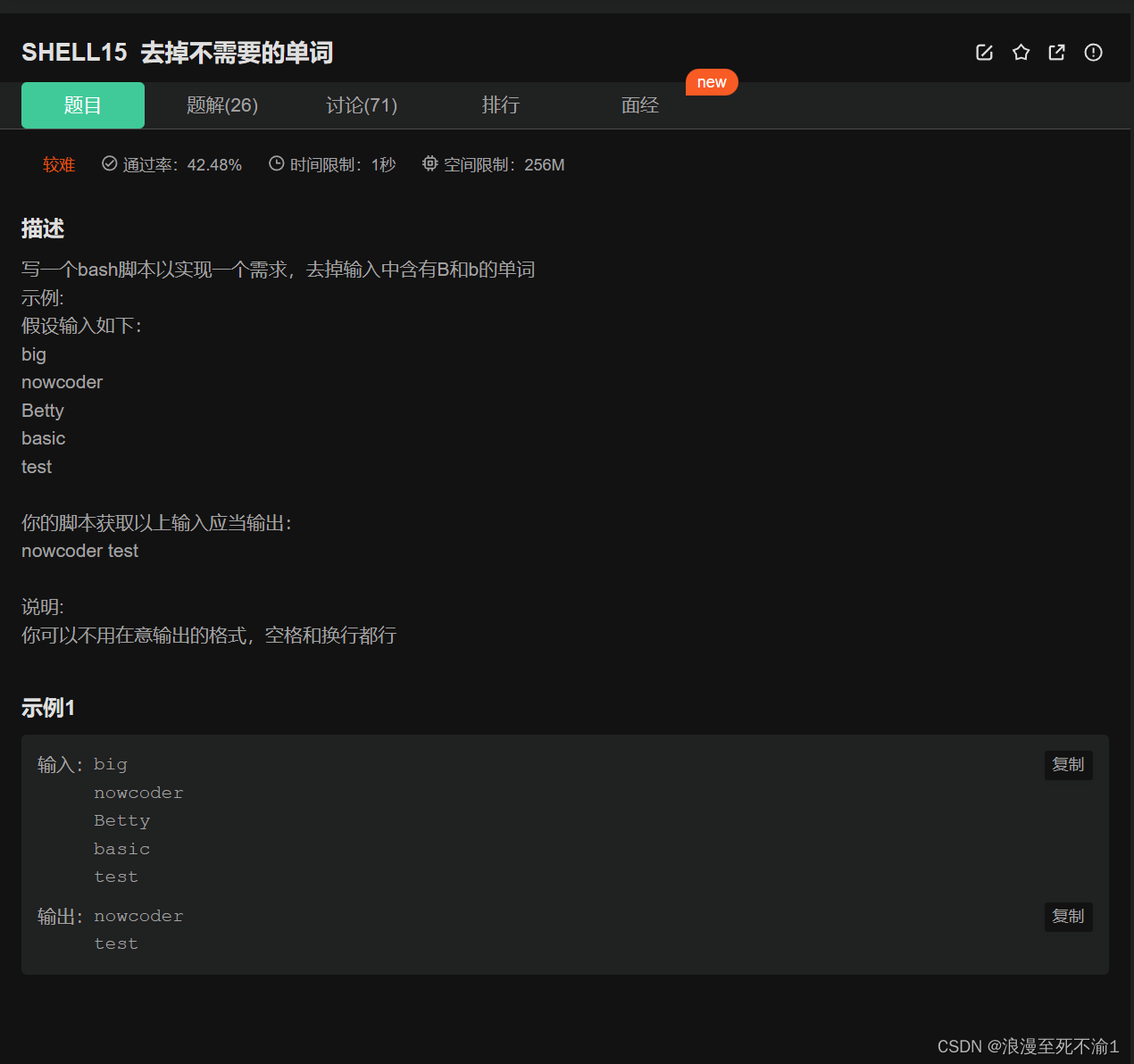
基础查询
1、查询用户信息,仅显示用户的姓名与手机号,用中文显示列名。中文显示姓名列与手机号列
SELECT user_id AS '编号', phone AS '电话' FROM user;
2. 根据订购表进行模糊查询,模糊查询需要可以走索引,需要给出explain语句。使用explain测试给出的查询语句,需要显示走了索引查询。
CREATE INDEX idx_order_id ON `order`(order_id); 
不能用模糊查询的符号作为查询的开头,否则不走索引。
EXPLAIN SELECT * FROM `order` WHERE order_id LIKE '小%'; 
可以看到已经走了索引了。
3.统计用户订单信息,查询所有用户的下单数量,并进行倒序排列。使用聚合函数查询处所有用户的订单数量,倒序排列结果
SELECT user_id, COUNT(order_id) AS '订购数量'
FROM `order`
GROUP BY user_id
ORDER BY `订购数量` DESC;
复杂查询
1.查询用户的基本信息,订单信息。正确显示用户信息,正确显示订单信息,正确进行多表联合查询
u.user_id, -- 选择用户的用户IDu.username, -- 选择用户名u.age,-- 选择年龄u.sex,-- 选择性别u.phone, -- 选择电话u.email, -- 选择邮箱uo.quantity,uo.book_id
FROM user u -- 从用户表中选择数据
JOIN `order` uo ON u.user_id = uo.user_id; -- 使用JOIN连接用户表和订单表,连接条件是两个表中的user_id相同 
2.查看订单中下单最多的书籍。正确使用聚合函数,正确使用子查询,正确显示结果
SELECT pt.book_id -- 选择书籍名称
FROM `books` p -- 从书籍表中选择数据
JOIN `order` pt ON p.book_id = pt.book_id -- 使用JOIN连接书籍表和订单表,连接条件是书籍表中的book_id与订单表中的book_id相同
JOIN (SELECT book_id, -- 子查询中选择书籍编号IDCOUNT(order_id) AS order_count -- 子查询中对每个书籍ID的订单ID进行计数,并命名为order_countFROM `order` -- 子查询从订单表中选择数据GROUP BY book_id -- 按书籍ID进行分组ORDER BY order_count DESC -- 按订单数量降序排列LIMIT 3) oi ON p.book_id = oi.book_id; -- 子查询的结果作为临时表oi,与产品表通过book_id进行连接 
3.查询 订单中购买书籍最多的数量,和库存中剩余书籍总数量
SELECT o.order_id, -- 选择订单ID o.quantity, -- 选择订单数量 uo.stock_qty -- 选择书籍库存
FROM orders o -- 从订单表中选择数据
JOIN ( SELECT order_id, -- 子查询中选择订单ID SUM(quantity) AS total_quantity -- 子查询中对每个订单的商品数量进行求和,并命名为total_quantity FROM orders -- 子查询从订单表中选择数据 GROUP BY order_id -- 按订单ID进行分组(如果您想按用户分组,应使用user_id) ORDER BY total_quantity DESC -- 按总订单数量降序排列 LIMIT 1 -- 只选择总订单数量最多的那个订单 ) o_max ON o.order_id = o_max.order_id -- 子查询的结果作为临时表o_max,与订单表通过order_id进行连接
JOIN stock uo ON uo.stock_id = o.stock_id; -- 假设库存表有一个stock_id字段与订单表的stock_id字段关联