目录
一、背景与动机
二、卖点与创新
三、几个问题
四、具体是如何做的
1、更多、优质的数据,更大的模型
2、大数据量,大模型使得zero-shot成为可能
3、使用prompt做下游任务
五、一些资料
一、背景与动机
基于 Transformer 解码器的 GPT-1 证明了在特定的自然语言理解任务 (如文档分类等) 的标注数据较少的情况下,通过充分利用好大量的无标注的数据,也能取得很强的性能。几个月之后,基于 Transformer 编码器的 BERT 性能赶超了 GPT-1。
GPT-2 希望
构建更大的数据集和模型,同时在 Zero-shot 的多任务学习场景中展示出不错的性能。
说白了还是为了解决模型泛化性问题。
GPT1 的 “pre-training + supervised finetuning” 的这一范式:
- 虽然借助预训练这一步提升性能,但是本质上还是需要有监督的 finetuning 才能使得模型执行下游任务。
- 需要在下游任务上面有标注的数据。当我们只有很少量的可用数据 (即 Zero-shot 的情况下) 时就不再使用了。
二、卖点与创新
- Zero-shot
- GPT-2
本质上还是一个语言模型
,但是不一样的是,它证明了语言模型可以在 Zero-shot 的情况下执行下游任务,也就是说,GPT-2 在做下游任务的时候可以无需任何标注的信息,也无需任何参数或架构的修改。
个人理解,GPT-2本身做的是GPT-1中的预训练,但是在一个更大的数据集上,用更大的模型通过自监督的方式学到了任务无关的特性。
三、几个问题
- 为什么是zero-shot?
- Zero-Shot 情况下怎么让模型做下游任务?
四、具体是如何做的
1、更多、优质的数据,更大的模型
数据:
WebText数据集,一个包含了4500万个链接的文本数据集。经过重复数据删除和一些基于启发式的清理后,它包含略多于800万个文档,总文本容量为 40GB。
模型:
GPT-2 的模型在 GPT 的基础上做了一些改进,如下:
- Layer Normalization 移动到了每个 Sub-Block 的输入部分,在每个 Self-Attention 之后额外添加了一个 Layer Normalization,最终顺序是:LN, Self-Attention , LN。
- 采用一种改进的初始化方法,该方法考虑了残差路径与模型深度的累积。在初始化时将 residual layers 的权重按
的因子进行缩放,其中
是 residual layers 的数量。 - 字典大小设置为50257。
- 无监督预训练可看到的上下文的 context 由512扩展为1024。
- Batch Size 大小调整为512。
**2、
大数据量,大模型使得zero-shot成为可能。**
GPT-2 方法的核心是语言建模。
大规模无监督训练过程使得模型学习到了任务相关的信息。
在GPT-1中,第一阶段是无监督预训练过程,训练的方法是让 GPT “预测未来”。具体而言,假设我们无标记的语料库里面有一句话是
,GPT 的模型参数是 Θ ,作者设计了下面这个目标函数来最大化
:
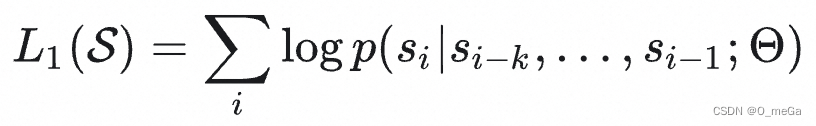
式中,
是上下文窗口的大小。这个式子的含义是让模型看到前面
个词,然后预测下一个词是什么,再根据真实的下一个词来计算误差,并使用随机梯度下降来训练。上式的本质是希望模型能够根据前
个词更好地预测下一个词。
这个式子其实做的事情是让下式尽量大:
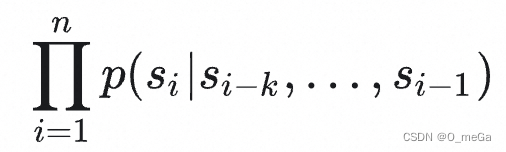
语言模型的这个式子可以表示为:
,也就是在给定输入的情况下,最大化已知输出的概率。
注意到,GPT 之前在做这一步的时候,是在自然的文本上面训练的。自然文本的特点是,它里面有任务相关的信息,但是呢,这个信息通常是蕴含在文本里面的,比如下面这段话 (来自 GPT-2 论文):
"I’m not the cleverest man in the world, but like they say in French:
Je ne suis pas un imbecile [I’m not a fool].
In a now-deleted post from Aug. 16, Soheil Eid, Tory candidate in the riding of Joliette, wrote in French:
“Mentez mentez, il en restera toujours quelque chose,”
which translates as,
“Lie lie and something will always remain.”
"I hate the word
‘perfume,’
" Burr says. 'It’s somewhat better in French:
‘parfum.’
If listened carefully at 29:55, a conversation can be heard between two guys in French:
“-Comment on fait pour aller de l’autre cot ́e? -Quel autre cot ́e?”
, which means
“- How do you get to the other side? - What side?”
. If this sounds like a bit of a stretch, consider this question in French:
As-tu aller au cin ́ema?,
or
Did you go to the movies?
, which literally translates as Have-you to go to movies/theater?
“Brevet Sans Garantie Du Gouvernement”
, translated to English:
“Patented without government warranty”
.
上面这段文本中,“Mentez mentez, il en restera toujours quelque chose,” 是法语句子,“Lie lie and something will always remain.” 是英文句子,而我们在无监督训练语言模型的时候,并没有告诉模型要做 translation 的任务,但是我们的文本中却有 which translates as 这样的字样。换句话说,这一与
具体下游任务任务相关的信息
,竟然可以通过
具体下游任务任务无关的无监督预训练过程
学习到。
3、使用prompt做下游任务
因为在 Zero-Shot 的任务设置下,没有这些带有开始符和结束符的文本给模型训练了,所以这时候做下游任务的时候也就不适合再给模型看开始符和结束符了。
大规模无监督训练过程学习到了任务相关的信息
。作者认为:比如下游任务是
英文翻译法文
,那么如果模型在无监督预训练的过程中看过了引用的那一大段的文字 (这句话
“Mentez mentez, il en restera toujours quelque chose,”
which translates as,
“Lie lie and something will always remain.”
是训练的语料),那么模型就能够学会 (translate to french, english text, french text) 这样的下游任务。
也就是说,原则上,通过大量的语料训练,语言建模能够学习到一系列下游任务,而不需要明确的监督信息。为什么可以这么讲呢?因为作者认为:下游任务 (有监督训练) 可以视为预训练过程 (无监督训练) 的一个子集。无监督目标的全局最优解也是有监督训练的全局最优解。当预训练规模足够大时,把无监督的任务训练好了,有监督的下游任务即不再需要额外训练,就是所谓的 “Zero-Shot”。
所以下面的问题就变成了:在实践中,我们如何能够优化无监督预训练过程以达到收敛。初步实验证实,足够大的语言模型能够在无监督的预训练过程之后做下游任务,但学习速度比显式监督方法慢得多。
那么最后一个问题就是具体怎么去做下游任务呢?以英文翻译法文为例,我们需要在下游任务时预先告诉模型 “translate English to French”,即给模型一个提示 (Prompt)。
五、一些资料
[LLM 系列超详细解读 (二):GPT-2:GPT 在零样本多任务学习的探索 - 知乎
本系列已授权极市平台,未经允许不得二次转载,如有需要请私信作者。专栏目录科技猛兽:多模态大模型超详细解读 (目录)本文目录1 GPT-2:GPT 在零样本多任务学习的探索 (来自 OpenAI) 1.1 背景和动机 1.2 大规模无…

https://zhuanlan.zhihu.com/p/616975731](/ “LLM 系列超详细解读 (二):GPT-2:GPT 在零样本多任务学习的探索 - 知乎”)