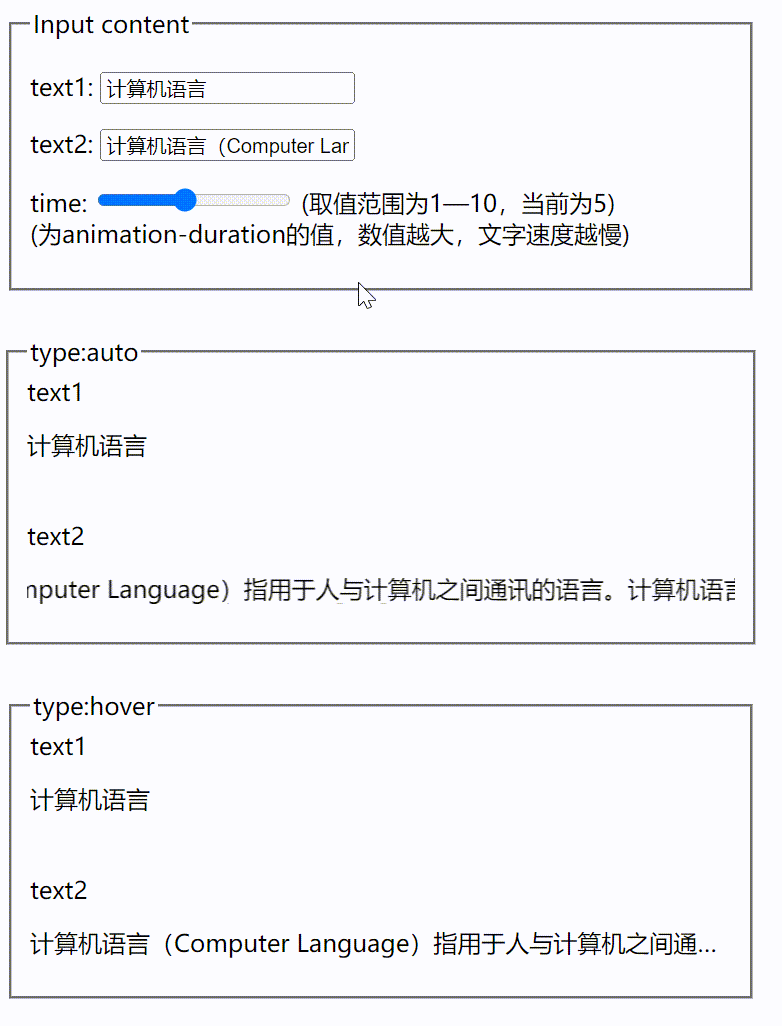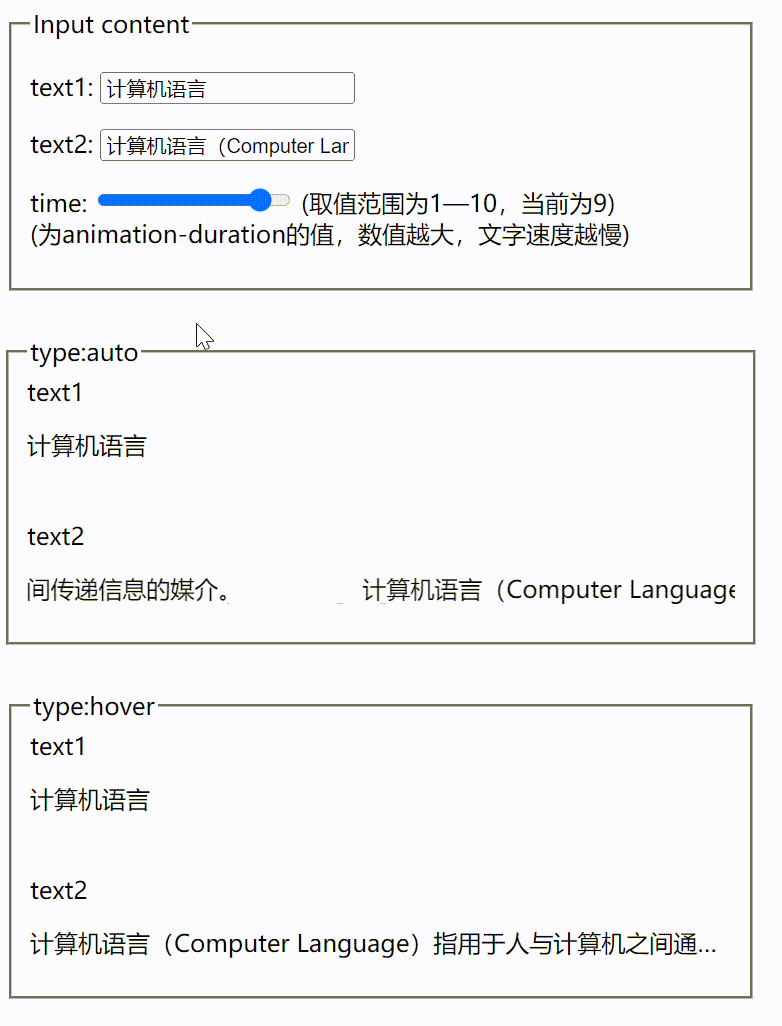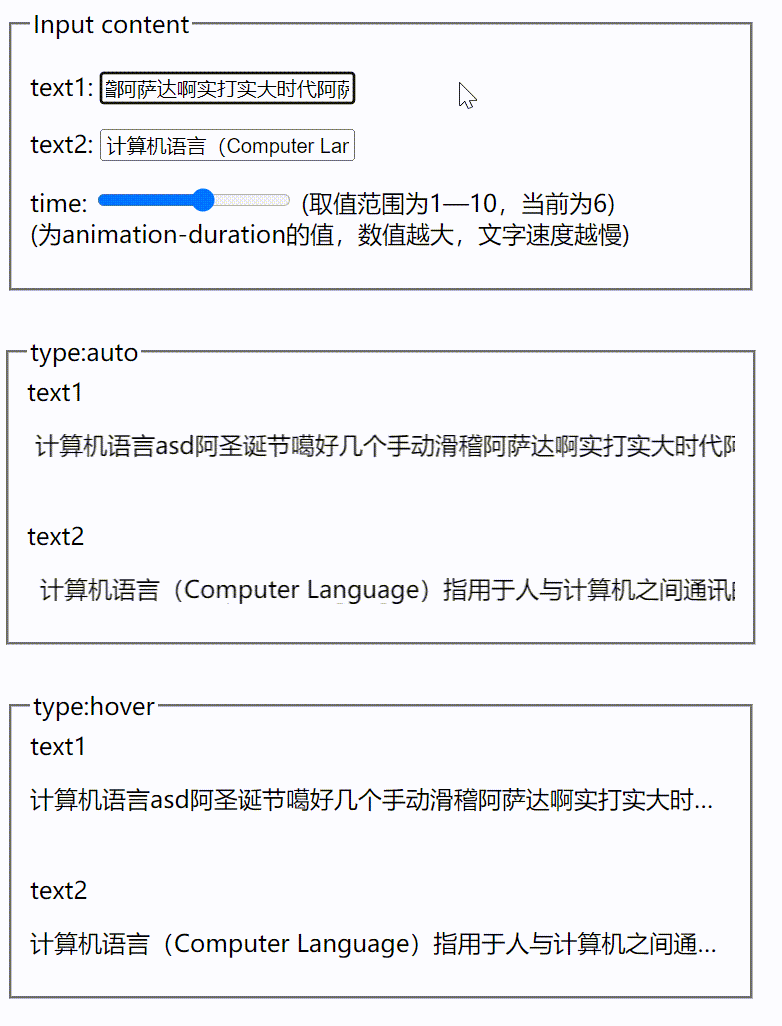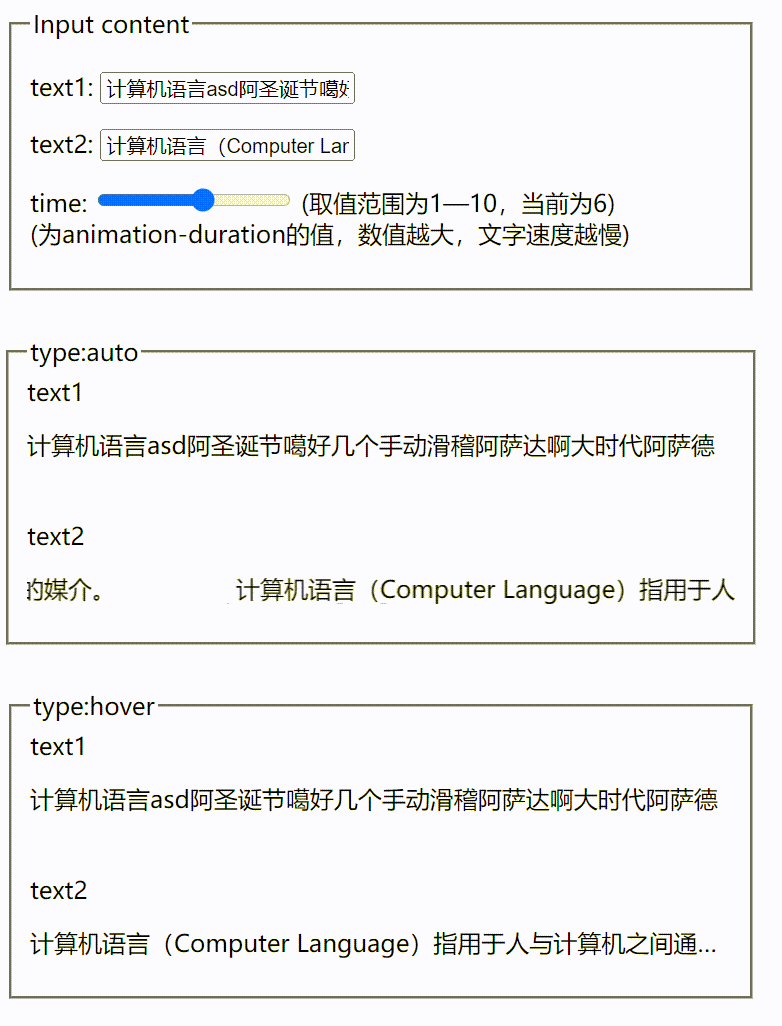
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径:AI代理工作流
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 大模型RAG性能提升路径
- langchain的基本使用
- 结合基础模型的大模型多源信息应用开发
- COT:大模型的强化利器
- 多角色大模型问答性能提升策略(附代码)
- 大模型接入外部在线信息提升应用性能
- 从零开始的Dify大模型应用开发指南
- 基于dify开发的多模态大模型应用(附代码)
- 基于零一万物多模态大模型通过外接数据方案优化图像文字抽取系统
- 快速接入stable diffusion的文生图能力
- 多模态大模型通过外接数据方案实现电力智能巡检(设计方案)
- 大模型prompt实例:知识库信息质量校验模块
- 基于Dify的LLM-RAG多轮对话需求解决方案(附代码)
- Dify大模型开发技巧:约束大模型回答范围
- 以API形式调用Dify项目应用(附代码)
- 基于Dify的QA数据集构建(附代码)
- Qwen-2-7B和GLM-4-9B:大模型届的比亚迪秦L
- 文擎毕昇和Dify:大模型开发平台模式对比
- Qwen-VL图文多模态大模型微调指南
- 从零开始的Ollama指南:部署私域大模型
- 基于Dify的智能分类方案:大模型结合KNN算法(附代码)
- OpenCompass:大模型测评工具
- 一文读懂多模态大模型基础架构
- 大模型管理平台:one-api使用指南
- 大模型RAG、ROG、RCG概念科普
- RAGOnMedicalKG:大模型结合知识图谱的RAG实现
- DSPy:变革式大模型应用开发
文章目录
- 大模型相关目录
- 开源项目
- 简介
- 简单特性
- 简单示例
- 复杂特性
- 复杂示例
- DSPy式大模型应用开发
开源项目
https://github.com/stanfordnlp/dspy
简介
据开源项目介绍:

通俗的说:
DSPy(Declarative Language Model Programming),指声明式语言模型编程,由斯坦福大学的研究人员开发,面向大模型RAG业务允许开发者专注于应用程序的高级逻辑,同时抽象掉许多低级细节。
简单特性
传统RAG工作流程:
收到查询
从知识库中检索相关信息
将检索到的信息与查询结合
大语言模型基于上述组合输入生成响应
相关开发者除去业务本身需求外,需对数据处理方式、知识库构建方式、查询方式、召回方式、多轮策略、召唤质量、模型应用配置等等细节进行设计。
DSPy为构建RAG系统引入了一种新范式,其几个关键优势如下:
声明式编程:DSPy允许开发者描述其希望系统做什么,而不是如何去做。这种高级方法使得设计和修改复杂的RAG流水线变得更加容易。
模块化架构:使用DSPy,可以轻松更换RAG系统的不同组件,例如检索器、排序器或语言模型,而无需重写大量代码。
自动优化:DSPy包含用于自动优化RAG流水线的工具,从而减少了手动调优并提高了整体性能。
无缝集成:DSPy可以与流行的语言模型进行无缝协作,并可轻松集成到现有的AI工作流中。
简单示例
import dspyclass RAG(dspy.Module):def __init__(self):self.retriever = dspy.Retrieve(k=3)self.generator = dspy.ChainOfThought("You are a helpful AI assistant.")def forward(self, query):context = self.retriever(query)response = self.generator(context=context, query=query)return responserag = RAG()
response = rag("What is the capital of France?")
print(response)
如上所示,DSPy在自身框架下进行初始化检索器和生成器,并给模型简单定位,即可实现RAG。
复杂特性
DSPy引入了以下一系列概念:
- 手写的prompt和fine-tune被抽象并替换为签名(Signature)
- 更高级的prompt技术,如Chain of Thought或ReAct,被抽象并替换为Modules。
- 手动prompt工程变为自动化的提示器(teleprompters)和DSPy编译器
复杂示例
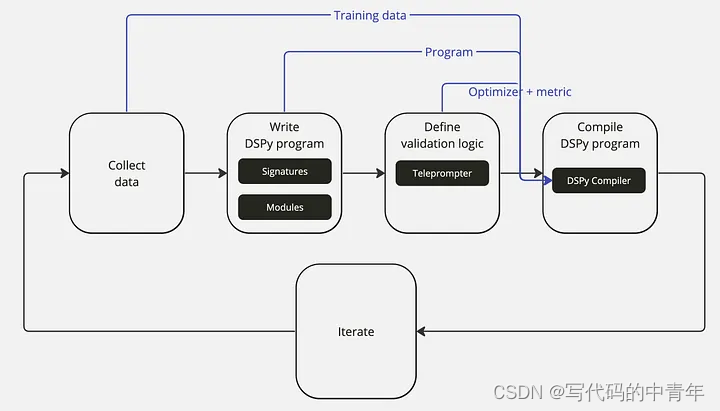
其开发流程可抽象为:
1. **数据集收集**:获取一系列程序输入和输出的示例,如问题和答案对,以用于优化pipelines的性能。
2. **编写DSPy程序**:使用Signature和Modules来定义程序的逻辑,并确定组件间的信息流,以便解决特定任务。
3. **定义验证逻辑**:创建一个验证过程,该过程包含用于评估程序性能的度量和优化器(提词器)。
4. **DSPy程序编译**:通过DSPy编译器整合训练数据、程序、优化器和验证度量,以优化程序性能,例如通过prompt或fine-tuning调整。
5. **迭代优化**:不断地改进数据质量、程序逻辑和验证过程,重复上述步骤,直至pipelines的性能达到令人满意的程度。
具体案例可见github、gitee指南文件。
DSPy式大模型应用开发
可见,DSPy实际是通过自身定义的机制和要素将大模型的RAG开发进行了一直简化、封装、自动化,提高了大模型应用开发的便捷性、增强了鲁棒性和泛化性、降低了开发门槛。
实际上,我们在进行其他大模型应用开发时,完全可以借鉴该思想。设计Agent模块面对用户的复杂提问时对问题进行分步拆解和规划。
角色定位: 本Agent是一个高级问题分解与规划助手,能够理解用户的复杂提问,并通过分步拆解和规划来提供解答。它利用了few-shot学习和思维链技巧来提高问题处理的准确性和效率。
角色职能:
接收并解析用户的复杂问题。
利用few-shot技巧从少量示例中快速学习并识别问题类型。
应用思维链技巧来逻辑地拆解问题,形成解答的步骤序列。
根据问题类型和上下文,规划解答的步骤和所需资源。
提供清晰、有序的问题解答或解决方案。
输出规范:
问题分析报告:包括问题类型、关键信息和子问题列表。
解答步骤规划:一系列分步的解答步骤,每个步骤都明确指出所需的行动或查询。
最终答案或解决方案:经过验证的答案,如果是解决方案,应包含实施步骤和预期结果。
注意事项:
确保在few-shot学习中使用的高质量示例能够代表用户可能提出的问题类型。
维护一个动态更新的知识库,以支持思维链技巧在问题拆解中的应用。
在规划解答步骤时,考虑用户的背景知识和期望的详细程度。
定期评估和优化输出规范,确保信息的准确性和实用性。
在处理用户数据时,严格遵守隐私保护和数据安全的相关法律法规。