本文主要讲tensor的裁剪、索引、降维和增维
Tensor与numpy互转、Tensor运算等,请看这篇文章
目录
9.1、首先看torch.squeeze()函数:
示例9.1:(基本的使用)
小技巧1:如何看维数
示例9.2:(指定降多少维)
小技巧2:如何理解如size([2,1,2,1,2])等等张量的形状
示例9.3:(不可降维的张量)
9.2、torch.unsqueeze()函数
9.3、torch.view()函数和torch.resize_()函数
十、Tensor的索引
10.1、Tensor的一般索引(共享内存)
10.2、Tensor的高级索引(不共享内存)
理解辅助:
小技巧:什么是共享内存?
python列表的共享内存:
张量的一般索引或高级索引得出的张量是否共享内存:
十一、Tensor梯度裁剪
torch.clamp(tensor,min,max,out=None)函数:
本文主要讲tensor的裁剪、索引、降维和增维。同时详细讲了入门者的痛点就是看不懂tensor的size表示或者看不懂其内部结构,并且补充了一个大多数人都不知道的增、降维的方法,索引位置如何理解等
九、Tensor的降维和增维
我们常见的用于tensor的维数操作有很多如
torch.squeeze()
可降维、
torch.unsqueeze()
可增维
,下面我们通过一些例子简介两个函数
9.1、首先看
torch.squeeze()
函数:
示例9.1:(基本的使用)
import torch as t
a=t.ones(2,1,2,1,2)
print("a==",a)
print("a.size()==",a.size())
b=t.squeeze(a)
print("b==",b)
print("b.size()==",b.size())
运行结果:
a== tensor([[[[[1., 1.]],
[[1., 1.]]]],
[[[[1., 1.]],
[[1., 1.]]]]])
a.size()== torch.Size([2, 1, 2, 1, 2])
b== tensor([[[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.]]])
b.size()== torch.Size([2, 2, 2])
小技巧1:如何看维数
一般我们可以直接认为
( 后面有多少个 [ 就是多少维
,如上面的示例9.1的a我们数一下发现其 ( 后面有5个 [ 那么我们可以说它是一个五维的张量或者说是一个五阶的矩阵,再如示例9.1的b,他是一个三维的张量,我们发现在用了一次
torch.squeeze()
函数就降了两维,那如果我只需要降一维要怎么操作呢?下面示例9.2操作一下:
示例9.2:(指定降多少维)
import torch as t
a=t.ones(2,1,2,1,2)
print("a==",a)
print("a.size()==",a.size())
b=t.squeeze(a,1)
print("b==",b)
print("b.size()==",b.size())
c=t.squeeze(a,0)
print("c==",c)
print("c.size()==",c.size())
运行结果:
a== tensor([[[[[1., 1.]],
[[1., 1.]]]],
[[[[1., 1.]],
[[1., 1.]]]]])
a.size()== torch.Size([2, 1, 2, 1, 2])
b== tensor([[[[1., 1.]],
[[1., 1.]]],
[[[1., 1.]],
[[1., 1.]]]])
b.size()== torch.Size([2, 2, 1, 2])
c== tensor([[[[[1., 1.]],
[[1., 1.]]]],
[[[[1., 1.]],
[[1., 1.]]]]])
c.size()== torch.Size([2, 1, 2, 1, 2])
小结:
由示例9.2我们可以看出
torch.squeeze(input,dim=None)
函数的参数dim当指定值
为0时则不进行降维操作
,
若为1,则降一维
;那么在这里我们要降多少维就用多少次就可以啦
小技巧2:如何理解如size([2,1,2,1,2])等等张量的形状
在上面两个例子中如果你看torch.Size([2, 1, 2, 1, 2])这些一脸懵逼,看不出来是几维异或看不出来这个张量的结构是怎么样的,请看看我的理解,入门你可以认为
这里 [] 里面多少个数字就是多少维
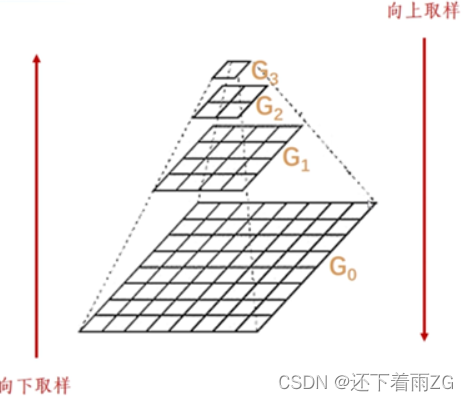
那么怎么看这个张量的形状或者说行和列是怎么个构成呢?比如一个张量torch.Size([a, b, c, d, e])
那么这就是
一个有a个元素的五维张量,这a个元素均是四维张量,一个四维张量又由b个三维张量组成,一个三维张量由c个二维张量组成,这个二维张量的形状为d*e即d行e列
如示例9.2的c

那么你发现规律了吗?


从这个图例也可以很好理解
再如torch.Size([1, 2, 3, 4, 5])就是一个有1个元素的五维张量,这1个元素均是四维张量,一个四维张量又由2个三维张量组成,一个三维张量由3个二维张量组成,这个二维张量的形状为4*5即4行5列
看看输出:
tensor([[[[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]]],
[[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]],
[[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1.]]]]])
那么是不是所有的张量都可以用进行降维呢?显然不是,在上面的例子中我们就可以看出被降的维数都是只有一个元素的,下面一个例子说明:
示例9.3:(不可降维的张量)
import torch as t
a=t.ones(2,2,2).squeeze(1)
b=t.ones(1,2,2).squeeze(1)
c=t.ones(2,1,2).squeeze(1)
print(b)
print("a.shape=={}\nb.shape=={}\nc.shape=={}\n".format(a.shape,b.shape,c.shape))
运行结果:
tensor([[[1., 1.],
[1., 1.]]])
a.shape==torch.Size([2, 2, 2])
b.shape==torch.Size([1, 2, 2])
c.shape==torch.Size([2, 2])
9.2、torch.unsqueeze()函数
与
torch.squeeze(input,dim=None)
函数使用方法类似
import torch as t
a=t.ones(2,2,2).unsqueeze(1)
b=t.ones(1,2,2).unsqueeze(2)
c=t.ones(2,1,2)
d=t.unsqueeze(c,0)#与d=t.ones(2,1,2).unsqueeze(0)同
print("a.shape=={}\nb.shape=={}\nd.shape=={}\n".format(a.shape,b.shape,d.shape))
运行结果:
a.shape==torch.Size([2, 1, 2, 2])
b.shape==torch.Size([1, 2, 1, 2])
d.shape==torch.Size([1, 2, 1, 2])
9.3、torch.view()函数和
torch.resize_()函数
不知道大家发现没有在
上一篇
中torch.view()函数和torch.resize_()函数也可以实现增、降维的能力
但不推荐在实际中增、降维用torch.resize_()函数,因为它会会为Tensor自动分配新的内存空间,所以下面将示例torch.view()函数,而torch.resize_()函数使用方法基本一致可自行测试
示例:
import torch as t
a=t.linspace(-1,1,10)
b=a.view(10,1)
c=a.view(1,2,5)
d=c.view(5,2)
print("a.shape=={}\nb.shape=={}\nc.shape=={}\nd.shape=={}\n".format(a.shape,b.shape,c.shape,d.shape))
print("a=={}\nb=={}\nc=={}\nd=={}\n".format(a,b,c,d))
运行结果:
a.shape==torch.Size([10])
b.shape==torch.Size([10, 1])
c.shape==torch.Size([1, 2, 5])
d.shape==torch.Size([5, 2])
a==tensor([-1.0000, -0.7778, -0.5556, -0.3333, -0.1111, 0.1111, 0.3333, 0.5556,
0.7778, 1.0000])
b==tensor([[-1.0000],
[-0.7778],
[-0.5556],
[-0.3333],
[-0.1111],
[ 0.1111],
[ 0.3333],
[ 0.5556],
[ 0.7778],
[ 1.0000]])
c==tensor([[[-1.0000, -0.7778, -0.5556, -0.3333, -0.1111],
[ 0.1111, 0.3333, 0.5556, 0.7778, 1.0000]]])
d==tensor([[-1.0000, -0.7778],
[-0.5556, -0.3333],
[-0.1111, 0.1111],
[ 0.3333, 0.5556],
[ 0.7778, 1.0000]])
十、Tensor的索引
10.1、Tensor的一般索引(共享内存)
Tensor的索引与列表索引相似
import torch as t
a=t.arange(0,6).view(2,3)
print("a={}\na[0]={}\na[:,0]={}\na[:2]={}\na[:1,:1]={}\n".format(a,a[0],a[:,0],a[:2],a[:1,:1]))
运行结果:
a=tensor([[0, 1, 2],
[3, 4, 5]])
a[0]=tensor([0, 1, 2])
a[:,0]=tensor([0, 3])
a[:2]=tensor([[0, 1, 2],
[3, 4, 5]])
a[:1,:1]=tensor([[0]])
小结:可以看见上述示例中张量的索引方式为:a[Rows,Columns] ,这种方式对于三维等也是可以的,对于精准到一个单一元素可以加一参数,如:
import torch as t
a=t.arange(0,18).view(2,3,3)
print("a={}\na[0]={}\na[1,1,2]={}\na[1,2,0]={}\na[:1,:1]={}\n".format(a,a[0],a[1,1,2],a[1,2,0],a[:1,:1]))
运行结果:
a=tensor([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]]])
a[0]=tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
a[1,1,2]=14
a[1,2,0]=15
a[:1,:1]=tensor([[[0, 1, 2]]])
小结:由上面的例子可以看见,对于三维张量索引时,a[Rows,Columns,index],不一样的就是此时只a[Rows,Columns]得到的是一个一维张量而不是一个元素,所以再加一个元素的索引就可以达到单一元素,四维张量也是类似
10.2、Tensor的高级索引(不共享内存)
import torch as t
a=t.arange(0,18).view(2,3,3)
print("a={}\na[[0,1],...]={}\na[[1,0],[1,2],[2,2]]={}\na[[0,1,1],[2],[1]]={}\n".format(a,a[[0,1],...],a[[1,0],[1,2],[2,2]],a[[0,1,1],[2],[1]]))
运行结果:
a=tensor([[[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]]])
a[[0,1],…]=tensor([[[ 0, 1, 2], //##相当于a[0] and a[1] 即输出第一、二行
[ 3, 4, 5],
[ 6, 7, 8]],
[[ 9, 10, 11],
[12, 13, 14],
[15, 16, 17]]])
a[[1,0],[1,2],[2,2]]=tensor([14, 8]) //##相当于a[1,1,2] and a[0,2,2]
a[[0,1,1],[2],[1]]=tensor([ 7, 16, 16]) //##相当于a[0,2,1] and a[1,2,1] and a[1,2,1]
理解辅助:
由上图可见,一个三维张量
行 是一个二维张量,列是一个一维张量,那么index就是这个一维张量里面的元素啦!小结:一维索引一个参数,二维索引两个参数,三维索引三个参数

小技巧:什么是共享内存?
python列表的共享内存:
有python编程基础的朋友应该都看过下面这个例子:
a=[1,2,3,4,5,6]
b=a
b[1]=10
a
[1, 10, 3, 4, 5, 6]
由上面的例子中我们不难看出来,python列表中将一个已经存在的列表(a)赋给另一个列表(b)得出列表(b)是和原列表()共用一块内存的,共用即说明这
两个列表无论是修改哪一个的元素值,另一个也会随着变化
,就比如上面的列表a,b,改变b的值a也会变,同样改变a,b也变,大家可以之行测试一下
张量的一般索引或高级索引得出的张量是否共享内存:
直接上例子:
import torch as t
a=t.arange(0,9).view(3,3)
b=a[1]
c=a[[1],...]
print("未改变前a:\n{}".format(a))
b[0]=100
print("改变一般索引得出张量b的值,此时a:\n{}".format(a))
c[0]=1000
print("改变一般索引得出张量c的值,此时a:\n{}".format(a))运行结果:
未改变前a:
tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
改变一般索引得出张量b的值,此时a:
tensor([[ 0, 1, 2],
[100, 4, 5],
[ 6, 7, 8]])
改变一般索引得出张量c的值,此时a:
tensor([[ 0, 1, 2],
[100, 4, 5],
[ 6, 7, 8]])
可见改变张量b时张量a随着改变,而改变c时a保持原来的值,即
张量的一般索引与原张量共享内存,而张量的高级索引与原张量一般不共享内存
划重点:共享内存的两个列表一般内存地址相同,而共享内存的两个张量内存地址一般不相同
十一、Tensor梯度裁剪
torch.clamp(tensor,min,max,out=None)函数:
逐个比对tensor里面的元素,当tensor的一个元素<min,返回min
当 min<= tensor的一个元素 <=max,返回tensor的对应元素
当tensor的一个元素>max,返回max
示例如下:
import torch as t
a=t.arange(0,6).view(2,3)
b=t.clamp(a,3)
c=t.clamp(a,2,5)
print("a={}\nb={}\nc={}\n".format(a,b,c))
运行结果:
a=tensor([[0, 1, 2],
[3, 4, 5]])
b=tensor([[3, 3, 3],
[3, 4, 5]])
c=tensor([[2, 2, 2],
[3, 4, 5]])




![[图解]建模相关的基础知识-19](https://img-blog.csdnimg.cn/direct/6c5b6ec4beb94e898d6933f8493dbc0d.png)