字典树
1.字典树简介
字典树 ( Trie 树 ) 又称单词查找树,
是一种用于在字符串集合中高效地存储和查找字符串的树形数据结构。
我们首先通过一张图来理解字典树的结构:

我们假定结点的顺序按照图中给定的顺序进行编号,容易发现,在一棵给定的树上,每一条树边代表一个字母。那么我们可以知道:从根节点出发,到达某个指定的结点的路径可以构成一个字符串。
一个例子: 1 → 4 → 8 → 13 ⟹ c a a 1\to4\to 8\to 13 \Longrightarrow caa 1→4→8→13⟹caa

2.应用场景
维护一个 字符串集合 ,支持两种操作:
向集合中插入一个字符串 xx;
询问一个字符串 xx 及其作为前缀在集合中出现了多少次。
例如:有字符串集合 { “abc” , “acwing” , “hhhh”}
- 插入字符串 “abc” ==> 集合 { “abc” , “abc” , “acwing” , “hhhh”}
- 查询字符串 “abc” 出现的次数:2 次。
Trie 的结构非常好懂,我们用 δ ( u , c ) \delta(u,c) δ(u,c)表示结点 u u u 的 c c c 字符指向的下一个结点,或着说是结点 u u u 代表的字符串后面添加一个字符 c c c 形成的字符串的结点。
有时需要标记插入进 Trie 的是哪些字符串,每次插入完成时在这个字符串所代表的节点处打上标记即可。
3.具体操作
(1) 插入
基本思路:将字符串逐个拆分成单个字符,从第一个字符开始与Trie 树的根结点开始的子结点比对,若有结点具有相同的字符,则以同样的方式对比下一个字符与该结点的子结点 。
那么插入操作就应该分为以下的步骤:
- 首先我们需要记录根结点的编号,初始化为0;
- 从左到右扫描这个单词,每次计算关系编号 i d id id ;
- 如果之前没有从 r o o t root root 到 i d id id 的前缀,则插入该编号(需要预先在声明计数变量,对一种编号进行记录);
- 执行 r o o t = t r e e [ r o o t ] [ i d ] r o o t = t r e e [ r o o t ] [ i d ] root=tree[root][id] ,表示顺着字典树继续向下走。
注意:在插入完字符串之后,要给(末尾的)结点加上结束标记。

(2) 查找
与插入操作的原理基本相同,将需要查询的字符串逐个拆分成单个字符,逐个与 Trie 树中的结点比较,直至发现 Trie 树中不存在的字符,或要查询的字符串的各个字符都比较完成 。
-
对于发现 Trie 树中不存在的字符,一旦发现,就能确定要查询的字符串不属于原集合。
-
对于要查询的字符串的各个字符都比较完成,则存在两种情况:
① 要查询的字符的确属于集合;
② 要查询的字符是集合中某个字符串的前缀。
此时就需要用到刚刚打上的
结束标记来判断了。
4.代码实现
P8306 【模板】字典树 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
初始化:
int son[N][70]; // 存储每个结点的所有儿子结点
int cnt[N]; // 记录以这个结点结尾的单词有多少个, 作为字符串结束标记
int idx; // 存储当前已经使用到的结点的下标
// 下标是 0 的结点,既是根节点,又是空结点
map<char,int>mp;//处理字符
char str[N]; // 存储输入的字符串void init_char() {for (char i = 'a'; i <= 'z'; ++i) mp[i] = ++idx;for (char i = 'A'; i <= 'Z'; ++i) mp[i] = ++idx;for (char i = '0'; i <= '9'; ++i) mp[i] = ++idx;
}void init_son() {for (int i = 0; i <= tot; ++i) {cnt[i] = 0;for (int j = 0; j <= 62; ++j) {son[i][j]=0;}}
}
插入
void insert(string t) {int p = 0;for (auto x: t) {if (!son[p][mp[x]]) son[p][mp[x]] = ++idx;p = son[p][mp[x]];cnt[p] ++;}
}
查找
int query(string t) {int p = 0;for (auto x: t) {if (!son[p][mp[x]]) return 0;p = son[p][mp[x]];}return cnt[p];
}
AC代码:
#include <bits/stdc++.h>
using namespace std;
#define io ios::sync_with_stdio(false),cin.tie(0),cout.tie(0)
typedef long long ll;
//#define int ll
#define pb push_back
#define eb emplace_back
#define m_p make_pair
const int mod = 998244353;
#define mem(a,b) memset(a,b,sizeof a)
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 0x3f3f3f3f;
const int N = 3e6 + 50;
//__builtin_ctzll(x);后导0的个数
//__builtin_popcount计算二进制中1的个数int son[N][70]; // 存储每个结点的所有儿子结点
int cnt[N]; // 记录以这个结点结尾的单词有多少个, 作为字符串结束标记
int idx; // 存储当前已经使用到的结点的下标
// 下标是 0 的结点,既是根节点,又是空结点
map<char,int>mp;//处理字符
char str[N]; // 存储输入的字符串void init_char() {for (char i = 'a'; i <= 'z'; ++i) mp[i] = ++idx;for (char i = 'A'; i <= 'Z'; ++i) mp[i] = ++idx;for (char i = '0'; i <= '9'; ++i) mp[i] = ++idx;
}void init_son() {for (int i = 0; i <= idx; ++i) {cnt[i] = 0;for (int j = 0; j <= 62; ++j) {son[i][j] = 0;}}
}void insert(string t) {int p = 0;for (auto x: t) {if (!son[p][mp[x]]) son[p][mp[x]] = ++idx;p = son[p][mp[x]];cnt[p] ++;}
}int query(string t) {int p = 0;for (auto x: t) {if (!son[p][mp[x]]) return 0;p = son[p][mp[x]];}return cnt[p];
}void work() {int n, q; cin >> n >> q;init_son();idx = 0;for (int i = 1; i <= n; ++i) {string s; cin >> s;insert(s);}for (int i = 1; i <= q; ++i) {string t; cin >> t; cout << query(t) << '\n';}
}signed main() {io;int t = 1;init_char();cin >> t;while (t--) {work();}return 0;
}
课后练习:P2580 于是他错误的点名开始了 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
5.算法分析
Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
假设字符的种数有m个,有若干个长度为n的字符串构成了一个Trie树,则每个节点的出度为m(即每个节点的可能子节点数量为m),Trie树的高度为n。很明显我们浪费了大量的空间来存储字符,此时Trie树的最坏空间复杂度为 O ( m n ) O(m^n) O(mn)。
也正由于每个节点的出度为m,所以我们能够沿着树的一个个分支高效的向下逐个字符的查询,而不是遍历所有的字符串来查询,此时Trie树的最坏时间复杂度为O(n)。这正是空间换时间的体现,也是利用公共前缀降低查询时间开销的体现。
6.拓展
01trie
简化版trie,树边不再是一个字符,而是0或1作为二进制的一个位,可以理解为:每一个数写成二进制都是一个字符串,我们存数的时候把这个01字符串存下去,由高位到低位 = 由树根到叶节点。
[U109895 HDU4825]Xor Sum - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
对于每一个数字都可以二进制拆位,从高位到低位加入字典树。分析数组大小,最多有N个数,每个数最多不超过 2 32 2^{32} 232,拆位出来每个数最多是一个长度为32的链,最多有N*32个节点,每一个节点的子节点最多有2种状态即01。
查找异或时,贪心地去找,从高位到低位,如果该位上有异或为1的数选择该类一定是更优的,依次找到即可。
AC代码:
#include<bits/stdc++.h>
#define int long long
using namespace std;
const int N = 5e5;
int tree[N*32+10][3];
int cnt[N];
int idx;void insert_tr(int t){int p = 0;for(int bit = 32; bit >= 0;bit--){int u = (t >> bit) & 1ll;if(!tree[p][u]) tree[p][u] = ++idx;p = tree[p][u];}
}int querry_tr(int t){int ans = 0;int p = 0;for(int bit = 32; bit >= 0;bit--){int u = (t >> bit) & 1ll;if(tree[p][!u]){ans += (1ll << bit) * (!u);p = tree[p][!u];} else{ans += (1ll << bit) * (u);p = tree[p][u];} }return ans;
}
signed main(){ios::sync_with_stdio(false),cin.tie(0),cout.tie(0);int n,m;cin >> n >> m;int t;for(int i=0;i<n;i++){cin >> t;insert_tr(t);}for(int i=0;i<m;i++){cin >> t;cout << querry_tr(t) << '\n';}return 0;
}
可以尝试带删01trieProblem - 706D - Codeforces
第一周周赛团队赛Problem - 6955 (hdu.edu.cn)
*7.提提提提提高
P4735 最大异或和 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn)
每一次增加一个x,对所有后缀异或和都要修改一次,时间复杂度过大,考虑优化,把后缀和变成前缀和:
s [ 1 ] = a [ 1 ] s [ 2 ] = a [ 1 ] ⊕ a [ 2 ] s [ 3 ] = a [ 1 ] ⊕ a [ 2 ] ⊕ a [ 3 ] ⋯ s [ p − 1 ] ⊕ s [ n ] = a [ p ] ⊕ a [ p + 1 ] ⊕ ⋯ ⊕ a [ n ] \begin{align} s[1]& = a[1]\\ s[2]& = a[1] \oplus a[2]\\ s[3]& = a[1] \oplus a[2] \oplus a[3]\\ &\cdots \\ s[p - 1] \oplus s[n] & = a[p]\oplus a[p + 1] \oplus \cdots \oplus a[n] \end{align} s[1]s[2]s[3]s[p−1]⊕s[n]=a[1]=a[1]⊕a[2]=a[1]⊕a[2]⊕a[3]⋯=a[p]⊕a[p+1]⊕⋯⊕a[n]
此时查询变成了,在[l - 1, r - 1]内找一个p,使得 s [ p ] ⊕ s [ n ] ⊕ x s[p] \oplus s[n] \oplus x s[p]⊕s[n]⊕x 最大,而 s [ n ] ⊕ x s[n] \oplus x s[n]⊕x已经是一个定值。
如果我们不设置p在[l - 1, r - 1]的范围,就是一个简单的01trie,但是我们现在需要记录每一个数的位置版本,就需要让这个树可持久化。
可持久化字典树!!!
可持久化:
是一个重要的算法思想,结合
备份与函数式编程的思想。部分可持久化 (Partially Persistent):所有版本都可以访问,但是只有最新版本可以修改。
既然我们现在要记录所有历史版本,最直观的想法就是将每一个版本的 trie 都存储下来,当需要一个新的结点时,我们完全复制一个历史版本,然后再它上面完成操作。这样的做法,正确性是显然的,但是空间开销非常大。要减少存储空间,我们考虑将 trie 树上的一些“枝条”共用来减少空间上的浪费。
我们在每一个新的数字插入的时候创建一个新版本来做,而不是插入原来的版本,同时要记录新建的树的每个节点的版本号,然后完全复制历史版本上同等地位点的其他儿子信息。
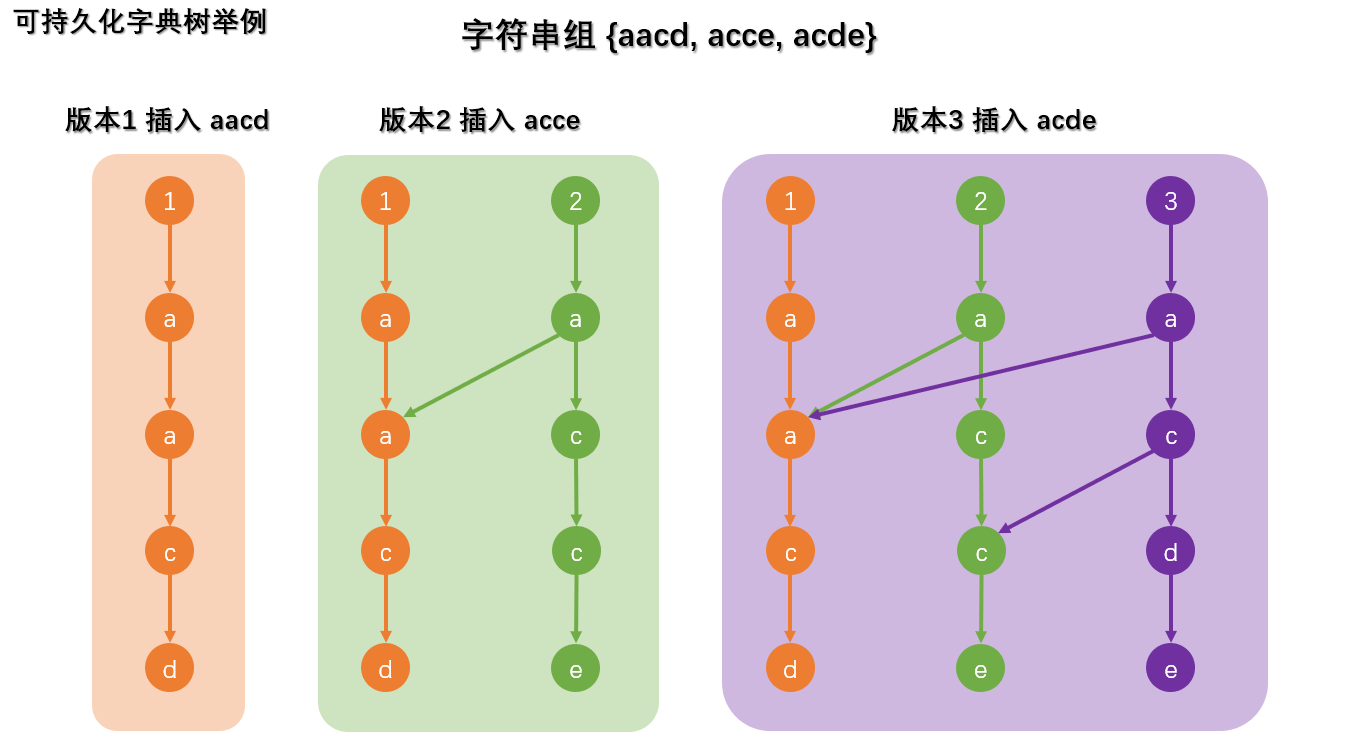
在上图中,从一个版本起点开始,遍历整棵树,一定能获得该版本及之前的所有串,并且空间大大减少。
大部分的可持久化 Trie 题中,Trie 都是以01-Trie的形式出现的,所以我们在这里只学习可持久化01trie的写法。
回到题目!
需要开的变量:
int son[N * 25][2];//trie
int root[N * 25];//根节点编号,root[x] 表示第x版本的根节点编号
int maxid[N * 25];//节点的版本号,maxid[x] 表示编号为x的节点的版本
int s[N], a[N];//前缀和,原数组
int idx = 0;//节点编号
插入:
void insert(int i, int k, int pre, int now) { //当前版本号,当前位数,上一个版本在当前状态的节点编号,当前版本在当前状态的节点编号if (k < 0) {maxid[now] = i; return;}int t = (s[i] >> k) & 1;if (pre) son[now][t ^ 1] = son[pre][t ^ 1];son[now][t] = ++idx;insert(i, k - 1, son[pre][t], son[now][t]);maxid[now] = i;
}
查找:
查找的时候为了保证p在[l - 1, r - 1]范围内,我们从第r - 1个版的根节点开始找,该版本包含了之前的所有数,而且不含后面版本的东西,贪心地去找,如果找到的节点版本大于等于l - 1就可以跳过去,否则就不能跳过去,一直找到叶子节点会得到最终的版本号x = maxid[p],我们会发现从r - 1一路跳过来得到的01序列正是在r - 1版本中的x枝,代表了贪心选择后的最大值是属于第x个版本,答案就是s[x]^num。
ll query(int rt, int l, int num) {int p = rt;for (int i = 23; i >= 0; --i) {int t = (num >> i) & 1;if (son[p][t ^ 1] && maxid[son[p][t ^ 1]] >= l) p = son[p][t ^ 1];else p = son[p][t];}return num ^ s[maxid[p]];
}
注意点:
-
需要开一个第0版本。
为什么?
当l = 1时,我们有可能会选择到s[l - 1]即s[0],所以第0版应该加入一个0。
-
maxid[0] = -1.
如果maxid[0] = 0则表示了编号为0的节点版本号是0,但事实上,0号节点代表空节点,没有任何有意义的节点编号为0,而版本号为0的树也有自己的节点,不能随便加一个无意义的空点。
AC代码:
#include <bits/stdc++.h>
using namespace std;
#define io ios::sync_with_stdio(false),cin.tie(0),cout.tie(0)
typedef long long ll;
#define int ll
#define pb push_back
#define eb emplace_back
#define m_p make_pair
const int mod = 998244353;
#define mem(a,b) memset(a,b,sizeof a)
#define pii pair<int,int>
#define fi first
#define se second
const int inf = 0x3f3f3f3f;
const int N = 6e5 + 50;
//__builtin_ctzll(x);后导0的个数
//__builtin_popcount计算二进制中1的个数
int son[N * 25][2];
int root[N * 25];//根节点编号,root[x] 表示第x版本的根节点编号
int maxid[N * 25];//节点的版本号,maxid[x] 表示编号为x的节点的版本
int s[N], a[N];//前缀和,原数组
int idx = 0;void insert(int i, int k, int pre, int now) {if (k < 0) {maxid[now] = i; return;}int t = (s[i] >> k) & 1;if (pre) son[now][t ^ 1] = son[pre][t ^ 1];son[now][t] = ++idx;insert(i, k - 1, son[pre][t], son[now][t]);maxid[now] = i;
}ll query(int rt, int l, int num) {int p = rt;for (int i = 23; i >= 0; --i) {int t = (num >> i) & 1;if (son[p][t ^ 1] && maxid[son[p][t ^ 1]] >= l) p = son[p][t ^ 1];else p = son[p][t];}return num ^ s[maxid[p]];
}void work() {int n, m; cin >> n >> m;root[0] = ++idx;maxid[0] = -1;insert(0, 23, 0, root[0]);for (int i = 1; i <= n; ++i) {cin >> a[i];s[i] = s[i - 1] ^ a[i];root[i] = ++idx;insert(i, 23, root[i - 1], root[i]);}while (m--) {char ch; cin >> ch; if (ch == 'A') {int x; cin >> x; n++;s[n] = s[n - 1] ^ x;root[n] = ++idx;insert(n, 23, root[n - 1], root[n]);} else {int l, r, x; cin >> l >> r >> x;cout << query(root[r - 1], l - 1, x ^ s[n]) << '\n';}}
}signed main() {io;int t = 1;// cin >> t;while (t--) {work();}return 0;
}谢谢大家!
参考及引用:
Trie 字典树 详解
trie 树及其可持久化