一、Mysql整体架构
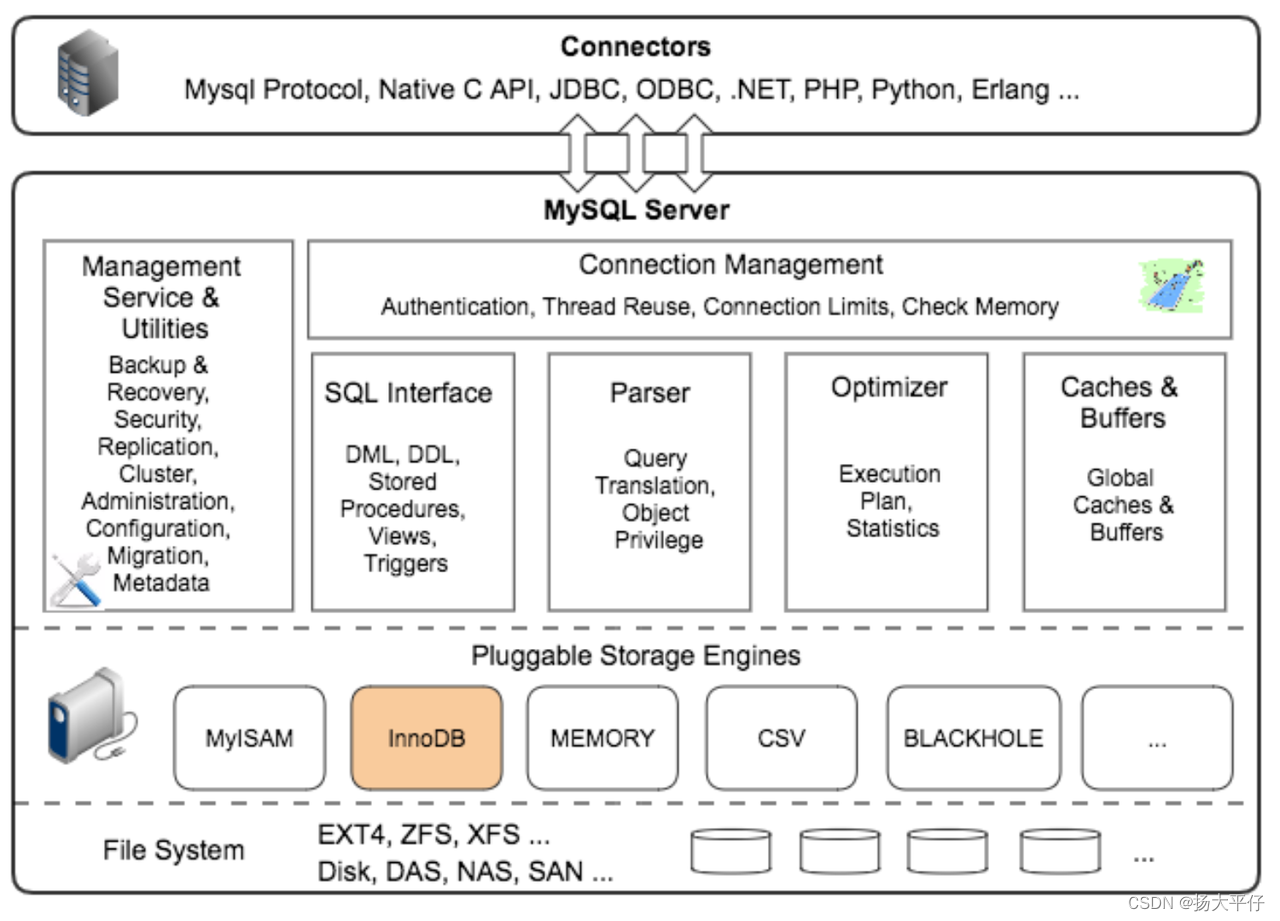
二、MySQL 5.7 支持的存储引擎
| 类型 | 描述 |
| MyISAM | 拥有较高的插入、查询速度,但不支持事务 |
| InnoDB | 5.5版本后Mysql的默认数据库,5.6版本后支持全文索引,事务型数据库的首选引擎,支持ACID事务,支持行级锁定,数据更新速度较快 |
| BDB | 源自Berkeley DB,事务型数据库的另一种选择,支持COMMIT和ROLLBACK等其他事务特性 |
| Memory | 所有数据置于内存的存储引擎,拥有极高的插入,更新和查询效率。但是会占用和数据量成正比的内存空间。并且其内容会在Mysql重新启动时丢失 |
| Merge | 将一定数量的MyISAM表联合而成一个整体,在超大规模数据存储时很有用 |
| Archive | 非常适合存储大量的独立的,作为历史记录的数据。因为它们不经常被读取。Archive拥有高效的插入速度,但其对查询的支持相对较差 |
| Federated | 将不同的Mysql服务器联合起来,逻辑上组成一个完整的数据库。非常适合分布式应用 |
| NDB | 高冗余的存储引擎,用多台数据机器联合提供服务以提高整体性能和安全性。适合数据量大,安全和性能要求高的应用 |
| CSV | 逻辑上由逗号分割数据的存储引擎。它会在数据库子目录里为每个数据表创建一个.CSV文件。这是一种普通文本文件,每个数据行占用一个文本行。CSV存储引擎不支持索引 |
| BlackHole | 黑洞引擎,写入的任何数据都会消失,一般用于记录binlog做复制的中继 |
三、InnoDB 原理浅谈
3.1 InnoDB整体架构
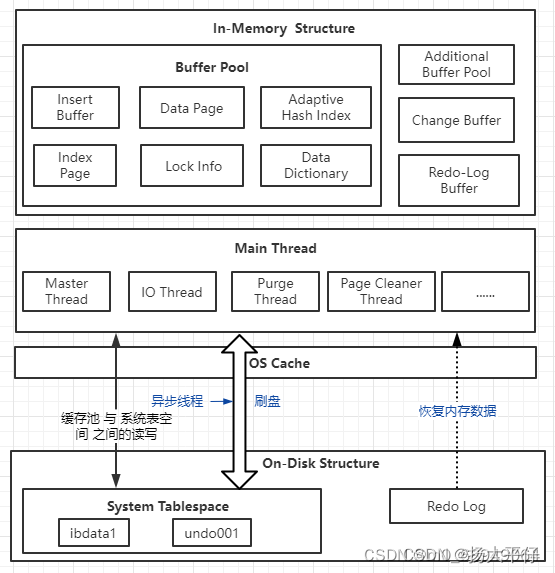
InnoDB的整个体系架构就是由多个内存块组成的缓冲池及多个后台线程构成。缓冲池缓存磁盘数据(解决cpu速度和磁盘速度的严重不匹配问题),后台进程保证缓存池和磁盘数据的一致性(读取、刷新),并保证数据异常宕机时能恢复到正常状态。
3.2 后台线程(Thread)
InnoDB后台有多个不同的线程,用来负责不同的任务。主要有如下:
Master Thread
InnoDB的Master Thread是主线程,担负着调度其他各个线程的重要任务,其优先级最高。主要功能包括:
1、异步刷新缓冲池中的数据到磁盘,以保证数据的一致性。
2、调度各个线程执行特定的任务,包括脏页的刷新、undo页的回收、redo日志的刷新、合并写缓冲等。
IO Thread
在InnoDB中,大量采用了异步IO(AIO)技术来进行读写处理,这一特性可以显著提高数据库的性能。通过异步IO,InnoDB能够在进行IO操作时不阻塞其他线程的执行,从而更高效地处理读写请求。
IO线程配置。在InnoDB 1.0版本之前,共有4个IO Thread,分别是:
write thread:负责写操作,将缓存脏页(内存中已被修改的数据页)刷新到磁盘。
read thread:负责读取操作,将数据从磁盘加载到缓存页。
insert buffer thread:负责将写缓冲内容刷新到磁盘。
log thread:负责将日志缓冲区内容刷新到磁盘。
而在后续版本中,read thread和write thread分别增大到了4个,总共有10个IO线程。
要查看InnoDB的IO线程状态,可以使用MySQL的命令show engine innodb status;,该命令将显示当前InnoDB引擎的详细状态信息,包括IO线程的数量和状态等。
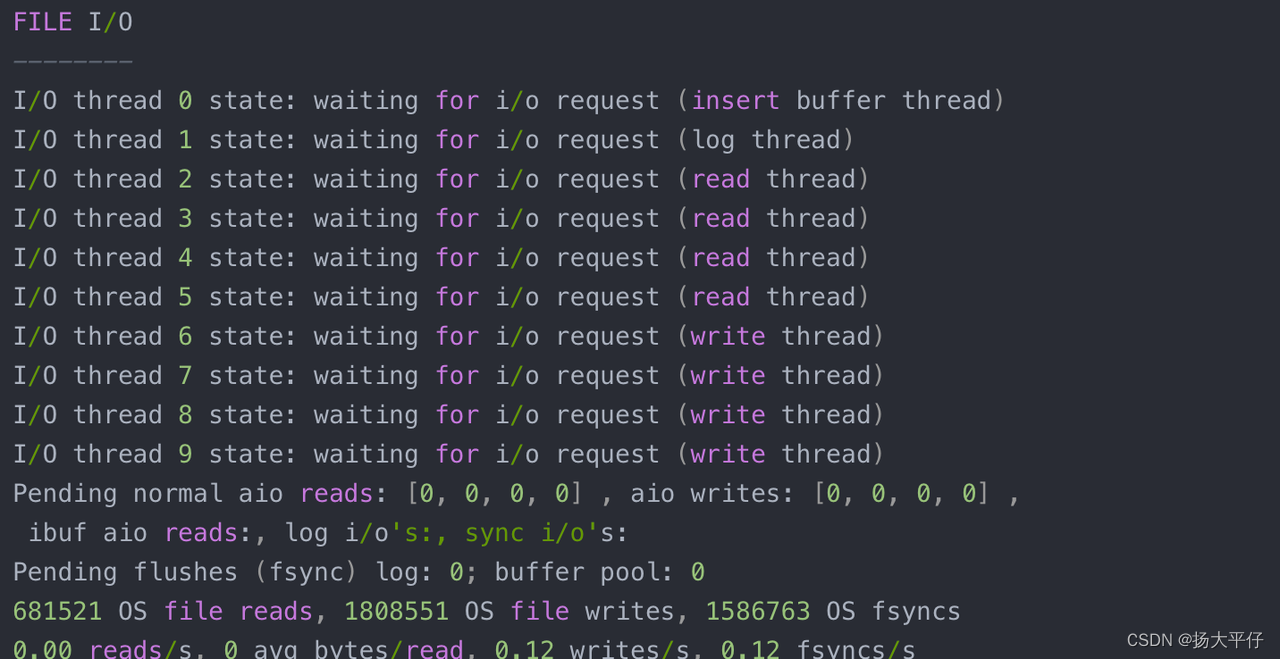
Purge Thread
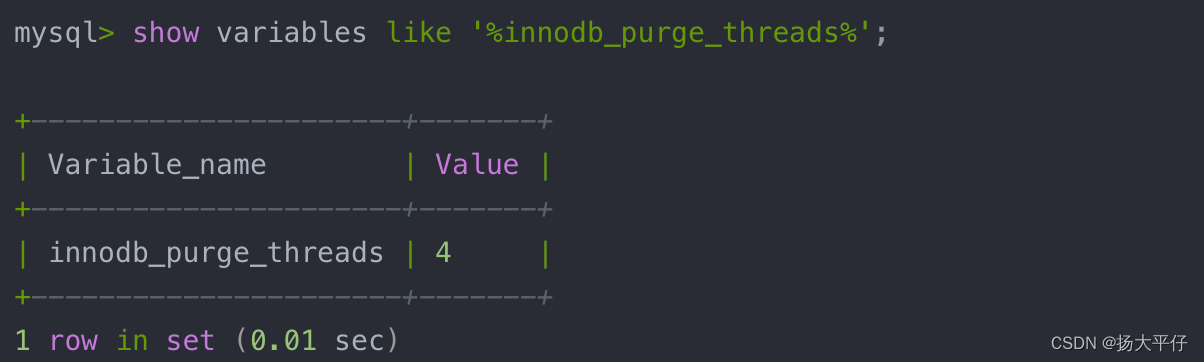
事务被提交之后, undo log可能不再需要, 因此需要Purge Thread来回收已经使用并分配的undo页。InnoDB1.2+开始,支持多个Purge Thread这样做的目的为了加快回收undo页(释放内存)
Page Cleaner Thread
Page Cleaner Thread是在InnoDB 1.2+版本新引入的,其作用是将之前版本中脏页的刷新操作都放入单独的线程中来完成, 这样减轻了Master Thread 的工作及对于用户查询线程的阻塞。
3.3 内存(In-Memory Structure)
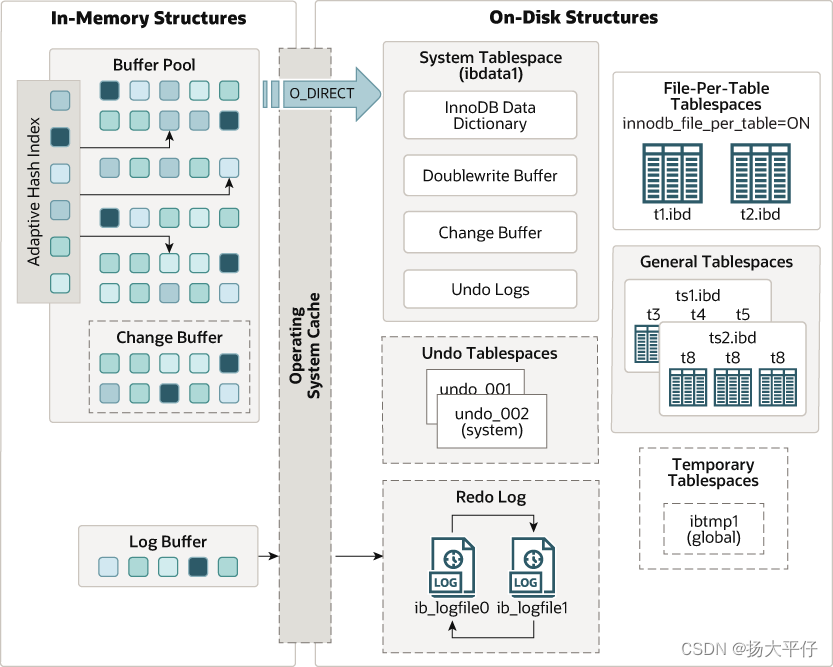
Mysql 5.7 模型图
内存中的结构主要包括Buffer Pool,Change Buffer、Adaptive Hash Index以及 Log Buffer 四部分。如果从内存上来看,Change Buffer和Adaptive Hash Index占用的内存都属于Buffer Pool,Log Buffer占用的内存与 Buffer Pool独立。
Buffer Pool
通常 MySQL 服务器的 80% 的物理内存会分配给Buffer Pool。基于效率考虑,InnoDB中数据管理的最小单位为页,默认每页大小为16KB,每页包含若干行数据。为了提高缓存管理效率,InnoDB的缓存池通过一个页链表实现,很少访问的页会通过缓存池的 LRU 算法淘汰出去。
Change Buffer
写缓冲区,是针对二级索引(辅助索引) 页的更新优化措施。在进行DML操作时,如果请求的是辅助索引(非唯一键索引)没有在缓冲池中时,并不会立刻将磁盘页加载到缓冲池,而是在Change Buffer记录缓冲变更,等未来数据被读取时,再将数据合并恢复到BufferPool中。Change Buffer占用BufferPool空间,默认占25%,最大允许占50%,可以根据读写业务量来进行调整。参数innodb_change_buffer_max_size;
在 MySQL5.5 之前 Change Buffer其实叫 Insert Buffer,最初只支持 insert 操作的缓存,随着支持操作类型的增加,改名为 Change Buffer。可以通过 innodb_change_buffering 配置是否缓存辅助索引页的修改,默认为 all,即缓存 insert/delete-mark/purge 操作(注:MySQL 删除数据通常分为两步,第一步是delete-mark,即只标记,而purge才是真正的删除数据)。
Adaptive Hash Index
自适应哈希索引(AHI)查询非常快,一般时间复杂度为 O(1),相比 B+ 树通常要查询 3~4次,效率会有很大提升。innodb通过观察索引页上的查询次数,如果发现建立哈希索引可以提升查询效率,则会自动建立哈希索引,称之为自适应哈希索引,不需要人工干预,可以通过 innodb_adaptive_hash_index 开启,MySQL5.7 默认开启。考虑到不同系统的差异,有些系统开启自适应哈希索引可能会导致性能提升不明显,而且为监控索引页查询次数增加了多余的性能损耗 MySQL5.7 更改了AHI 实现机制,每个AHI 都分配了专门分区,通过 innodb_adaptive_hash_index_parts配置分区数目,默认是8个。
Log Buffer
日志缓冲区,用来保存要写入磁盘上log文件的数据,日志缓冲区的内容定期刷新到磁盘log文件中。日志缓冲区满时会自动将其刷新到磁盘,当遇到BLOB或多行更新的大事务操作时,增加日志缓冲区可以节省磁盘I/O。可以通过将innodb_log_buffer_size参数调大,减少磁盘IO频率。
LogBuffer主要作用是: 用来优化每次更新操作之后都要写入redo log而产生的磁盘IO问题。
TODO:
1、log 存储内容
2、undo\redo存的什么内容,什么时候写buffer ?事务提交前or后?
四、各种log 说明
Bin log
数据格式
在Mysql 5.1 开始引入binlog_format参数,该值有三种模式,分别是STATEMENT模式、ROW模式和MIXED模式。下面以UPDATE t1 SET username=UPPER(username)为例说明bin log 在不同模式下存储的内容。
STATEMENT模式:在STATEMENT模式下,MySQL会将执行的SQL语句记录到binlog中。这意味着binlog中存储的是对数据进行更改的SQL语句,而不是实际更改的数据本身。这种模式下,binlog会记录SQL语句,例如INSERT、UPDATE和DELETE语句,以便在主服务器上执行相同的SQL语句来复制数据更改到从服务器。
存储的就是逻辑sql UPDATE t1 SET username=UPPER(username);
由于记录的是SQL语句,因此在某些情况下可能会出现不同步或者不一致的情况,例如当使用了不确定函数或者随机函数时。
ROW模式:在ROW模式下,MySQL会将受影响的行的实际更改记录到binlog中。这意味着binlog中存储的是数据更改的实际内容,而不是SQL语句。这种模式下,binlog会记录哪些行受到了更改,以及更改前后的具体数值。这样可以确保从服务器上的数据与主服务器完全一致。查看Row 格式内容需要用到mysqlbinlog -vv 命令:
[root@nineyou0-43 data]# mysqlbinlog -vv --start-position=1065 test.000004
……
BINLOG '
EBq/ShMBAAAAPwAAAK4EAAAAADoAAAAAAAAABm1lbWJlcgACdDIACgMPDw/+CgsPAQwKJAAoAEAA
/gJAAAAA
EBq/ShgBAAAAtAAAAGIFAAAQADoAAAAAAAEACv8A/AEAAAALYWxleDk5ODh5b3UEOXlvdSA3
Y2JiMzI1MmJhNmI3ZTljNDIyZmFjNTMzNGQyMjA1NAFNLacPAAAAAABjEnpxPBIAAAD8AQAAAAtB
TEVYOTk4OFlPVQQ5eW91IDdjYmIzMjUyYmE2YjdlOWM0MjJmYWM1MzM0ZDIyMDU0AU0tpw8AAAAA
AGMSenE8EgAA
'/*!*/;
### UPDATE member.t2
### WHERE
### @1=1 /* INT meta=0 nullable=0 is_null=0 */
### @2='david' /* VARSTRING(36) meta=36 nullable=0 is_null=0 */
### @3='family' /* VARSTRING(40) meta=40 nullable=0 is_null=0 */
### @4='7cbb3252ba6b7e9c422fac5334d22054' /* VARSTRING(64) meta=64 nullable=0 is_null=0 */
### @5='M' /* STRING(2) meta=65026 nullable=0 is_null=0 */
### @6='2009:09:13' /* DATE meta=0 nullable=0 is_null=0 */
### @7='00:00:00' /* TIME meta=0 nullable=0 is_null=0 */
### @8='' /* VARSTRING(64) meta=64 nullable=0 is_null=0 */
### @9=0 /* TINYINT meta=0 nullable=0 is_null=0 */
### @10=2009-08-11 16:32:35 /* DATETIME meta=0 nullable=0 is_null=0 */
### SET
### @1=1 /* INT meta=0 nullable=0 is_null=0 */
### @2='DAVID' /* VARSTRING(36) meta=36 nullable=0 is_null=0 */
### @3=family /* VARSTRING(40) meta=40 nullable=0 is_null=0 */
### @4='7cbb3252ba6b7e9c422fac5334d22054' /* VARSTRING(64) meta=64 nullable=0 is_null=0 */
### @5='M' /* STRING(2) meta=65026 nullable=0 is_null=0 */
### @6='2009:09:13' /* DATE meta=0 nullable=0 is_null=0 */
### @7='00:00:00' /* TIME meta=0 nullable=0 is_null=0 */
### @8='' /* VARSTRING(64) meta=64 nullable=0 is_null=0 */
### @9=0 /* TINYINT meta=0 nullable=0 is_null=0 */
### @10=2009-08-11 16:32:35 /* DATETIME meta=0 nullable=0 is_null=0 */
# at 1378
#090927 15:53:52 server id 1 end_log_pos 1405 Xid = 1110
COMMIT/*!*/;
DELIMITER ;
# End of log file
ROLLBACK /* added by mysqlbinlog */;
/*!50003 SET COMPLETION_TYPE=@OLD_COMPLETION_TYPE*/;MIXED模式:
在MIXED格式下,MySQL默认采用STATEMENT格式进行二进制日志文件的记录,但是在一些情况下会使用ROW格式,可能的情况有:
1)表的存储引擎为NDB,这时对表的DML操作都会以ROW格式记录。
2)使用了UUID()、USER()、CURRENT_USER()、FOUND_ROWS()、ROW_COUNT()等不确定函数。
3)使用了INSERT DELAY语句。
4)使用了用户定义函数(UDF)。
5)使用了临时表(temporary table)。
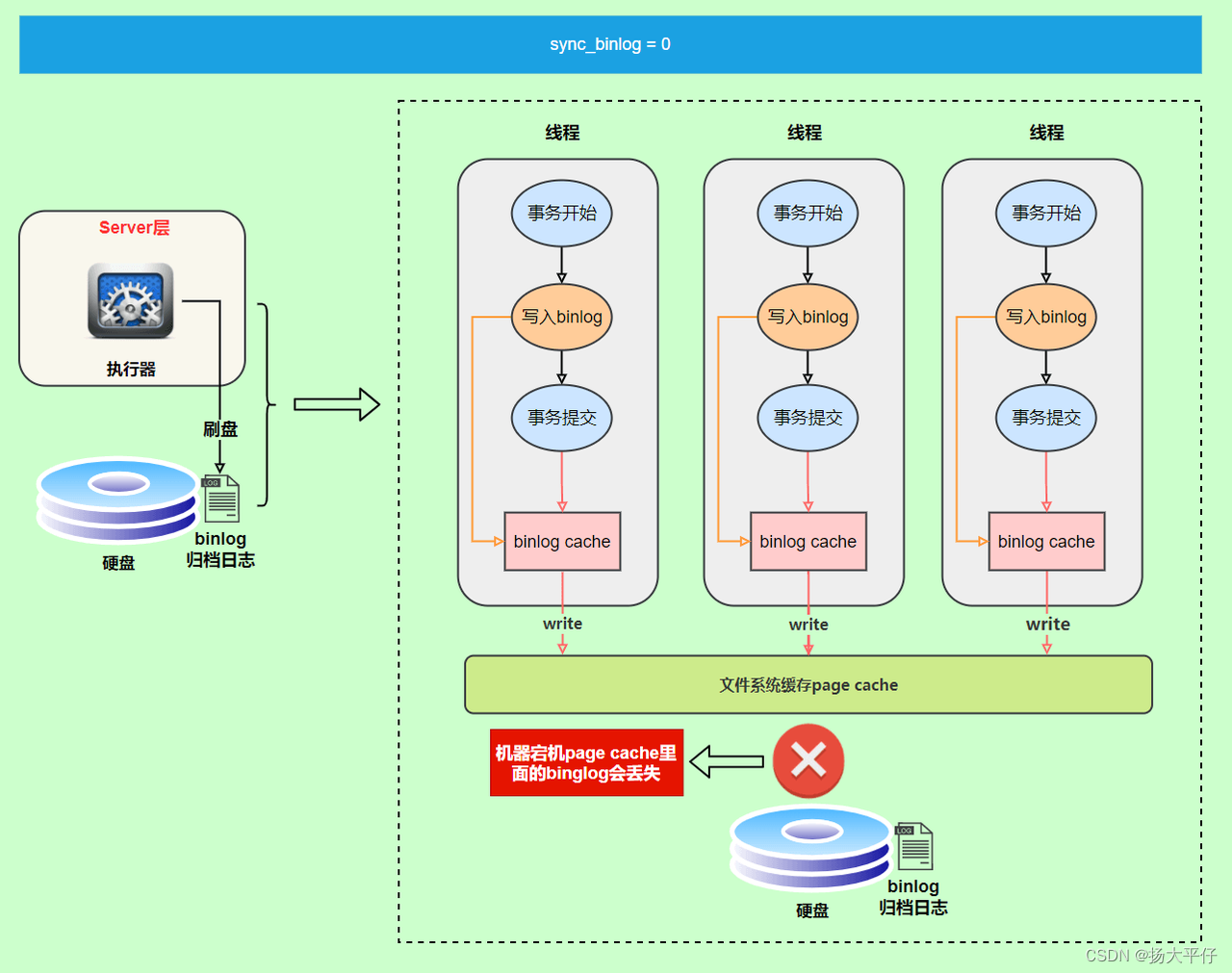
刷盘时机
write和fsync的时机,可以由参数sync_binlog控制,默认是0。为0的时候,表示每次提交事务都只write,由系统自行判断什么时候执行fsync。
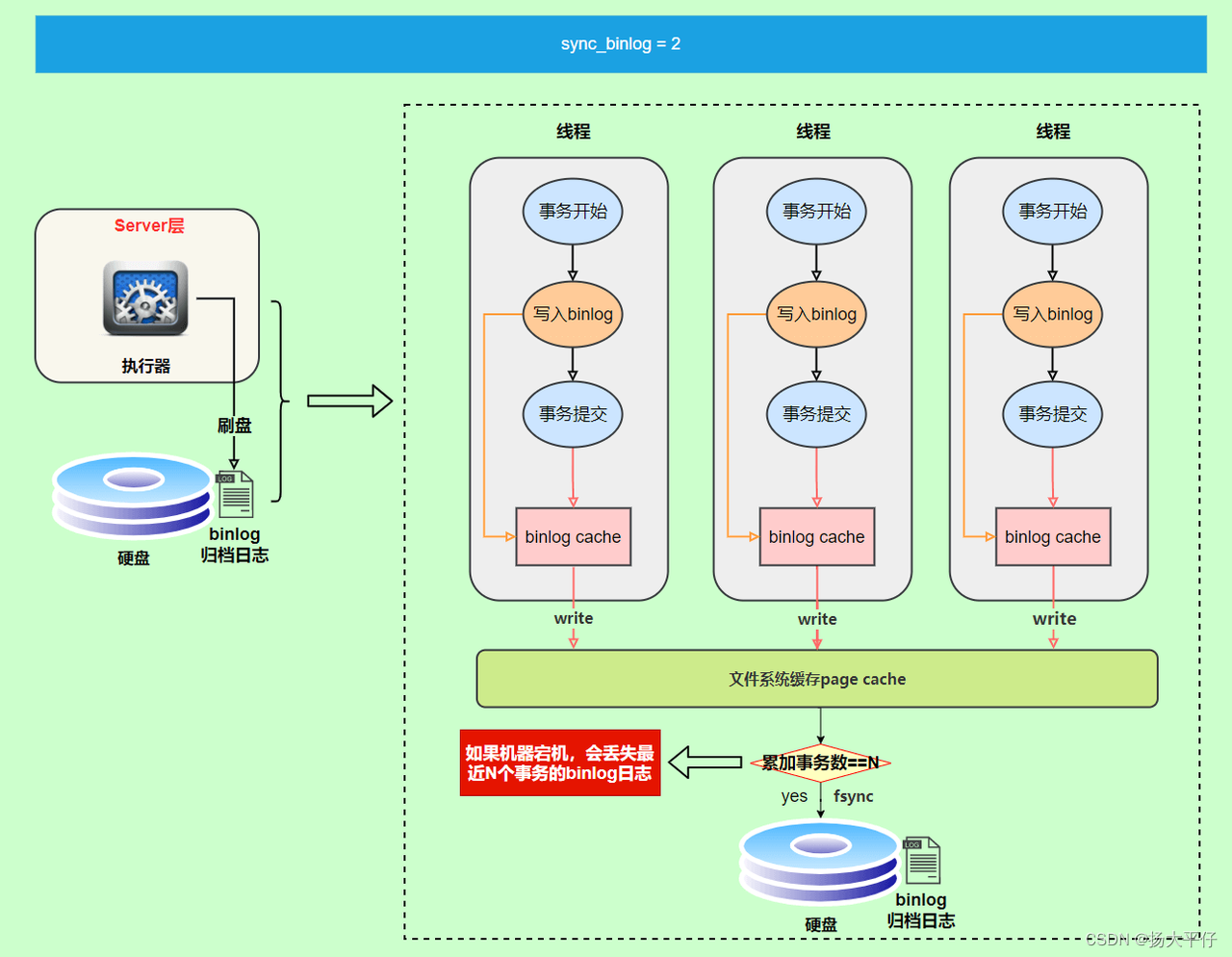
Buffer Pool
Buffer Poo是一系列数据页的集合,包含:索引页、undo页、inserBuffer/ChangeBuffer、Adaptive Hash Index等。
后台线程定时刷新:InnoDB 存储引擎有一个后台线程,每隔1 秒或10秒。
Insert Buffer/Change Buffer
数据格式
写入缓存本质是一颗B+树,对于非叶节点存放的是查询key,构造如下:
![]()
space:待写入记录的表空间ID,占4字节;
marker:用来兼容老版本的insert buffer,占1字节;
offset:表示页所在的偏移量,占4字节。
对于叶子节点,构造如下:

可以发现,叶子节点保存的记录,除了space,marker,offset之外,还多个metadata和另外4个字段,因此和单纯的数据记录相比,Insert Buffer还需要额外的13个字节的开销。
1)matadata字段,占用4个字节,用来记录此条信息插入Insert Buffer的顺序。
2)从第五列开始,就是实际插入的各个字段(非聚簇索引的值)的值了。
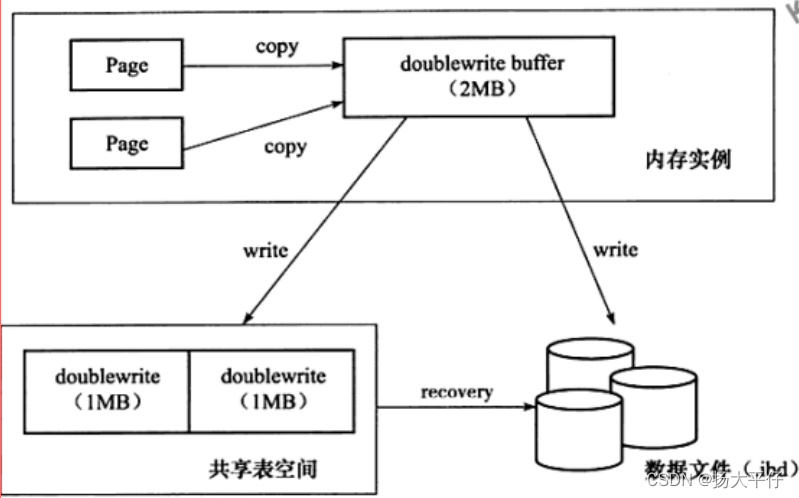
两次写
当发生数据库宕机时,可能InnoDB存储引擎正在写入某个页到表中,而这个页只写了一部分,比如16kb的页,只写了前4kb,之后就发生了宕机,这种情况被称之为部分写失效(partial page write)。
double write由两部分组成,第一部分是内存中的double write buffer,大小为2MB,另一部分是物理磁盘上共享表空间中连续的 128个页,即 2个区(extent),大小同样为2MB在对缓冲池的脏页进行刷新时,并不直接写磁盘,而是会通过memcpy函数将脏页先复制到内存中的doublewrite buffer,之后通过doublewrite buffer再分两次,每次1MB顺序地写入共享表空间的物理磁盘上,然后马上调用fsync函数同步磁盘,避免缓冲写带来的问题。在这个过程中,因为 doublewrite 页是连续的,因此这个过程是顺序写的,开销并不是很大。在完成doublewrite页的写入后,再将doublewrite buffer 中的页写入各个表空间文件中,此时的写入则是离散的。如果操作系统在将页写入磁盘的过程中发生了崩溃,在恢复过程中, InnoDB存储引擎可以从共享表空间中的doublewrite中找到该页的一个副本,将其复制到表空间文件,再应用重做日志。
Merge Insert Buffer
Insert Buffer何时合并到真正的辅助索引中呢?
1、辅助索引页被读取到缓存池时
当非聚簇索引被读取到缓冲池中时,如正常执行的SELECT操作,这是需要检查Insert Buffer Bitmap页,然后确认该辅助索引是否有记录存放在Insert Buffer B+树中。若有,则将Insert Buffer B+树中的该页的记录插入到索引页中。可以看到对该页的多次的操作记录可以通过一次合并操作合并到了索引页中,因此性能大幅提高。
2、索引页的可用空间小于1/32
Insert Buffer Bitmap页用于追踪每个索引页的可用空间大小,并至少还有1/32的可用空间。如果插入索引页记录时检测到插入记录后可用空间会小于1/32也,则会进行一个合并操作,即前置读取非聚簇索引页,将Insert Buffer B+树中该页的记录合并到索引页中。
3、Master Thread每秒或者每10秒执行一次的Merge Insert Buffer操作
如果进行Merge时,要进行Merge的表已经被删除,此时直接丢弃Insert Buffer/Change Buffer中的数据记录。
Adaptive Hash Index
Innodb 自己为热点页建立的hash索引
Redo log
数据结构
Redo log的通用结构:
| redo_log_type | space_id | page_number | redo_log_body |
redo_log_type:占用1字节,表示重做日志的类型。
space_id:表示表空间的ID,采用压缩方式存储,占用空间可能小于4字节。
page_number:表示页的偏移量,也是压缩存储。
redo_log_body:表示每个重做日志的数据部分,恢复是需要调用相应的函数进行解析。
目前找到的相对可靠的说法是:redo_log_body存储的是更新后的字段和值。
| sql | redo_log_body | ||
| INSERT INTO users (id, name, age) VALUES (1, 'Alice', 30) | ... | ... | Insert: (1, 'Alice', 30) |
| UPDATE users SET age = 31 WHERE id = 1 | ... | ... | Update: age = 31 WHERE id = 1 |
| DELETE FROM users WHERE id = 1 | offset | Delete: WHERE id = 1 | |
Redo log 都是以512字节存储,也就是一个log block,其和磁盘的一个扇区大小保持一致,因此重做日志写入磁盘可以保证原子性,不需要doublewrite技术。每个InnoDB存储引擎至少有1个重做日志文件组(group),每个文件组至少有2个重做日志文件,如默认的ib_logfile0和ib_logfile1。
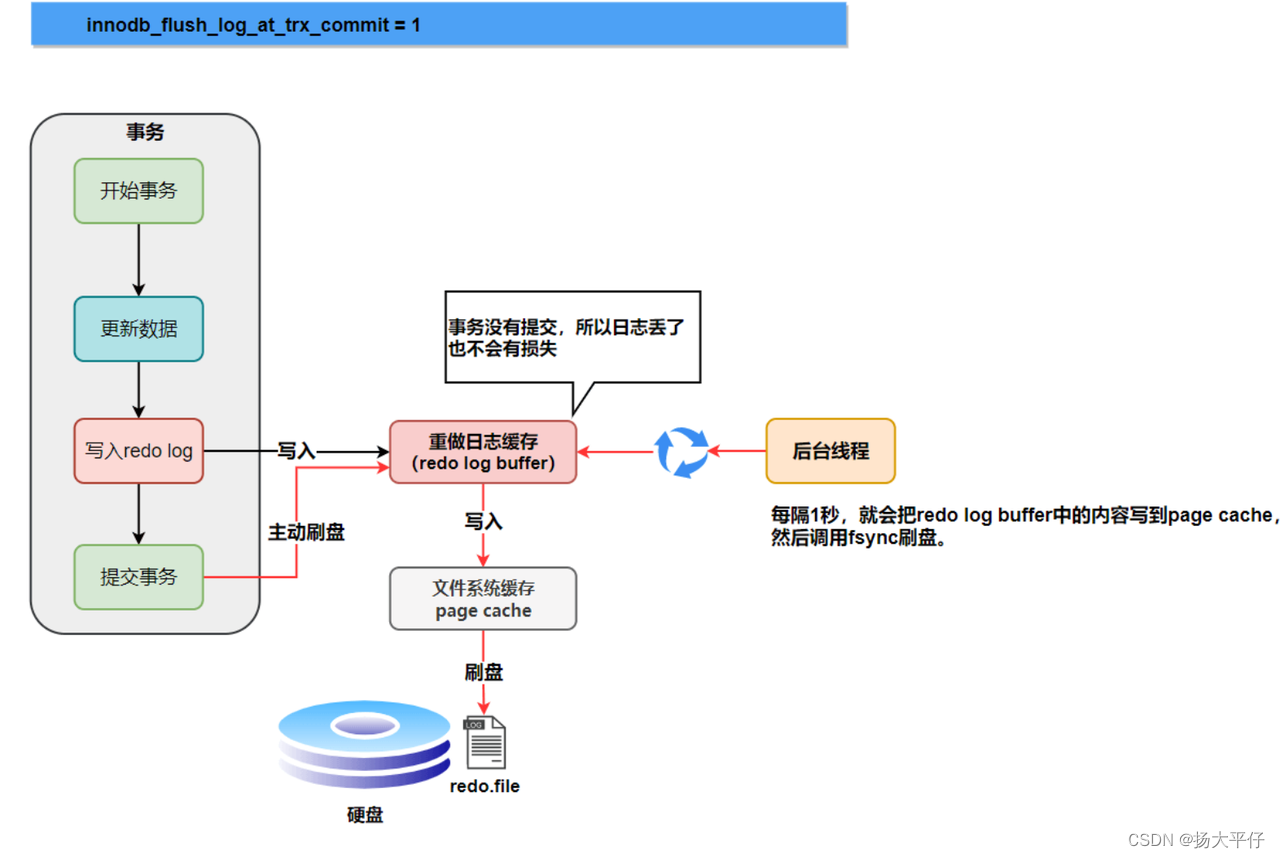
刷盘时机
1、log buffer空间不足:如果当前写入log buffer的redo日志量占满了log buffer总容量的50%左右,就需要把这些日志刷新到磁盘;
2、事务提交:为了保证持久性,必须在事务提交时把对应的redo日志刷新到磁盘。可以通过innodb_flush_log_at_trx_commit参数选择为其他策略
0 :设置为 0 的时候,表示每次事务提交时不进行刷盘操作
1 :设置为 1 的时候,表示每次事务提交时都将进行刷盘操作 (默认值)
2 :设置为 2 的时候,表示每次事务提交时都只把 redo log buffer 内容写入 page cache
3、后台线程定时刷新:InnoDB 存储引擎有一个后台线程,每隔1 秒或10秒,就会把 redo log buffer 中的内容写到文件系统缓存(page cache),然后调用 fsync 刷盘。
4、正常关闭服务器
5、做checkpoint
Undo log
概念
redo日志记录了事务的行为,可以很好的通过其对页进行“重做”操作。但是事务还需要进行回滚,就需要undo。因此在对数据库进行修改的时候,InnoDB存储引擎不但会产生redo,还会产生一定量的undo。如果回滚,利用undo信息即那个数据回滚到修改之前的样子,对于每个insert,InnoDB存储引擎会完成一个DELETE,对于每个DELETE,InnoDB会执行一个insert,对于一个update,InnoDB会执行一个相反的update,将修改前的行放回去。redo存放在重做日志文件中,与redo不同,undo存放在数据库内部的一个特殊段中,这个段叫做undo段,undo段在共享空间(ibdata)中。
InnoDB存储引擎对undo的管理同样采用段的方式,InnoDB存储引擎有rollback segment即回滚段,每个回滚段中记录了1024个undo log segment,而在每个undo log segment段中进行undo页的申请。事务在undo log segment分配页并写入到undo log的这个过程同样需要写入重做日志,当事务提交时,InnoDB存储引擎会做以下两件事情:
将undo log放入列表,供以后的purge操作
判断undo log所在的页是否可以重做,若可以分配给下个事务使用。
undo log格式
在innodb存储引擎中undo log可以分为:
-
insert undo log(insert 操作产生的undo log)
-
update undo log(update和delete操作产生的undo log)
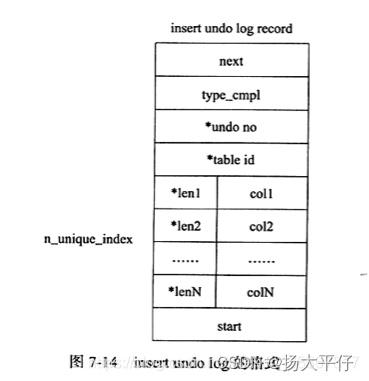 | *表示对存储字段进行了压缩
事务提交后就可以删除 |
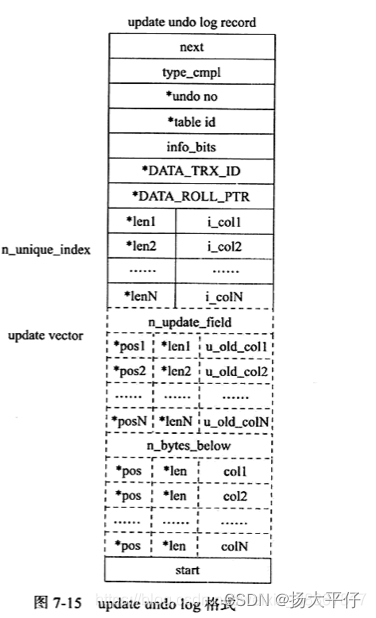 | *表示对存储字段进行了压缩
type_cmpl可能的值如下: 12 TRX_UNDO_UPD_EXIST_REC更新non-delete-mark的记录 13 TRX_UNDO_UPD_DEL_REC将delete的记录标记为not delete。 14 TRX_UNDO_DEL_NARK_REC将记录标记为DELETE。 update vector表示因为update操作导致发生改变的列。每个修改的列信息都要记录到undo log中,对于不同的undo log类型,可能还需要记录对索引列所做的修改。 |
五、主线程工作机制
# 表示 * 部分是有改动的内容,或者新增的内容
void master_thread(){loop:for(int i = 0; i < 10 ;i++){thread_sleep(1) // 每 1 秒一次的操作 loopdo log buffer flush to disk // 1. 日志缓冲刷新到磁盘if (last_one_second_ios < 5% innodb_io_capacity )-- 前一秒IO次数小于5%次,则认为io压力小执行合并插入缓冲操作do merge 5% innodb_io_capacity insert buffer// 2. 合并5%插入缓冲if ( buf_get_modified_ratio_pct > innodb_max_dirty_pages_pct )--当前缓冲池中脏页的比例大于配置文件中innodb_max_dirty_pages_pct(默认75,代表75%)do buffer pool flush 100% innodb_io_capacity dirty pages// 3. 刷新缓冲池中的innodb_io_capacity个脏页到磁盘,有参数可以优化这个刷新,innodb_adaptive_flushingelse if ( enable adaptive flush ) // * Innodb 1.0 - Innodb 1.2 才新出现do buffer pool desired amount dirty pagesif (no user activity )goto background loop // 4. 没有用户活动,切换到后台循环 background loop}// do things once per ten seconds // 每十秒一次的操作 loopif (last_ten_seconds_ios < innodb_io_capacity)do buffer pool flush 100% innodb_io_capacity dirty pages// 一. 刷新缓冲池中的innodb_io_capacity个脏页到磁盘 => 每 1 秒操作中的 3. 但条件不同,要参考 I/Odo merge at most 5% innodb_io_capacity insert buffer // 二. 合并最多5%innodb_io_capacity插入缓冲 => 每 1 秒操作中的 2. do log buffer flush to disk // 三. 日志缓冲刷新到磁盘 => 每 1 秒操作中的 1.do full purge // 四. 删除无用的 Undo 页if (buf_get_modified_ratio_pct > 70% ) // 五. 刷新缓冲池中的脏页到磁盘 => 每 1 秒操作中的 3. 条件相似但不同do buffer pool flush 100% innodb_io_capacity dirty pageselsedo buffer poll flush 10% innodb_io_capacity dirty pagesgoto loop; background loop: // 后台循环 background loopdo full purge // Ⅰ 删除无用的 Undo 页 ==> 每 10 秒操作中的 四.do merge 100% innodb_io_capacity insert buffer // Ⅱ 合并插入缓冲页 ==> 每 10 秒操作中的 二. => 每 1 秒操作中的 2.if (not idle)goto loop; // Ⅲ 跳到主循环else:flush loop: // Flush循环 flush loop ,通过 background loop 才能进入,且状态是 idle 空闲的 do buffer pool flush 100% innodb dirty pages// Ⅳ 不断刷新缓冲池中的脏页到磁盘,直到跳出循环 ==> 每 10 秒操作中的 五. => 每 1 秒操作中的 3. if (buf_get_modified_ratio_pct > innodb_max_dirty_pages_pct )goto flush loop;else:suspend loop: // Suspend循环 suspend loop,通过 flush loop 才能进入,且 buf_get_modified_ratio_pct < innodb_max_dirty_pages_pctsuspend_thread()waiting eventif (event arrived )goto loop; // 事件来临,跳入主循环goto suspend loop; goto background loop;
}六、Mysql 数据会不会丢失
sql执行流程
在innodb中一条update sql 的执行流程:
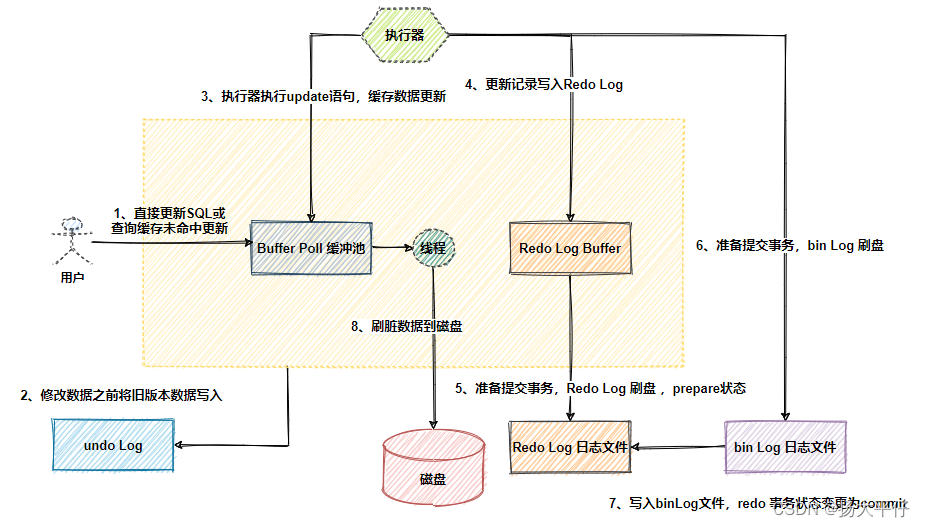
-
MySQL Server 层的执行器调用 InnoDB 存储引擎的数据更新接口;
-
存储引擎更新 Buffer Pool 中的缓存页,
-
同时存储引擎记录一条 redo log 到 redo log buffer 中,并将该条 redo log 的状态标记为 prepare 状态;
-
接着存储引擎告诉执行器,可以提交事务了。执行器接到通知后,会写 binlog 日志,然后提交事务;
-
存储引擎接到提交事务的通知后,将 redo log 的日志状态标记为 commit 状态;
-
接着根据 innodb_flush_log_at_commit 参数的配置,决定是否将 redo log buffer 中的日志刷入到磁盘。
只要 innodb_flush_log_at_trx_commit 和 sync_binlog 都为 1(通常称为:双一),加上两次写技术。就能确保 MySQL 机器断电重启后,数据不丢失。
崩溃恢复机制
1、从redo log 文件中得到最后一次check point发生的LSN
2、从这个点开始应用redo log
3、接下来就是进行undo,反做哪些未提交的事务(因为是先写日志的方式,所以可能日志文件里面已经记录了事务日志,但最后事务可能没有提交成功,所以现在这个过程就是将这些事务取消)
4、在第3步进行时又分为两种情况:
如果开启了binlog,那么在恢复过程中判断哪些事务未提交时,就会利用binlog判断(bin log一定是只记录提交过的事务)
如果没有开启binlog,那么只能利用redo log , 事实上它会拿redo log的LSN与这行日志的对应被修改页的LSN进行比较,如果LSN大于等于redo log的LSN,那么就表示这个页是干净的,不需要被回滚。
参考文献
https://blog.51cto.com/u_16213629/9632300
《Mysql技术内幕 Innodb 存储引擎》--第二版 姜承尧
https://blog.csdn.net/tjcwt2011/article/details/125602999
https://www.cnblogs.com/frankcui/p/15227775.html
https://blog.csdn.net/qq_25046827/article/details/132161038
https://www.jb51.net/article/273118.htm
https://dev.mysql.com/doc/refman/5.7/en/innodb-storage-engine.html
https://blog.csdn.net/m0_68949064/article/details/125679952
https://zhaox.github.io/2016/06/24/mysql-architecture
https://blog.csdn.net/m0_68949064/article/details/125679952
https://blog.csdn.net/fvdfsdafdsafs/article/details/138111598
https://blog.csdn.net/qq_43185851/article/details/135159576
https://blog.csdn.net/fvdfsdafdsafs/article/details/137889775
https://blog.csdn.net/fvdfsdafdsafs/article/details/137907693
https://blog.csdn.net/fvdfsdafdsafs/article/details/137923901