Pytorch下基于卷积神经网络的手写数字识别
论文格式
利用wps初步美化论文格式教程
wps论文格式变的的原因
格式变的根本原因是word为流式文件,就算同是word同一个版本不同电脑也会有可能变,字体变是因为没有嵌入字体然后观看的那台没有这个字体。
一、流式文件是什么?
流式文件支持自由编辑,在浏览是按流式灌排的方式进行版面计算和绘制。流式文件一般包含元数据、式样、书签。超级链接、对象、节(最大的排版单元,不同页面式样的文档内容形成不同的分节)、段落、句及其他元素和属性。【1】这些内容按一定的层次结构进行描述,就形成了流式文档的格式。Word文档就是一种典型的流式文件,我们可以在文档中进行内容的编辑、添加、删除等操作。正是由于可编辑的特性,流式文件会因为不同的阅读器版本、操作系统版本等环境因素导致文档展示的内容效果不一致,也就是俗称的“跑版”现象。
主要流式文件格式有Word、TXT,代表流式软件有永中Office、微软Office、WPS等。
主要应用场景:一些较为日常的场合,比如协同合作、日常撰写等
二、版式文件是什么?
版式文件就是指不可编辑的,也就是固定版式的文件。版式文档不会“跑版”,在任何设备上显示和打印效果是高度精确一致的。【2】文件中的文字元素内容、位置、样式等在生成文件的时候就已经固定好了,其他人是不好进行修改编辑的,只能在上面加一些注释、签名等信息,在不同软件、操作系统等环境中能保持高度的一致性。主要版式文件格式有PDF、OFD,代表版式软件有永中版式办公软件(永中OFD)、福昕软件、数科网维、点聚信息等。
主要应用场景:一些较为严肃正式的场合,比如商务文档、电子公文、电子凭证、电子证照等
三、流式文件与版式文件的区别?
简单来说,流式文件在于「编辑」,版式文件在于「呈现」。流式文件:所见即所得的编辑内容
流式文件以永中Office为例,在阅读与编辑的时候,都必须在系统中安装相应的Office软件。版式文件:原版原式显示内容
版式文件独有的定版特性(格式不走样),在任何的设备、系统、屏幕尺寸和分辨率上展示的效果完全一致性。
关于python课程论文设计
Pytorch下基于卷积神经网络的手写数字识别
PyTorch下基于CNN的手写数字识别及应用研究
Pytorch框架下基于卷积神经网络实现手写数字识别
数字手写识别系统
import torch
from torch import nn
from torch.nn import functional as F
from torch import optim
import torchvision
from matplotlib import pyplot as plt
from utils import plot_image, plot_curve, one_hotbatch_size = 512# 步骤1. 加载数据集
train_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data', train=True, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(torchvision.datasets.MNIST('mnist_data/', train=False, download=True,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=False)x, y = next(iter(train_loader))
print(x.shape, y.shape, x.min(), x.max())
plot_image(x, y, 'image sample')# 定义神经网络模型
class Net(nn.Module):def __init__(self):super(Net, self).__init__()# xw+bself.fc1 = nn.Linear(28*28, 256)self.fc2 = nn.Linear(256, 64)self.fc3 = nn.Linear(64, 10)def forward(self, x):# x: [b, 1, 28, 28]# h1 = relu(xw1+b1)x = F.relu(self.fc1(x))# h2 = relu(h1w2+b2)x = F.relu(self.fc2(x))# h3 = h2w3+b3x = self.fc3(x)return xnet = Net()
# [w1, b1, w2, b2, w3, b3]
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)train_loss = []for epoch in range(3):for batch_idx, (x, y) in enumerate(train_loader):# x: [b, 1, 28, 28], y: [512]# [b, 1, 28, 28] => [b, 784]x = x.view(x.size(0), 28*28)# => [b, 10]out = net(x)# [b, 10]y_onehot = one_hot(y)# loss = mse(out, y_onehot)loss = F.mse_loss(out, y_onehot)optimizer.zero_grad()loss.backward()# w' = w - lr*gradoptimizer.step()train_loss.append(loss.item())if batch_idx % 10==0:print(epoch, batch_idx, loss.item())plot_curve(train_loss)
# 得到最优的[w1, b1, w2, b2, w3, b3]total_correct = 0
for x,y in test_loader:x = x.view(x.size(0), 28*28)out = net(x)# out: [b, 10] => pred: [b]pred = out.argmax(dim=1)correct = pred.eq(y).sum().float().item()total_correct += correcttotal_num = len(test_loader.dataset)
acc = total_correct / total_num
print('test acc:', acc)x, y = next(iter(test_loader))
out = net(x.view(x.size(0), 28*28))
pred = out.argmax(dim=1)
plot_image(x, pred, 'test')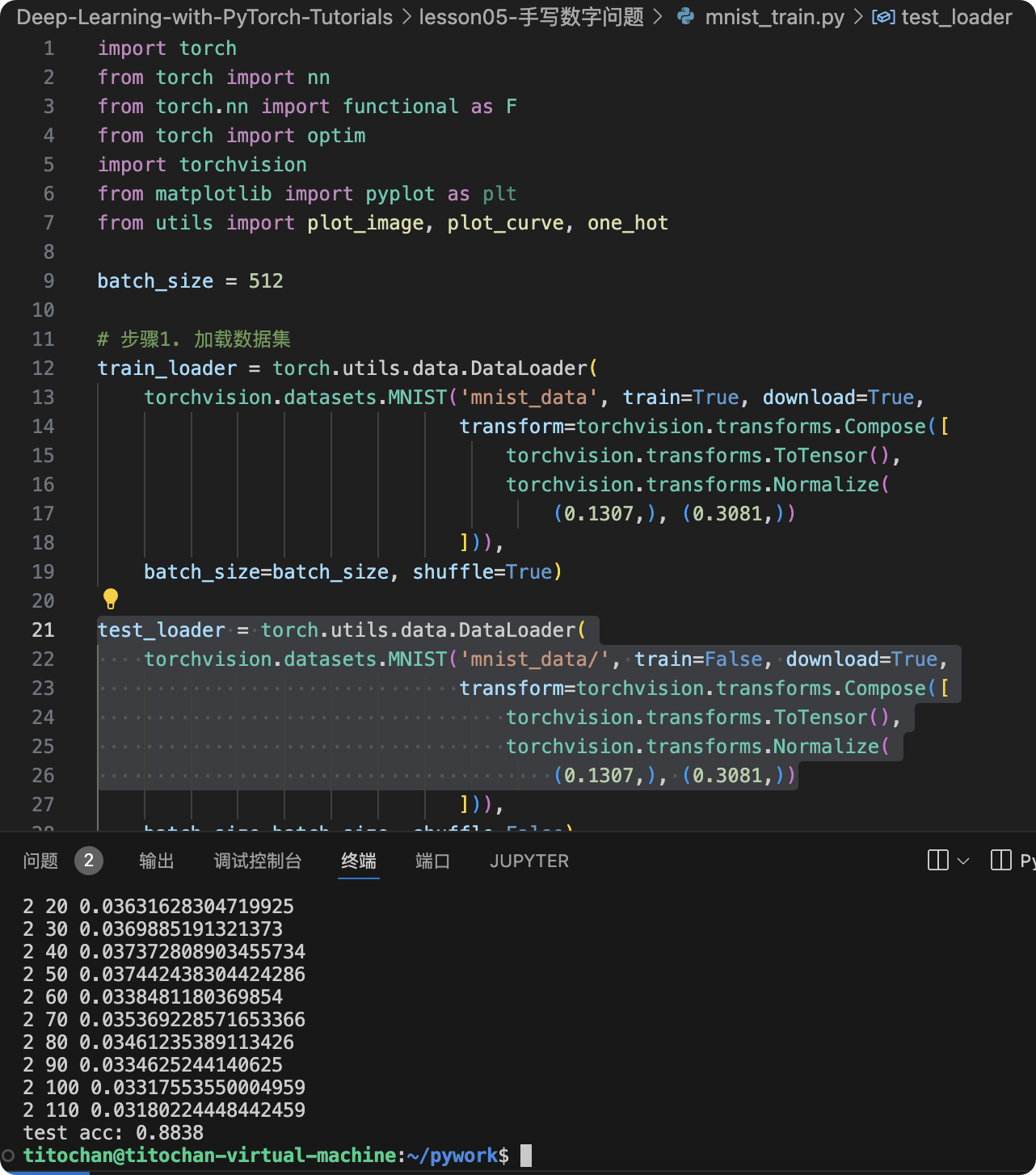
配环境配了我大半条命😭