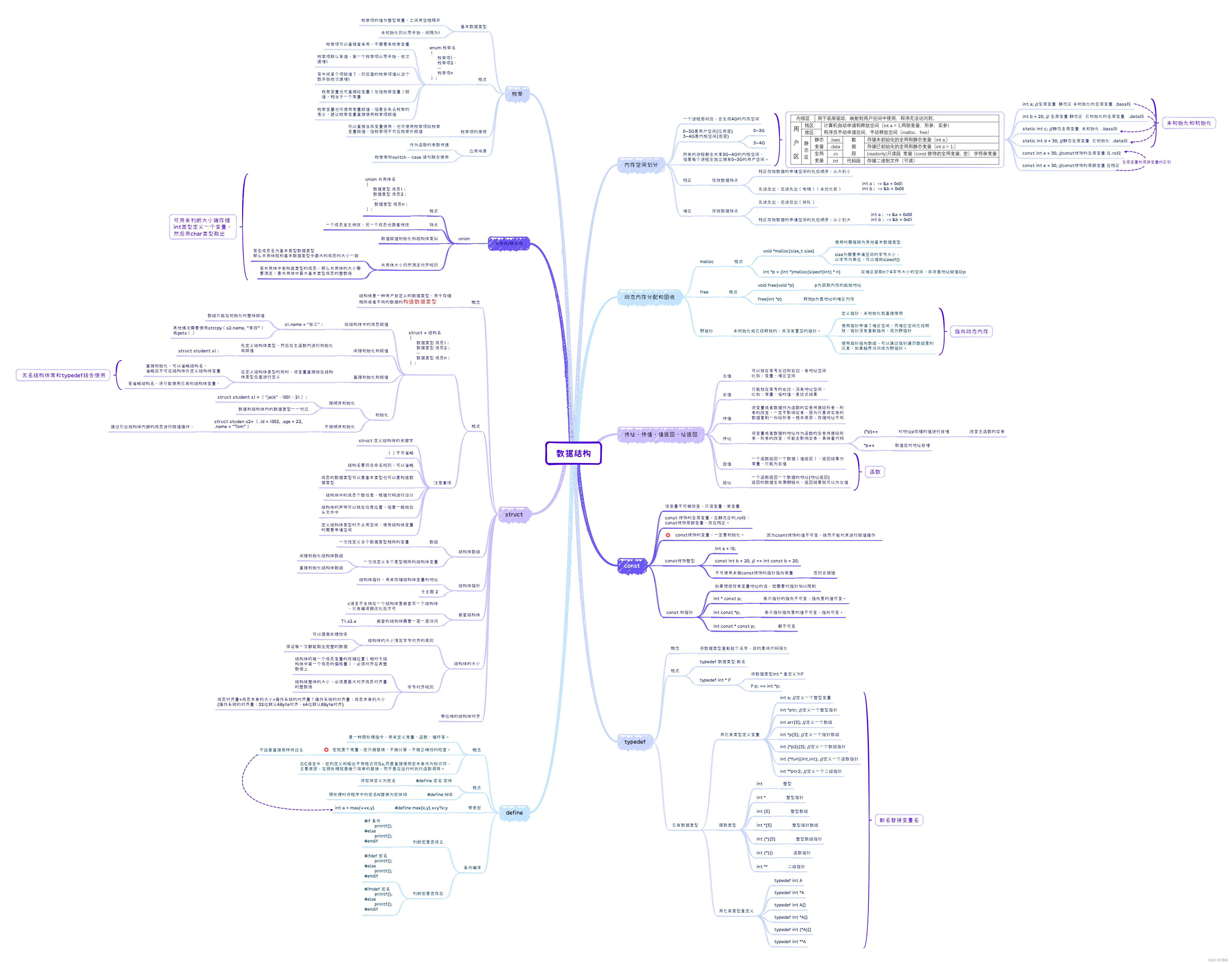
数据库导入导出表头

之前的工具类GenerateExcelToFile新增两个导出这种二级表头方法
package com.njry.utils;import cn.hutool.core.util.IdUtil;
import com.njry.config.FileProperties;
import com.njry.exception.BadRequestException;
import org.apache.poi.hssf.usermodel.HSSFCell;
import org.apache.poi.hssf.usermodel.HSSFRow;
import org.apache.poi.hssf.usermodel.HSSFSheet;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.ss.util.CellRangeAddress;
import org.apache.poi.util.IOUtils;
import org.apache.poi.xssf.usermodel.XSSFCell;
import org.apache.poi.xssf.usermodel.XSSFRow;
import org.apache.poi.xssf.usermodel.XSSFSheet;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.HashMap;
import java.util.List;
import java.util.Map;public class GenerateExcelToFile {public static final String SYS_TEM_DIR = System.getProperty("java.io.tmpdir") + File.separator;/*** 根据导出表在后面添加每个原子的基本值和目标值* @param list 数据库查询出来的信息* @param atomMbListAllString 后面动态添加的原子(要动态生成二级表头) 原子id,模版名称,维度名称三个用下划线分割,在导入的时候取数据用 例如:AT10681_0627-2_测试,AT10600_水电费debug_按开户厅* @param tableHead 基本表头 例如list 三个写死的表头:组织ID,组织名称,组织等级* @param type 导出的excel类型 1 xlsx 2 xls* @param response* @throws IOException*/public static void dataToExcel(List<Map<String, Object>> list, List<String> atomMbListAllString, List<String> tableHead, int type, HttpServletResponse response) throws IOException{String tempPath = SYS_TEM_DIR + IdUtil.fastSimpleUUID() + ".xlsx";File file = new File(tempPath);Workbook wb = null;if(type == 1){wb = new XSSFWorkbook();}if(type == 2){wb = new HSSFWorkbook();}Workbook exportWorkbook = exportMultiExcel(wb, list, atomMbListAllString, tableHead, type);
// 临时文件 写出流FileOutputStream outStream = new FileOutputStream(file);// 写入Workbook到文件exportWorkbook.write(outStream);
// 也可以通过流获取大小
// long size = outStream.getChannel().size();// 强制刷新文件流,确保所有数据都被写入到文件中outStream.flush();outStream.close();//response为HttpServletResponse对象response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet;charset=utf-8");//test.xls是弹出下载对话框的文件名,不能为中文,中文请自行编码response.setHeader("Content-Disposition", "attachment;filename=file.xlsx");ServletOutputStream out = response.getOutputStream();FileInputStream fileInputStream = new FileInputStream(file);IOUtils.copy(fileInputStream,out);file.deleteOnExit();fileInputStream.close();}/**** @param wb 操作的Workbook* @param list 数据库查询出来的信息* @param atomMbListAllString 后面动态添加的原子(要动态生成二级表头)* @param tableHead 基本表头* @param type 导出的excel类型 1 xlsx 2 xls* @return*/public static Workbook exportMultiExcel(Workbook wb,List<Map<String, Object>> list, List<String> atomMbListAllString, List<String> tableHead, int type){HSSFWorkbook HSSwb = null;XSSFWorkbook XSSwb = null;if(type == 1){XSSwb = (XSSFWorkbook)wb;}if(type == 2){HSSwb = (HSSFWorkbook)wb;}// 创建样式CellStyle style = wb.createCellStyle();style.setAlignment(HorizontalAlignment.CENTER); // 水平居中style.setVerticalAlignment(VerticalAlignment.CENTER); // 垂直居中if(type == 1){XSSFSheet sheet = XSSwb.createSheet();
// 处理sheet的表头
// XSSFRow row = sheet.createRow((short) 0);(表头两行)
// 合并第一行和第二行的第一个单元格
// int startrow = 0;
// int endrow = 1;
// int startcell = 1;
// int endcell = 1;
// sheet.addMergedRegion(new CellRangeAddress(startrow, endrow, startcell, endcell));// 处理表头(合并第一行和第二行)XSSFRow row = sheet.createRow((short) 0);XSSFRow row1 = sheet.createRow((short) 1);int size = tableHead.size();//固定表头长度for (int i = 0; i < size; i++) {int startrow = 0;int endrow = 1;int startcell = i;int endcell = i;
// 在合并单元格第一个写内容XSSFCell cell = row.createCell(i);cell.setCellValue(tableHead.get(i));sheet.addMergedRegion(new CellRangeAddress(startrow, endrow, startcell, endcell));cell.setCellStyle(style);}int asyncSize = atomMbListAllString.size() * 2;//动态表头长度for (int j = size; j < asyncSize+size; j += 2) {int startrow = 0;int endrow = 0;int startcell = j;int endcell = j + 1;
// 在合并单元格第一个写内容XSSFCell cell = row.createCell(j);int circulationNum = (j - size) / 2;//循环次数cell.setCellValue(atomMbListAllString.get(circulationNum));
// 合并第二行写固定的基本值和目标值XSSFCell cellMerge1 = row1.createCell(j);cellMerge1.setCellValue("基本值");XSSFCell cellMerge2 = row1.createCell(j+1);cellMerge2.setCellValue("目标值");sheet.addMergedRegion(new CellRangeAddress(startrow, endrow, startcell, endcell));cellMerge1.setCellStyle(style);cellMerge2.setCellStyle(style);cell.setCellStyle(style);}
// 写入数据(固定表头下面内容)for (int m = 0; m < list.size(); m++) {
// 已经添加的两个行XSSFRow rowTemp = sheet.createRow(m + 2);
// 每一行数据的map,map对应的key就是固定表头Map<String, Object> stringObjectMap = list.get(m);Cell dataCell = null;for (int n = 0; n < tableHead.size(); n++) {dataCell = rowTemp.createCell(n);dataCell.setCellValue(StringUtils.notEmpty(stringObjectMap.get(tableHead.get(n))));}}}if(type == 2){HSSFSheet sheet = HSSwb.createSheet();
// 处理sheet的表头
// XSSFRow row = sheet.createRow((short) 0);(表头两行)
// 合并第一行和第二行的第一个单元格
// int startrow = 0;
// int endrow = 1;
// int startcell = 1;
// int endcell = 1;
// sheet.addMergedRegion(new CellRangeAddress(startrow, endrow, startcell, endcell));// 处理表头(合并第一行和第二行)HSSFRow row = sheet.createRow((short) 0);HSSFRow row1 = sheet.createRow((short) 1);int size = tableHead.size();//固定表头长度for (int i = 0; i < size; i++) {int startrow = 0;int endrow = 1;int startcell = i;int endcell = i;
// 在合并单元格第一个写内容HSSFCell cell = row.createCell(i);cell.setCellValue(tableHead.get(i));sheet.addMergedRegion(new CellRangeAddress(startrow, endrow, startcell, endcell));cell.setCellStyle(style);}int asyncSize = atomMbListAllString.size() * 2;//动态表头长度for (int j = size; j < asyncSize+size; j += 2) {int startrow = 0;int endrow = 1;int startcell = j;int endcell = j + 1;
// 在合并单元格第一个写内容HSSFCell cell = row.createCell(j);int circulationNum = (j - size) / 2;//循环次数cell.setCellValue(atomMbListAllString.get(circulationNum));
// 合并第二行写固定的基本值和目标值HSSFCell cellMerge1 = row1.createCell(j);cellMerge1.setCellValue("基本值");HSSFCell cellMerge2 = row1.createCell(j+1);cellMerge2.setCellValue("目标值");sheet.addMergedRegion(new CellRangeAddress(startrow, endrow, startcell, endcell));cellMerge1.setCellStyle(style);cellMerge2.setCellStyle(style);cell.setCellStyle(style);}
// 写入数据(固定表头下面内容)for (int m = 0; m < list.size(); m++) {
// 已经添加的两个行HSSFRow rowTemp = sheet.createRow(m + 2);
// 每一行数据的map,map对应的key就是固定表头Map<String, Object> stringObjectMap = list.get(m);Cell dataCell = null;for (int n = 0; n < tableHead.size(); n++) {dataCell = rowTemp.createCell(n);dataCell.setCellValue(StringUtils.notEmpty(stringObjectMap.get(tableHead.get(n))));}}}return wb;}/**** @param list 数据库查询出来的信息* @param tableHead 数据库的表头(简单表头)* @param dirPath 保存的文件路径* @param fileSuffix 生成的excel格式后缀* @param separator 生成的excel带水印格要多加一层文件路径* @throws IOException*/public static Map<String, Object> dataToExcel(List<Map<String, Object>> list,List<String> tableHead,String dirPath, String fileSuffix, String separator) throws IOException {Map<String, Object> resultMap = new HashMap<>();Workbook wb = null;FileInputStream tempInput = null;String watermarkPath = dirPath + "watermarkPath" + separator;int type = 3;//默认用type区分一个sheet有多少行if("xlsx".equals(fileSuffix)){wb = new XSSFWorkbook();type = 1;}if("xls".equals(fileSuffix)){wb = new HSSFWorkbook();type = 2;}Workbook exportWorkbook = export(wb, list, tableHead, type);String attachmentId = IdUtil.simpleUUID();String fileSize = "";String to_file_name = attachmentId + "." + fileSuffix; // 结果文件名称
// 判断保存的文件路径是否存在,不存在就创建File outFileExist = new File(dirPath);if(!outFileExist.exists()){outFileExist.mkdirs();}File outFile = new File(dirPath, to_file_name);try {FileOutputStream outStream = new FileOutputStream(outFile);// 写入Workbook到文件exportWorkbook.write(outStream);
// 也可以通过流获取大小
// long size = outStream.getChannel().size();// 强制刷新文件流,确保所有数据都被写入到文件中outStream.flush();// 获取文件对象File outputFile = new File(dirPath, to_file_name);long length = outputFile.length();fileSize = length + " bytes";outStream.close();} catch (Exception e) {throw new BadRequestException("导出结果文件异常:" + e);}// 将有数据的excel的文件再加水印File tempFile = new File(dirPath, to_file_name);tempInput = new FileInputStream(tempFile);XSSFWorkbook xSSFWorkbook = new XSSFWorkbook(tempInput);
// 将导出的数据加水印放到另一个文件watermarkPath里面File watermarkFileExist = new File(watermarkPath, to_file_name);PoiSecurity.addWatermarkToXlsx(new String[]{"test"},xSSFWorkbook,watermarkFileExist);xSSFWorkbook.close();tempInput.close();// 终止后删除临时文件tempFile.deleteOnExit();
// 处理文件信息返回resultMap.put("attachmentId",attachmentId);resultMap.put("fileName",to_file_name);resultMap.put("fileType","excel");resultMap.put("fileExtension",fileSuffix);resultMap.put("fileSize",fileSize);resultMap.put("attachmentPath",dirPath);return resultMap;}/**** @param wb 操作的Workbook* @param list 数据库查询出来的信息* @param tableHead 数据库的表头(简单表头)* @param type excel类型 xlsx 1 xls 2 -------区分sheet最大告诉* @return*/public static Workbook export(Workbook wb,List<Map<String, Object>> list, List<String> tableHead,int type) {HSSFWorkbook HSSwb = null;XSSFWorkbook XSSwb = null;
// 不定义sheet名字,自生成
// Excel 2003及更早的版本中,行数上限是65,536行
// 2007开始,行数上限增加到了1,048,576行int maxRow = 49999;//去除一个表头行if(type == 1){maxRow = 1048575;//去除一个表头行XSSwb = (XSSFWorkbook)wb;}if(type == 2){maxRow = 65535;//去除一个表头行HSSwb = (HSSFWorkbook)wb;}maxRow = 49999;//去除一个表头行(无论啥格式默认都是50000一个sheet)
// 处理数据需要多少个sheetint size = list.size();int result = size / maxRow + 1;if(result == 0){result = 1;}
// 循环sheetfor (int i = 0; i < result; i++) {if(type == 1){XSSFSheet sheet = XSSwb.createSheet();// 处理每个sheet的表头XSSFRow row = sheet.createRow((short) 0);Cell cell = null;for (int j = 0; j < tableHead.size(); j++) {cell = row.createCell(j);
// cell.setCellStyle(headStyle);cell.setCellValue(tableHead.get(j));}
// 写入数据for (int n = 0 + maxRow * i; n < maxRow * (i + 1); n++) {
// 判断数据list的大小是否大于要创建的行if(size - 1 >= n ){//下面list.get(n)就取不到数据,不应该继续创建行 size 14 get(n)时候 n只能到13row = sheet.createRow(n % maxRow + 1);Cell dataCell = null;for (int m = 0; m < tableHead.size(); m++) {dataCell = row.createCell(m);dataCell.setCellValue(StringUtils.notEmpty(list.get(n).get(tableHead.get(m))));}}}}if(type == 2){HSSFSheet sheet = HSSwb.createSheet();// 处理每个sheet的表头HSSFRow row = sheet.createRow((short) 0);Cell cell = null;for (int j = 0; j < tableHead.size(); j++) {cell = row.createCell(j);
// cell.setCellStyle(headStyle);cell.setCellValue(tableHead.get(j));}
// 写入数据for (int n = 0 + maxRow * i; n < maxRow * (i + 1); n++) {
// 判断数据list的大小是否大于要创建的行if(size - 1 >= n ){//下面list.get(n)就取不到数据,不应该继续创建行 size 14 get(n)时候 n只能到13row = sheet.createRow(n % maxRow + 1);Cell dataCell = null;for (int m = 0; m < tableHead.size(); m++) {dataCell = row.createCell(m);dataCell.setCellValue(StringUtils.notEmpty(list.get(n).get(tableHead.get(m))));}}}}}return wb;}
}处理之前导出的模板,把用户输入的基本值和目标值再放回数据库里
解析excel保存到表里(贴一个实现层代码)
@Override@Transactional(rollbackFor = Exception.class)public void excelImportBatch(MultipartFile file,Long sceneId,String month) throws Exception {
// 保存在 T_ATOM_MB_CFG_ITEM 但是需要目标值,
// 前端传了场景id,以及excel里面原子id_模式名称_维度名称 有atomId,模式名称,维度名称
// 因此要根据atomId,模式名称,维度名称以及场景id 获取目标idString extension = file.getOriginalFilename().substring(file.getOriginalFilename().lastIndexOf(".") + 1).toLowerCase(); // 获取输入流try (java.io.InputStream fis = file.getInputStream();Workbook workbook = "xlsx".equals(extension) ? new XSSFWorkbook(fis) : new HSSFWorkbook(fis);){Sheet sheet = workbook.getSheetAt(0);//获取Sheet中的合并单元格信息(为下文HeaderCell下属性判断使用)HeaderRegion[] headerRegions = new HeaderRegion[sheet.getNumMergedRegions()];for(int k = 0; k < sheet.getNumMergedRegions(); k++){HeaderRegion headerRegion = null;CellRangeAddress region = sheet.getMergedRegion(k);headerRegion = new HeaderRegion();int firstRow = region.getFirstRow();int lastRow = region.getLastRow();int firstColumn = region.getFirstColumn();int lastColumn = region.getLastColumn();headerRegion.setTargetRowFrom(firstRow);headerRegion.setTargetRowTo(lastRow);headerRegion.setTargetColumnFrom(firstColumn);headerRegion.setTargetColumnTo(lastColumn);Cell cell = sheet.getRow(firstRow).getCell(firstColumn);headerRegion.setText(cell.getStringCellValue());headerRegion.setColLength(1 + (lastColumn - firstColumn));headerRegion.setRowLength(1 + (lastRow - firstRow));headerRegions[k] = headerRegion;}
// 找到不是基础表头的合并单元格(前三列是基础数据表头合并单元格,要获取后面动态生成的合并单元格)int size = 0;//后面动态生成的个数int sizeLength = 0;//动态占用列数int baseSize = 0;//基础表头Map<String,List<AtomMbCfgItem>> map = new LinkedHashMap<>();//key放动态生成的目标id(一个映射表)Map<Integer,String> cellMap = new LinkedHashMap<>();//key列对应的目标id(一个映射表,方便下面循环excel的列时候找到所属的目标id)for(HeaderRegion item : headerRegions){
// 同一列,基础表头if(item.getTargetColumnFrom() == item.getTargetColumnTo()){baseSize++;}else{size++;sizeLength += item.getColLength();int targetColumnFrom = item.getTargetColumnFrom();int targetColumnTo = item.getTargetColumnTo();String text = item.getText();String[] nameText = text.split("_");String atomId = nameText[0];//atomIdString modeName = nameText[1];//模式名称String dimenName = nameText[2];//维度名称
// T_ATOM_MB_CFG表里的mb_id 是numberList<AtomMbCfg> atomMbCfgs = atomMbCfgMapper.queryMBId(sceneId, atomId, modeName, dimenName);if(atomMbCfgs == null || atomMbCfgs.size() == 0){throw new BadRequestException("导入的目标不对,可能不是当前场景的模版");}AtomMbCfg atomMbCfg = atomMbCfgs.get(0);String mbId = atomMbCfg.getMbId();cellMap.put(targetColumnFrom,mbId);cellMap.put(targetColumnTo,mbId);List<AtomMbCfgItem> temp = new ArrayList<>();map.put(mbId,temp);}}String orgid=null;String orgName="";int orglevel= -1;String orglevelName="";int baseval= 0;int chalval= 0;// 必输验证提示信息StringBuffer error = new StringBuffer();// 遍历数据行(这里知道是从第三行是实际数据行)for (int i = 2; i <= sheet.getLastRowNum(); i++){int n = i + 1;//实际行数(显示报错用的)StringBuffer err = new StringBuffer();Row row = sheet.getRow(i);if (row == null)continue;orgid = row.getCell(0).toString().trim();if(orgid.length() == 0){err.append("\r\n第[" + n + "]行"+ 1 +"列没有值!");}orgName = row.getCell(1).toString().trim();//获取也存入表里if(orgName.length() == 0){err.append("\r\n第[" + n + "]行"+ 2 +"列没有值!");}orglevelName = row.getCell(2).toString().trim();if(orglevelName.length() == 0){err.append("\r\n第[" + n + "]行"+ 3 +"列没有值!");}
// 不循环数据固定表头,直接上面写死for (int j = 3; j < baseSize+sizeLength; j += 2) {String mbId = cellMap.get(j);//获取动态表头的目标idList<AtomMbCfgItem> atomMbCfgItems = map.get(mbId);//当前目标id的列表AtomMbCfgItem atomMbCfgitem = new AtomMbCfgItem();String basevalStr = row.getCell(j).toString().trim();if(basevalStr.endsWith(".0")){basevalStr = basevalStr.substring(0, basevalStr.length() - 2);baseval = Integer.parseInt(basevalStr);}String chalvalStr = row.getCell(j+1).toString().trim();if(chalvalStr.endsWith(".0")){chalvalStr = chalvalStr.substring(0, chalvalStr.length() - 2);chalval = Integer.parseInt(chalvalStr);}
// baseval = Integer.parseInt(basevalStr);
// chalval = Integer.parseInt(chalvalStr);if(baseval < 0){err.append("\r\n第[" + n + "]行"+ j+1 +"列数据为负数!");}if(chalval < 0){err.append("\r\n第[" + n + "]行"+ j+2 +"列为负数!");}// 为啥还要获取一遍,不用excel里面的值 根据组织名称和组织等级获取组织id并不唯一
// select * from t_report_org_template_1
// where org_name='党政军组' and
// org_level= 3
// orgid= atomMbCfgMapper.selectOrgIdByName(orgName,orglevelName,atomMbCfgcx.getAtomId());atomMbCfgitem.setMbId(mbId);atomMbCfgitem.setMonth(month);if(orgid!=null && !orgid.isEmpty()){atomMbCfgitem.setOrgId(orgid);}// 在t_atom_template_level只有原子是tempalte_id 是1的才能获取到组织层级 先写死1 查询组织层级
// List<Integer> integers = atomMbCfgMapper.selectOrgLevel(orglevelName, atomMbCfgcx.getAtomId());
//
// if(integers.size()>0){
// orglevel = integers.get(0);
// atomMbCfgitem.setOrgLevel(orglevel);
// }else{
// err.append("\r\n第[" + n + "]无对应组织level,请检查!");
// }// 根据组织名称和 先写死的模版id 是1 查找组织等级Integer integer = atomMbCfgMapper.selectOrgLevelByorglevelNameTemplateId(orglevelName, "1");atomMbCfgitem.setOrgLevel(integer);atomMbCfgitem.setBaseVal(baseval);atomMbCfgitem.setChalVal(chalval);atomMbCfgitem.setCreateBy(SecurityUtils.getCurrentUsername());atomMbCfgitem.setCreateTime(new Date());if ("".equals(err.toString())){atomMbCfgItems.add(atomMbCfgitem);}else{error.append(err);error.append("\r\n请修改!");throw new BadRequestException(error.toString());}}}for (String key : map.keySet()) {List<AtomMbCfgItem> atomMbCfgItems = map.get(key);System.out.println(key + " :" + atomMbCfgItems);atomMbCfgMapper.saveItam(atomMbCfgItems);}// 文件流关闭fis.close();}}




![【代码随想录】【算法训练营】【第53天】 [739]每日温度 [496]下一个更大元素I [503]下一个更大元素II](https://img-blog.csdnimg.cn/direct/dc822ea1a9594d8cbf6c44499afb43e3.png)