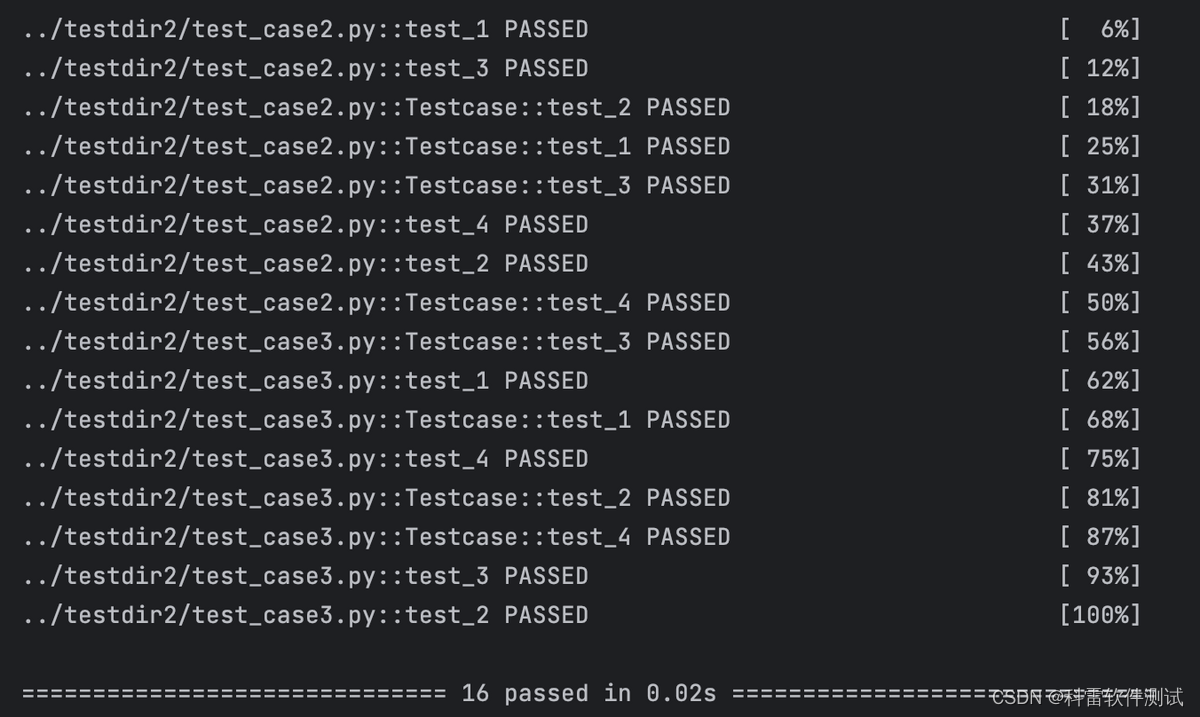
获取本文论文原文PDF,请在公众号【AI论文解读】留言:论文解读

引言:AI模型的奥林匹克级评测
评估和比较不同AI模型的性能始终是一个核心话题。随着技术的不断进步,这些模型在处理复杂任务的能力上有了显著的提升。为了更精确地衡量这些先进模型的能力,Huang等人在2024年引入了一个全新的、类似奥林匹克的多学科、多模态评测平台——OlympicArena。这一平台设计了包括11,163个双语问题,涵盖文本和图像交错的模态,跨越七个常见学科和62个国际奥林匹克竞赛,严格检查数据泄露问题,旨在推动AI在认知推理方面的极限。
在这一背景下,本文将探讨最新发布的AI模型——包括“Claude-3.5-Sonnet (Anthropic, 2024a)”、“Gemini-1.5-Pro (Reid et al., 2024)”和“GPT-4o”——在OlympicArena上的表现。通过引入奥林匹克奖牌榜的方式,我们不仅比较了这些模型在不同学科的表现,还通过细粒度的分析揭示了它们在不同类型的逻辑和视觉推理能力上的优势和不足。
这种全面而深入的评测方法为研究人员和开发者提供了一个清晰且具有竞争性的框架,帮助他们更好地理解不同模型的强项和弱点。通过这样的奥林匹克级评测,我们可以更准确地识别出在各个学术领域中表现最为出色的AI模型,从而推动人工智能技术在更广泛领域的应用和发展。
OlympicArena基准介绍
OlympicArena是由Huang等人在2024年提出的一个全新的、具有挑战性的人工智能评测基准。这一基准测试旨在通过模拟奥林匹克级别的多学科、多模态竞赛环境,推动人工智能在认知推理能力上的极限。OlympicArena包含了11,163个双语问题,这些问题涵盖了文本只读和文本-图像交错的模态,覆盖了七个常见学科和62个国际奥林匹克竞赛项目。
1. 数据集的设计与挑战
OlympicArena的设计严格检查了数据泄露问题,确保了测试的公正性和有效性。这个基准测试不仅要求模型在多种类型的问题上表现出高水平的理解和推理能力,还要求模型能够处理复杂的、多模态的输入信息。
2. 测试的设置
在OlympicArena的测试设置中,使用了测试数据集的分割(test split),并且没有公开答案,以防止数据泄露。所有的评估都可以通过规则匹配来执行,不需要基于模型的评估。此外,为了保持问题的原始结构,测试时直接使用文本输入,不使用图像标题作为图像的文本表达。
3. 竞争者和评估方法
OlympicArena评估了多种开源和专有的大型多模态模型(LMMs)和大型语言模型(LLMs)。这些模型包括但不限于OpenAI的GPT系列、Anthropic的Claude系列以及其他一些团队开发的模型。评估方法包括精确度评估非编程任务和无偏pass@k评估编程任务。
4. 奖牌表和细粒度分析
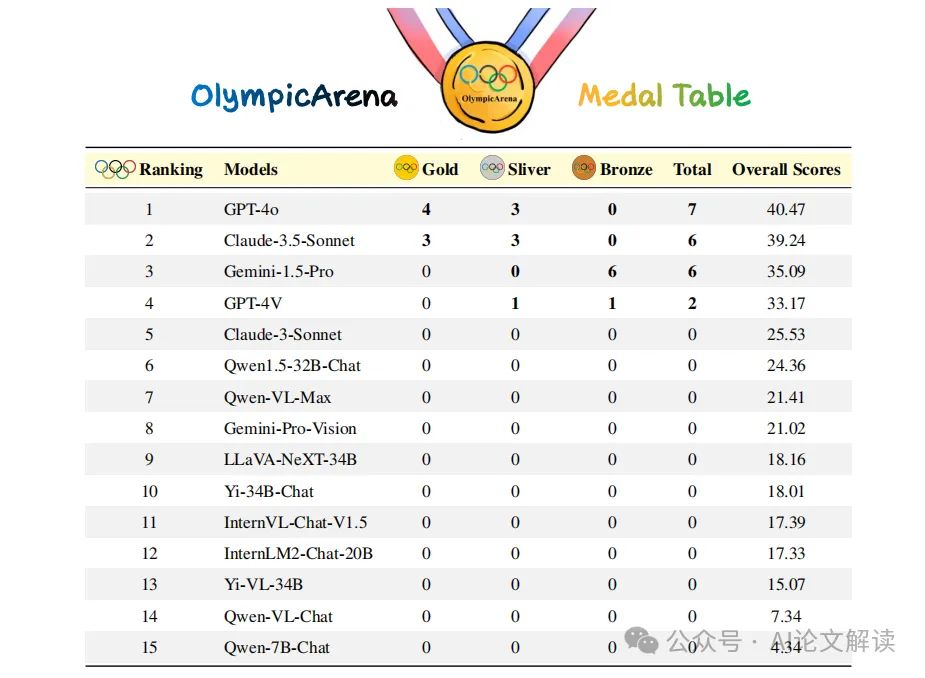
OlympicArena还创新性地引入了奥林匹克奖牌表(OlympicArena Medal Table),这是一种类似于奥运会的奖牌系统,用于评估AI模型在各个学科领域的表现。模型根据在任何给定学科中获得的前三高分获得奖牌。此外,还进行了关于不同学科、不同推理类型、不同语言和不同模态的细粒度分析,以深入理解各模型的能力和局限性。
通过这些详尽的测试和评估,OlympicArena旨在提供一个全面、竞争性的框架,帮助研究人员和开发者更好地理解不同模型的强项和弱点,从而推动人工智能技术的发展和应用。
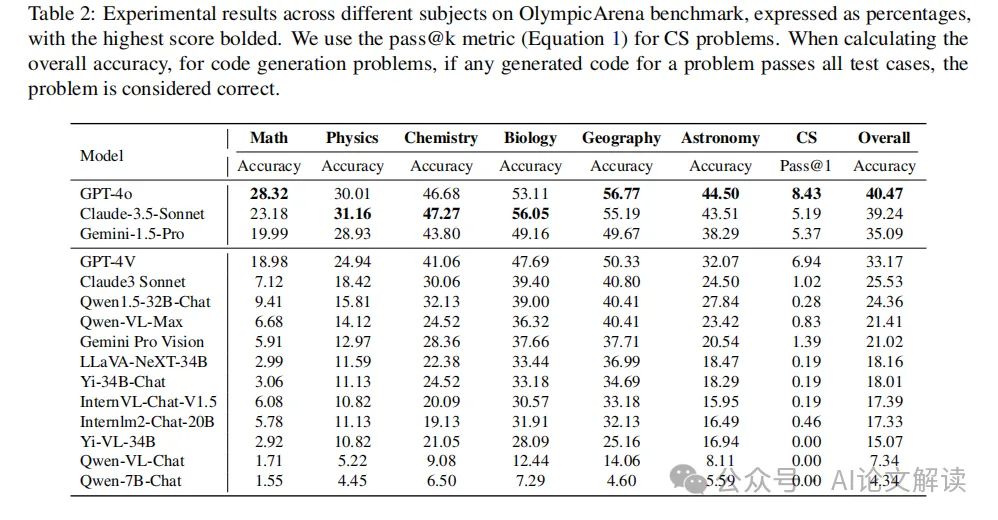
模型比较与评估方法
在这个章节中,我们将探讨如何比较和评估不同的人工智能模型。我们将特别关注最近发布的模型:“Claude-3.5- Sonnet (Anthropic, 2024a),” “Gemini-1.5-Pro (Reid et al., 2024),” 和 “GPT-4o”。为了进行全面的性能评估,我们将使用OlympicArena(Huang et al., 2024)提出的奥运会奖牌表方法,这是一种创新的排名机制,专门设计用来评估AI模型在各个学科领域的表现。
1. 评估指标
所有问题都可以使用基于规则的匹配进行评估,因此我们使用准确性作为非编程任务的评估指标,对于编程任务,我们使用无偏的pass@k作为评估指标,其中k = 1,n = 5,c表示通过所有测试用例的正确样本数。
2. OlympicArena奖牌表
OlympicArena奖牌表类似于奥运会中使用的奖牌系统,它是一种专门设计用来评估AI模型在各个学科领域表现的排名机制。该表为在任何给定学科中取得前三名成绩的模型颁发奖牌,从而提供了一个清晰而有竞争力的框架来比较不同的模型。具体来说,我们首先根据金牌数量对AI模型进行排名,如果金牌数量相同,则根据总分进行排名。这提供了一种直观的方式来识别在不同学科领域中的领先模型,使研究人员和开发人员更容易理解不同模型的优点和缺点。
3. 细粒度评估
我们根据不同的学科、模态、语言以及不同类型的逻辑和视觉推理能力进行细粒度评估。
4. 结果和分析
我们发现,新发布的Claude-3.5-Sonnet非常强大,其表现几乎与GPT-4o相当。同时,新发布的Gemini-1.5-Pro也展示出了相当的实力,超过了GPT-4V。此外,根据OlympicArena奖牌表,我们可以观察到GPT-4o, Claude-3.5-Sonnet, 和Gemini-1.5-Pro是排名前三的模型。
5. 细粒度分析
我们对各个模型在不同学科、推理类型、语言类型和模态下的表现进行了细粒度分析。例如,GPT-4o在传统的演绎和归纳推理任务,特别是数学和计算机科学方面,表现出优越的能力,超过了Claude-3.5-Sonnet 5%以上的数学和3%的计算机科学。另一方面,Claude-3.5-Sonnet在物理、化学和生物学等科目中表现出色,尤其是在生物学方面,它超过了GPT-4o 3%。
这些观察结果表明,即使是目前最强大的模型,在文本任务上的准确性也高于多模态任务。虽然差距不大,但这表明模型在利用多模态信息处理复杂推理问题方面还有很大的改进空间。
细粒度分析
在本章节中,我们将深入探讨最新的AI模型在多个维度上的性能表现,包括学科细分、推理类型、视觉推理能力、语言类型以及模态分析。通过这一细粒度分析,我们旨在揭示不同模型在处理复杂问题时的优势和局限性。
1. 学科细分
在学科细分方面,我们比较了GPT-4o、Claude-3.5-Sonnet和Gemini-1.5-Pro三个模型在数学、计算机科学、物理、化学和生物学等领域的表现。GPT-4o在数学和计算机科学领域展现出了卓越的能力,尤其是在数学领域,其性能超过了Claude-3.5-Sonnet超过5%,在计算机科学领域也超过了3%。相反,Claude-3.5-Sonnet在物理、化学和生物学等领域表现更为出色,特别是在生物学领域,它超过了GPT-4o 3%的表现。
2. 推理类型
在推理类型方面,GPT系列模型在传统的数学推理和编程能力方面表现突出,这表明GPT模型经过了严格的训练,以处理需要强大演绎推理和算法思维的任务。而在需要知识与推理结合的学科,如物理、化学和生物学方面,Claude-3.5-Sonnet和Gemini-1.5-Pro展现出了竞争性或更优的性能。
3. 视觉推理能力
在视觉推理能力方面,Claude-3.5-Sonnet在模式识别和图表解读方面领先于GPT-4o,显示出其在识别模式和解释图表方面的强大能力。两个模型在符号解释方面表现相当,表明它们在理解和处理符号信息方面具有可比的能力。然而,GPT-4o在空间推理和比较可视化方面的表现优于Claude-3.5-Sonnet,展示了其在理解空间关系和比较视觉数据方面的优势。
4. 语言类型
在语言类型方面,尽管模型主要训练在英语数据上,但包括一些中文数据并具有跨语言泛化能力。中文问题的难度比英语问题更具挑战性,尤其是在物理和化学等学科中,中文奥林匹克问题更为困难。然而,一些在中国开发或在支持中文的基础模型上进行微调的模型在中文场景中的表现优于英文场景。
5. 模态分析
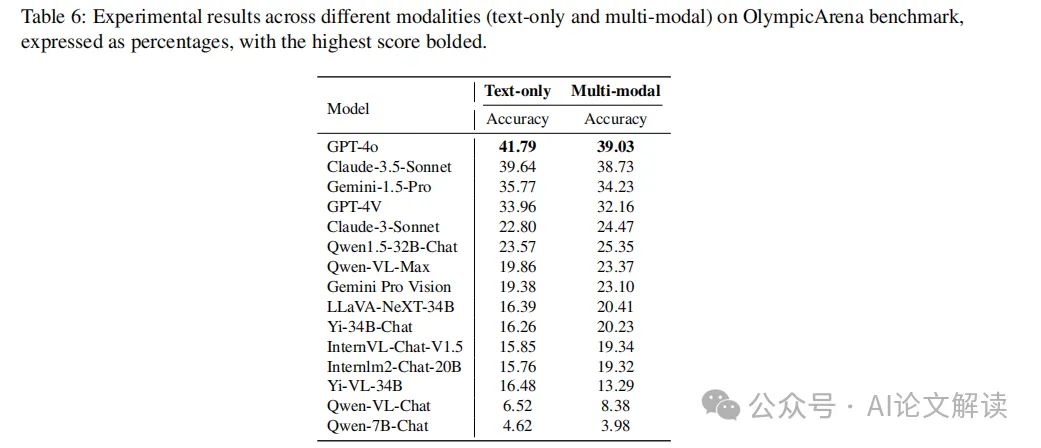
在模态分析方面,GPT-4o在文本和多模态任务中均表现优异,特别是在文本任务中表现更为突出。这表明,尽管目前最强大的模型在处理复杂推理问题时能够利用多模态信息,但在文本任务中的准确性更高,表明在提高模型利用多模态信息的能力方面仍有很大的改进空间。
通过这一细粒度分析,我们不仅能够更深入地理解不同AI模型在各个领域的性能,还能够揭示它们在处理复杂问题时的优势和局限性。这为未来模型的开发和优化提供了宝贵的见解。

模型性能的主要发现与讨论
在本章节中,我们将详细讨论最新的AI模型在OlympicArena基准测试中的表现。我们将重点关注最新发布的模型:“Claude-3.5- Sonnet (Anthropic, 2024a),” “Gemini-1.5-Pro (Reid et al., 2024),” 和 “GPT-4o。” 我们将使用奥运会奖牌表的方法来对AI模型进行排名,这种方法基于模型在各个学科中的综合表现。
1. 总体表现
根据实验结果,新发布的Claude-3.5-Sonnet表现强大,几乎与GPT-4o相当。同时,新发布的Gemini-1.5-Pro也展示了相当的实力,超过了GPT-4V。根据OlympicArena奖牌表(见表1),如果一个模型在任何学科中取得前三名的成绩,它就会获得一枚奖牌。我们可以观察到GPT-4o,Claude-3.5-Sonnet,和Gemini-1.5-Pro是排名前三的模型。
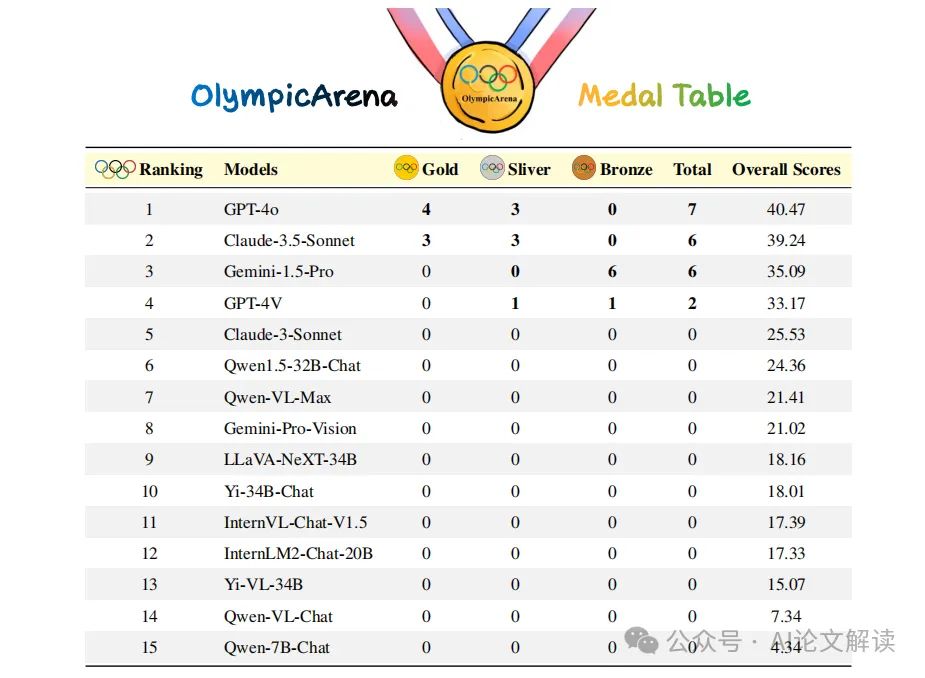
2. 针对学科的细粒度分析
虽然GPT-4o和Claude-3.5-Sonnet在各学科的总体表现相似,但每个模型都有其特定的优势。GPT-4o在传统的演绎和归纳推理任务中表现出优越的能力,特别是在数学和计算机科学方面,超过Claude-3.5-Sonnet超过5%和3%。另一方面,Claude-3.5-Sonnet在物理,化学和生物学等科目中表现出色,特别是在生物学方面,它超过了GPT-4o 3%。
3. 针对推理类型的细粒度分析
OpenAI的GPT系列在传统的数学推理和编码能力方面表现出色。这种在这两个学科的优越表现表明,GPT模型已经经过严格的训练,以处理需要强大的演绎推理和算法思维的任务。相反,当涉及到需要知识与推理的整合的学科,如物理,化学和生物学,其他模型如Claude-3.5-Sonnet和Gemini-1.5-Pro表现出有竞争力或优越的表现。
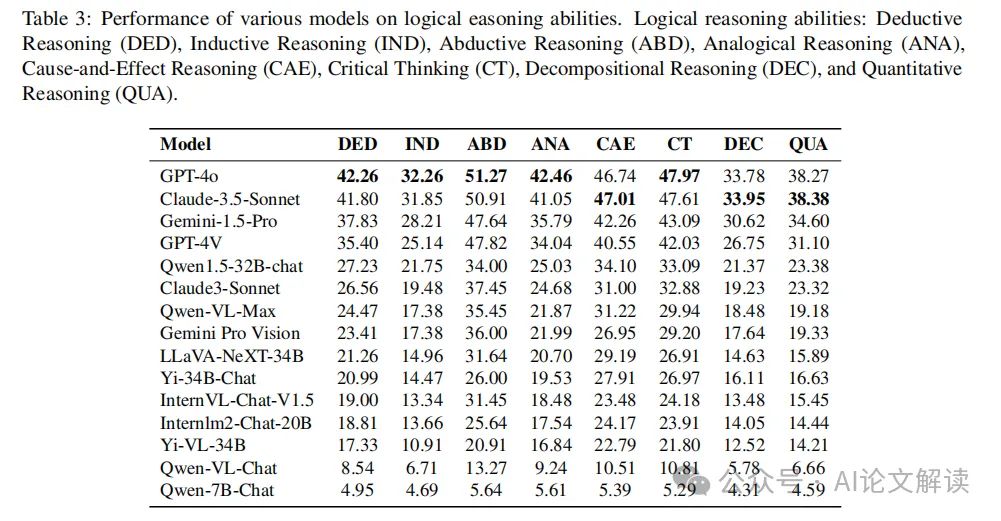
4. 针对语言类型的细粒度分析
我们发现,这些强大的模型在英语问题上的表现仍然优于中文问题,并且在多模态能力方面还有很大的改进空间。然而,我们也发现,一些在中国开发或在支持中文的基础模型上进行微调的模型在中文场景中的表现优于英文场景。这表明,优化模型以适应中文数据,以及全球更多的语言,仍然需要大量的关注。
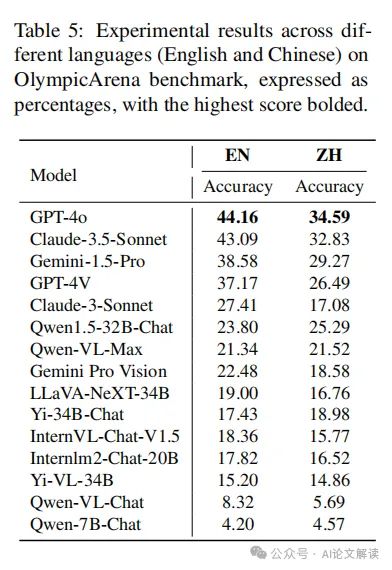
5. 针对模态的细粒度分析
如表6所示,GPT-4o在文本只读和多模态任务中都优于Claude-3.5-Sonnet,特别是在文本只读问题中表现出色。这些观察结果表明,即使是目前最强大的模型,也在文本只读任务中比多模态任务中的准确率更高。虽然差距不大,但这表明模型在利用多模态信息处理复杂推理问题方面还有很大的改进空间。
通过理解这些细微差别,不仅有助于开发更专业和多功能的模型,还强调了持续评估和改进模型架构的重要性,以更好地满足不同学术和专业领域的多样化需求。
论文地址:https://arxiv.org/pdf/2406.16772
代码:https://github.com/GAIR-NLP/OlympicArena