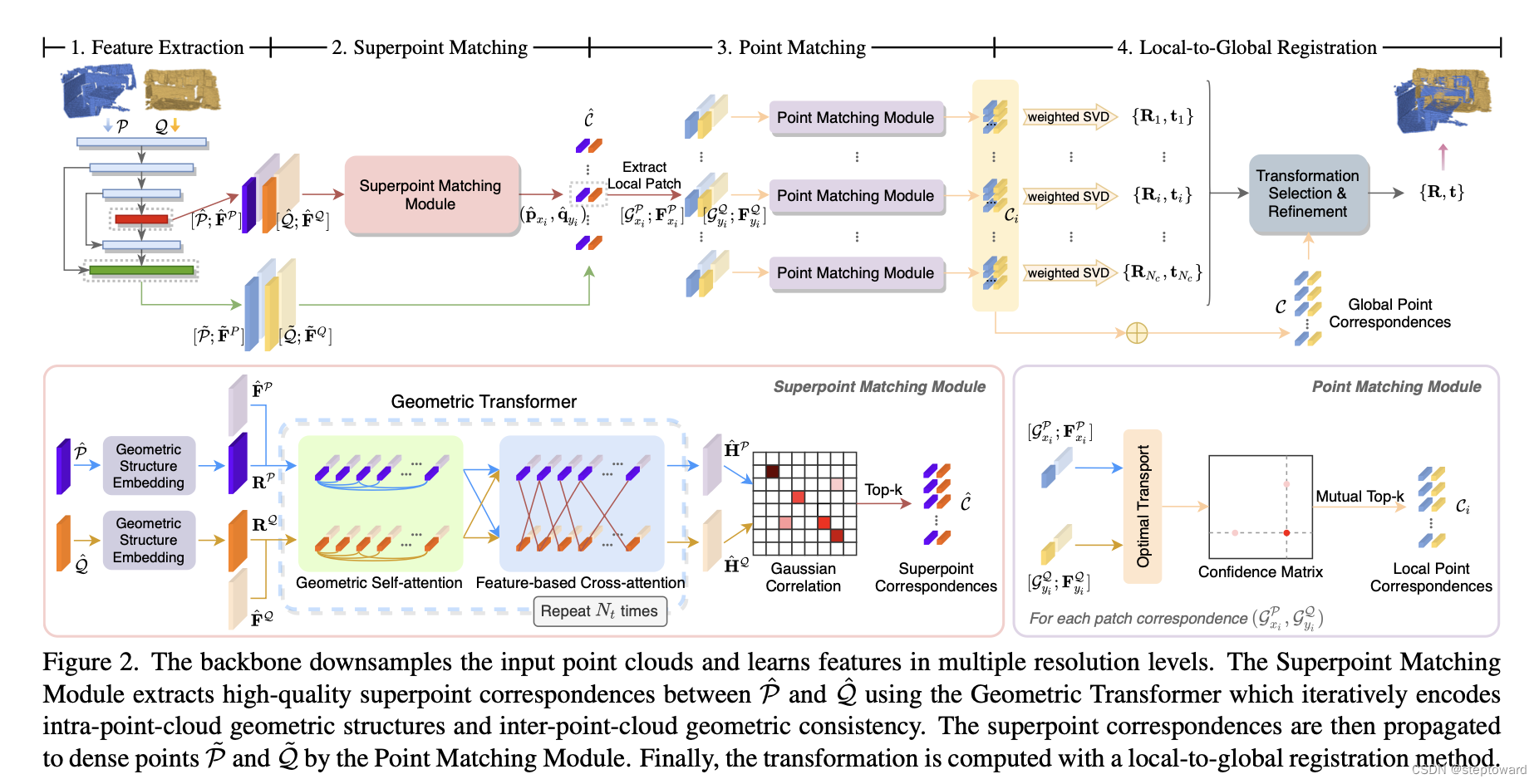
【基于深度学习方法的激光雷达点云配准系列之GeoTransformer】——模型部分浅析(1)
【GeoTransformer系列】——模型部分 1. create_model2. model的本质3. 模型的主要结构3.1 backbone3.2 transformer本篇继续对GeoTransformer/experiments/geotransformer.kitti.stage5.gse.k3.max.oacl.stage2.sinkhorn/下面的trainval.py进行详细的解读,主要是模型部分, 可以…

【机器学习】ChatTTS:开源文本转语音(text-to-speech)大模型天花板
目录 一、引言
二、TTS(text-to-speech)模型原理
2.1 VITS 模型架构
2.2 VITS 模型训练
2.3 VITS 模型推理
三、ChatTTS 模型实战
3.1 ChatTTS 简介
3.2 ChatTTS 亮点
3.3 ChatTTS 数据集
3.4 ChatTTS 部署
3.4.1 创建conda环境
3.4.2 拉取源…
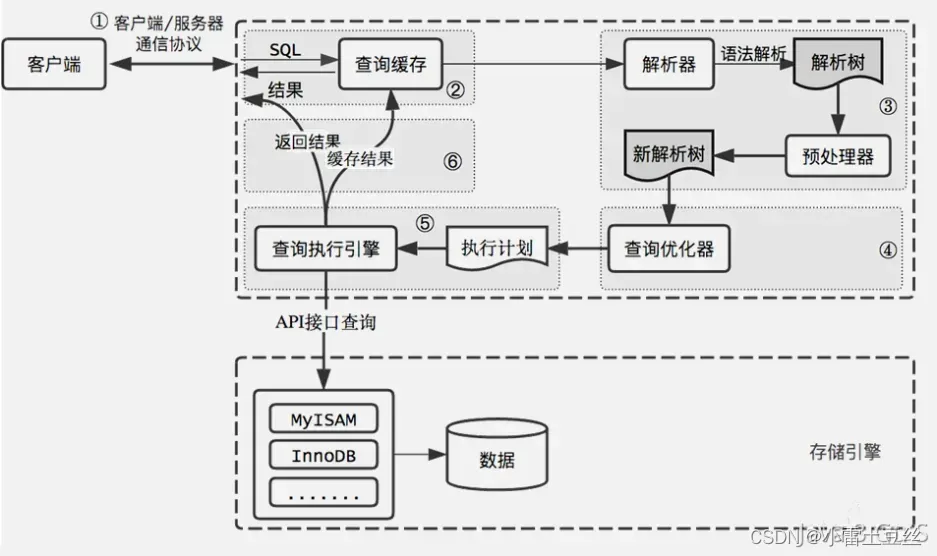
MySQL一条SQL语句的执行过程
例:SELECT * FROM USERS WHERE age 18 AND name student;
执行过程如下图: 综合上面的说明,我们分析下这个语句的执行流程: 1、使用连接器通过客户端/服务器通信协议与MySQL建立连接,并查询是否有权限。 2、MySQL8.…
![[电子电路学]电路分析基本概念1](https://img-blog.csdnimg.cn/direct/d62ffa0f718145248c1e2e57131bd65f.png)
[电子电路学]电路分析基本概念1
第一章 电路分析的基本概念和基本定律
电路模型 反映实际电路部件的主要电磁性质的理想电路元件及其组合,是实际电路电气特性的抽象和近似。
理想电路元件 实际电路器件品种繁多,其电磁特性多元而复杂,分析和计算时非常困难。而理想电路元件…

C# 在WPF .net8.0框架中使用FontAwesome 6和IconFont图标字体
文章目录 一、在WPF中使用FontAwesome 6图标字体1.1 下载FontAwesome1.2 在WPF中配置引用1.2.1 引用FontAwesome字体文件1.2.2 将字体文件已资源的形式生成 1.3 在项目中应用1.3.1 使用方式一:局部引用1.3.2 使用方式二:单个文件中全局引用1.3.3 使用方式…

Linux基础 - 使用 vsftpd 服务传输文件
零. 简介
文件传输协议(File Transfer Protocol,FTP)是用于在网络上进行文件传输的标准网络协议。
FTP 允许客户端和服务器之间进行文件的上传、下载、删除、重命名等操作。它基于客户端 - 服务器模型工作,通常使用 TCP 协议进行…

Arduino - Keypad 键盘
Arduino - Keypad
Arduino - Keypad
The keypad is widely used in many devices such as door lock, ATM, calculator… 键盘广泛应用于门锁、ATM、计算器等多种设备中。
In this tutorial, we will learn: 在本教程中,我们将学习:
How to use key…
最新文章
- 怎么将微信同步到wordpress/seo 网站推广
- 上海金融网站建设/app拉新佣金排行榜
- 城乡建设部网站首页甲级/查关键词排名软件
- 网站如何做淘宝客/海外营销方案
- 浙江华临建设集团网站/网站关键词在哪里看
- 如何把php做的网站做成app/西安网站搭建公司
- 动态规划问题-删除并获得点数(Java实现)
- react + ts定义接口类型写法
- 【教程】Ubuntu设置alacritty为默认终端
- 使用Element UI实现前端分页,及el-table表格跨页选择数据,切换分页保留分页数据,限制多选数量
- 写给初学者的React Native 全栈开发实战班
- 学习日志010--python异常处理机制与简单文件操作
推荐文章
- LeetCode解法汇总2476. 二叉搜索树最近节点查询
- ##__VA_ARGS__的作用
- #systemverilog# 之 event region 和 timeslot 仿真调度(七)Active/NBA 咋跳转的?
- (15)衰落信道模型作用于信号是相乘还是卷积
- (5)所有角色数据分析页面的构建-5
- (8)SpringMVC中的视图类型及其特点,以及视图控制器view-controller的配置
- (9)使用RESTful风格时开启静态资源的映射和请求方式转换的配置
- (delphi11最新学习资料) Object Pascal 学习笔记---第10章第6节(关于混合RAD和OOP的15个技巧)
- (golang)切片何时会创建新切片或影响原切片
- (M)unity2D敌人的创建、人物属性设置,遇敌掉血
- (八) 初入MySQL 【主从复制】
- (二十)Flask之上下文管理第一篇(粗糙缕一遍源码)