你好,我是 shengjk1,多年大厂经验,努力构建 通俗易懂的、好玩的编程语言教程。 欢迎关注!你会有如下收益:
- 了解大厂经验
- 拥有和大厂相匹配的技术等
希望看什么,评论或者私信告诉我!
文章目录
- 一、前言
- 二、线程池
- 2.1 ScheduledThreadPool
- 2.1.1 ScheduledThreadPool 简介
- 2.1.2 ScheduledThreadPool 常用方法 scheduleAtFixedRate 和 scheduleWithFixedDelay 原理
- 2.1.3 scheduleAtFixedRate 和 scheduleWithFixedDelay 介绍
- 2.2 WorkStealingPool
- 2.2.1 WorkStealingPool 简介
- 2.2.2 ForkJoinPool 介绍
- 2.2.2.1 ForkJoinPool 介绍
- 2.2.2.2 ForkJoinPool 核心-工作窃取算法
- 2.2.2.2 ForkJoinPool 核心-工作窃取算法优缺点
- 2.2.2.3 ForkJoinPool 设计
- 2.2.2.4 ForkJoinPool 完整例子
- 三、总结
一、前言
上一章节我们详解介绍了SingleThreadExecutor 和 CachedThreadPool 的原理以及应用场景,本章我们继续介绍 ScheduledThreadPool 和 WorkStealingPool
二、线程池
2.1 ScheduledThreadPool
2.1.1 ScheduledThreadPool 简介
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor。它主要用来在给定的延迟之后运行任务,或者定期执行任务。
ScheduledThreadPoolExecutor的功能与Timer类似,但ScheduledThreadPoolExecutor功能更强大、更灵活。Timer对应的是单个后台线程,而ScheduledThreadPoolExecutor可以在构造函数中指定多个对应的后台线程数。
这是它的源码
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,new DelayedWorkQueue()); //调用 ThreadPoolExecutor}
2.1.2 ScheduledThreadPool 常用方法 scheduleAtFixedRate 和 scheduleWithFixedDelay 原理
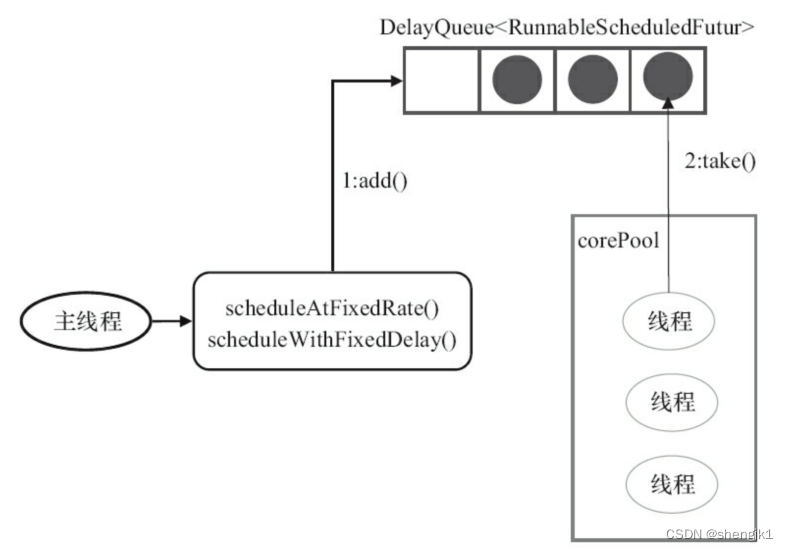
DelayQueue是一个无界队列,所以ThreadPoolExecutor的maximumPoolSize在ScheduledThreadPoolExecutor中没有什么意义(设置maximumPoolSize的大小没有什么效果)
- 当调用ScheduledThreadPoolExecutor的scheduleAtFixedRate()方法或者scheduleWithFixedDelay()方法时,会向ScheduledThreadPoolExecutor的DelayQueue添加一个实现了RunnableScheduledFutur接口的ScheduledFutureTask。
- 线程池中的线程从DelayQueue中获取ScheduledFutureTask,然后执行任务
2.1.3 scheduleAtFixedRate 和 scheduleWithFixedDelay 介绍
scheduleAtFixedRate 和 scheduleWithFixedDelay 都是 ScheduledExecutorService 接口中用于定时执行任务的方法,它们之间的区别在于任务执行的规则:
scheduleAtFixedRate方法会按照固定的频率执行任务,不考虑任务的实际执行时间。即使前一个任务执行花费的时间超过了频率时间,后续任务也会在规定的频率内执行。例如,如果设定间隔时间为3秒,但任务执行时间为5秒,则任务将按照5秒的间隔执行。scheduleWithFixedDelay方法会在前一个任务执行完成后的固定延迟时间后再执行下一个任务。即会等待上一个任务执行完成后才会执行下一个任务。例如,设定延迟时间为3秒,任务执行时间为5秒,则相邻两个任务之间的间隔时间为8秒(5秒执行任务 + 3秒延迟)。
通过选择合适的方法,可以根据实际需求来控制任务的执行规则。scheduleAtFixedRate 更适合需要固定频率执行任务的场景,而 scheduleWithFixedDelay 更适合需要等待前一个任务执行完成后再执行下一个任务的场景。
2.2 WorkStealingPool
2.2.1 WorkStealingPool 简介
WorkStealingPool 是 Java 中的一种线程池实现。WorkStealingPool 是 ForkJoinPool 的一个特例,具有以下特点:
- 工作窃取算法:WorkStealingPool 使用工作窃取算法(Work-Stealing Algorithm),每个工作者线程都有一个自己的双端队列用于存储任务,当一个线程的队列为空时,它可以从其他线程的队列中窃取任务来执行,以使工作负载均衡。
- 分治任务:WorkStealingPool 使用分治任务的方式来执行任务,可以高效地处理需要递归地分解任务的情况,例如在多核处理器系统中执行并行计算任务。
- 并行执行:WorkStealingPool 可以根据需要创建多个工作者线程来并行执行任务,适用于处理需要并行计算或处理的场景。
- 自动管理线程数:WorkStealingPool 可以根据需要动态地创建或关闭工作者线程,使得线程数能够根据任务情况和系统资源进行动态调整,提高性能和资源利用率。
由于 WorkStealingPool 使用工作窃取算法和分治任务的方式来执行任务,可以提高并行任务的执行效率和性能。在一些需要处理并行计算、递归分解任务或需要高效利用多核处理器的场景下,WorkStealingPool 是一个很好的选择。
它的源码实现
public static ExecutorService newWorkStealingPool() {return new ForkJoinPool(Runtime.getRuntime().availableProcessors(),ForkJoinPool.defaultForkJoinWorkerThreadFactory,null, true);
}
2.2.2 ForkJoinPool 介绍
2.2.2.1 ForkJoinPool 介绍
Fork/Join框架是Java 7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。
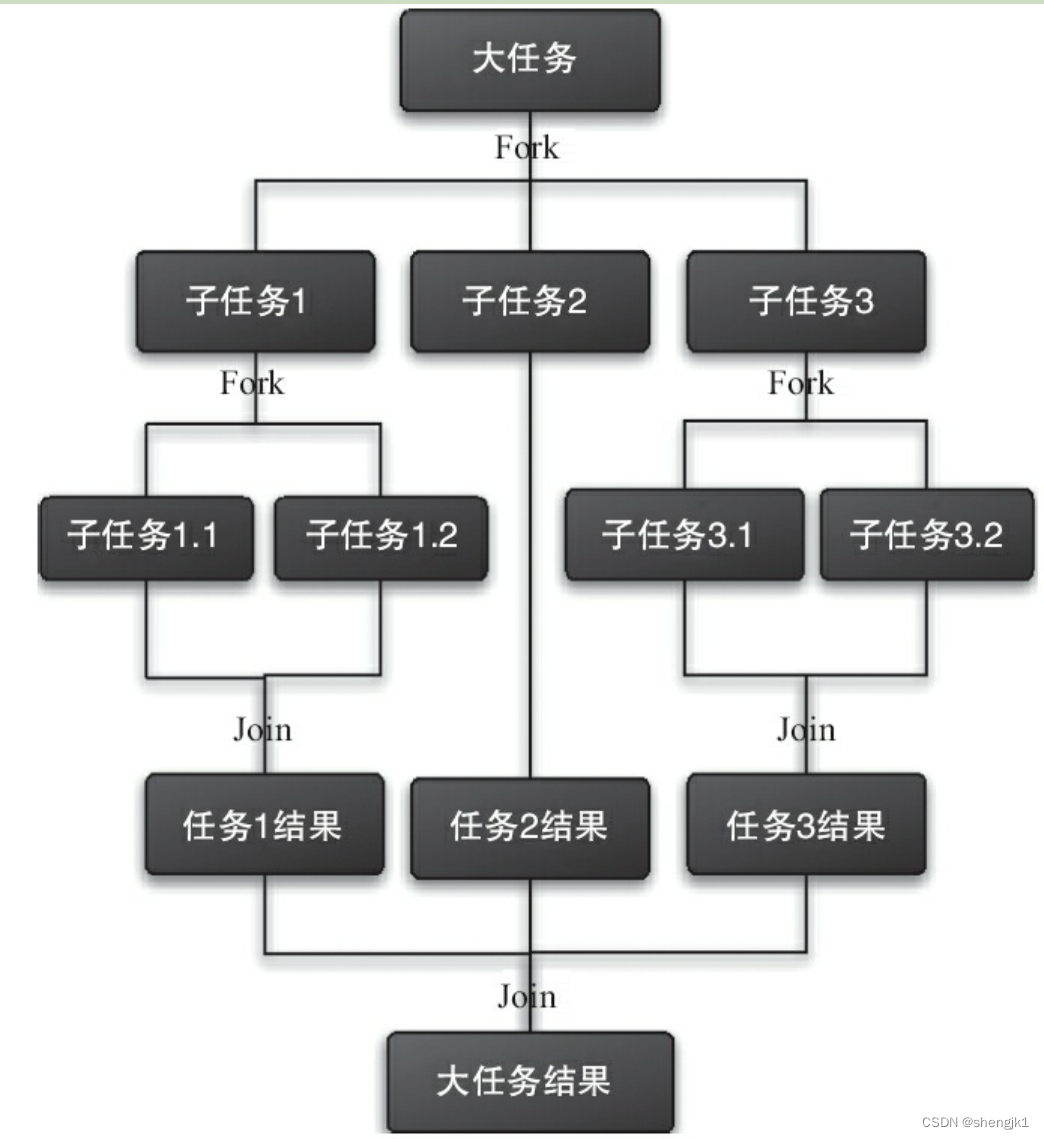
2.2.2.2 ForkJoinPool 核心-工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
假如我们需要做一个比较大的任务,可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。比如A线程负责处理A队列里的任务。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
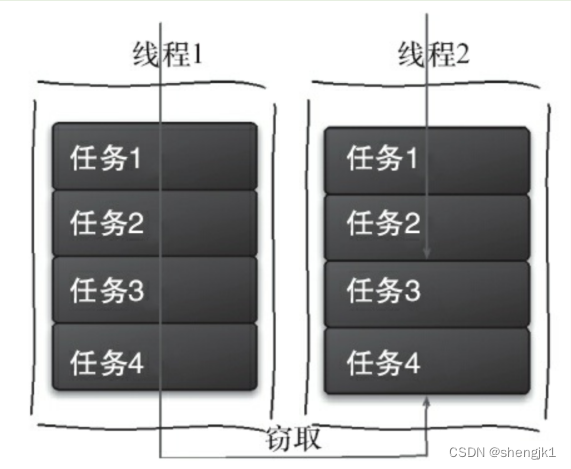
2.2.2.2 ForkJoinPool 核心-工作窃取算法优缺点
工作窃取(Work-Stealing)算法是一种用于线程池中任务调度的高效机制。以下是工作窃取算法的一些优点和缺点:
优点:
-
负载均衡:
- 工作窃取算法可以实现任务的动态负载均衡,当某些线程忙碌时,空闲线程可以从其他线程的队列中窃取任务执行,使得整体任务分配更加均衡。
-
减少竞争:
- 不同于传统的线程池中将任务分配给线程执行,工作窃取算法中线程会主动从其他线程的队列中获取任务执行,这减少了线程之间的争夺,降低了同步和竞争的开销。
-
提高效率:
- 工作窃取算法能够更好地利用多核处理器的特性,实现更高效的并发执行,尤其适用于大量计算密集型任务的并行处理。
-
适应动态性:
- 在任务执行过程中,工作窃取算法可以适应动态的负载情况,动态调整任务的分配,以更好地适应不同的任务执行情况。
缺点:
-
内存消耗:
- 由于工作窃取算法需要维护每个线程的工作队列,可能会增加额外的内存消耗,尤其是当线程数量较多时,需要维护多个队列。
-
数据局部性降低:
- 在工作窃取算法中,线程会从其他线程的队列中窃取任务执行,这可能导致数据在不同线程之间频繁传输,降低了数据局部性,影响缓存的效率。
-
竞争情况:
- 尽管工作窃取算法减少了线程之间的竞争,但在真实情况下,仍可能出现一些竞争状况,比如多个线程同时尝试窃取任务时可能会发生竞争。
-
复杂性:
- 实现工作窃取算法需要考虑到线程之间的协调和通信,这增加了算法的复杂性,可能需要更多的编程和调试工作。
尽管工作窃取算法有一些局限性,但在处理大规模并行任务时,它仍然是一种高效的任务调度算法,能够提高并行计算的效率和性能。
2.2.2.3 ForkJoinPool 设计
第一步 分割任务。首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还
是很大,所以还需要不停地分割,直到分割出的子任务足够小。
第二步 执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分
别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程
从队列里拿数据,然后合并这些数据。
Fork/Join使用两个类来完成以上两件事情:
ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务
中执行fork()和join()操作的机制。通常情况下,我们不需要直接继承ForkJoinTask类,只需要继
承它的子类,Fork/Join框架提供了以下两个子类。
- RecursiveAction:用于没有返回结果的任务。
- RecursiveTask:用于有返回结果的任务。
ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行。
任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当
一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任
务
2.2.2.4 ForkJoinPool 完整例子
class FibonacciTask extends RecursiveTask<Integer> {private final int n;public FibonacciTask(int n) {this.n = n;}@Overrideprotected Integer compute() {if (n <= 1) {return n;} else {FibonacciTask task1 = new FibonacciTask(n - 1);FibonacciTask task2 = new FibonacciTask(n - 2);task1.fork(); // 异步执行第一个子任务return task2.compute() + task1.join(); // 执行第二个子任务并等待第一个子任务完成}}
}public class FibonacciMain {public static void main(String[] args) {int n = 10; // 计算斐波那契数列的第n项ForkJoinPool forkJoinPool = new ForkJoinPool();FibonacciTask fibonacciTask = new FibonacciTask(n);int result = forkJoinPool.invoke(fibonacciTask);System.out.println("Fibonacci number at position " + n + " is: " + result);}
}
三、总结
文章重点在于阐述 ScheduledThreadPool 和 WorkStealingPool 的原理及应用。ScheduledThreadPool 适用于定时任务,而 WorkStealingPool 和 ForkJoinPool 适用于并行计算和分治任务,特别是能够充分利用多核 CPU 的计算能力。文章通过代码示例和图解,清晰地解释了这两种线程池的工作机制和优势