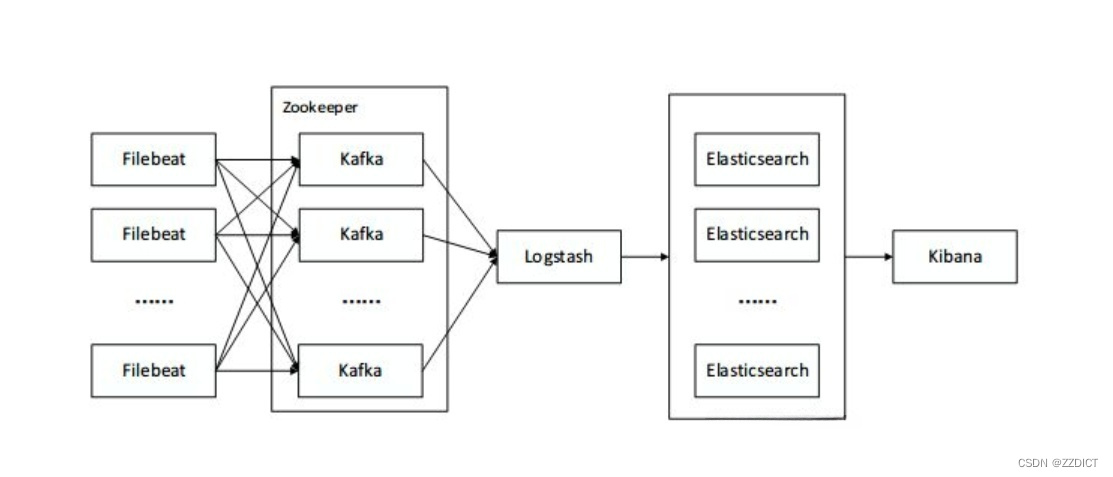
目录
上篇:Elasticsearch集群部署(上)-CSDN博客
七. Filebeat 部署
八. 部署Kafka
九. 集群测试
链接:https://pan.baidu.com/s/1AFXSmDdY5xBb7g35ipKoaw?pwd=fa9m
提取码:fa9m
七. Filebeat 部署
为什么用 Filebeat ,而不用原来的 Logstash 呢?
原因很简单,资源消耗比较大。
由于 Logstash 是跑在 JVM 上面,资源消耗比较大,后来作者用 GO 写了一个功能较少但是资源消耗也小的轻量级的 Agent 叫 Logstash-forwarder。
后来作者加入 elastic.co 公司, Logstash-forwarder 的开发工作给公司内部 GO 团队来搞,最后命名为 Filebeat。
Filebeat 需要部署在每台应用服务器上,可以通过 Salt 来推送并安装配置。
新增一台虚拟机参照如下配置并进行初始化操作
软件版本 filebeat-7.13.2-x86_64.rpm
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| filebeat | filebeat | 192.168.226.27 | Rocky_linux9.4 | 1核2G |
修改主机名
#对192.168.226.27主机操作
[root@localhost ~]# hostnamectl set-hostname filebeat关闭防火墙和selinux,进行时间同步,IP固定,初始化脚本可以用上集里的配置。
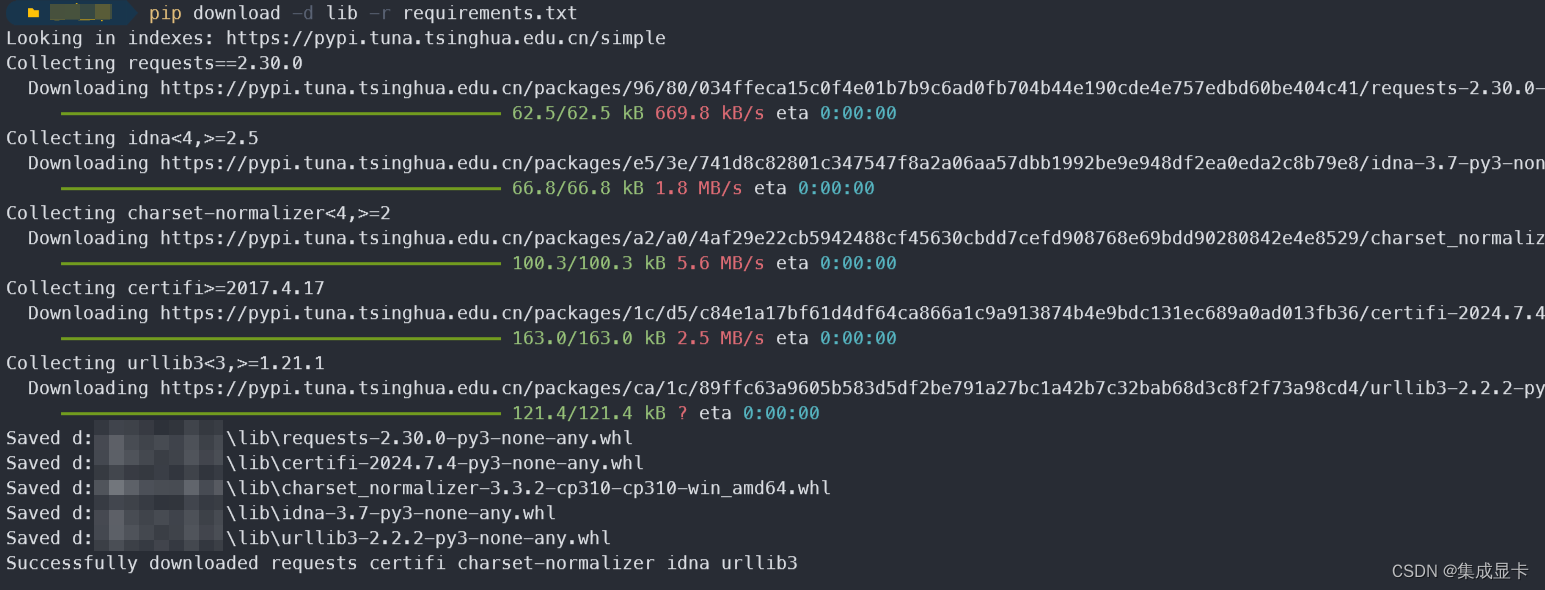
1. 下载安装包
[root@filebeat ~]# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.2-x86_64.rpm这个安装命令也可以在kibana页面找到 主页>添加数据>nginx日志>RPM

2. 安装
[root@filebeat ~]# yum install -y filebeat-7.13.2-x86_64.rpm
3. 修改配置filebate 传输给 logstash
在上篇最后我们配置logstash收集nginx日志,这里就只需要修改filebate配置即可。
[root@filebeat ~]# vim /etc/filebeat/filebeat.yml 修改下述Filebeat inputs,Logstash Output,将Elasticsearch Output配置里全部注释
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/dnf.log
output.logstash:hosts: ["192.168.226.23:5044"]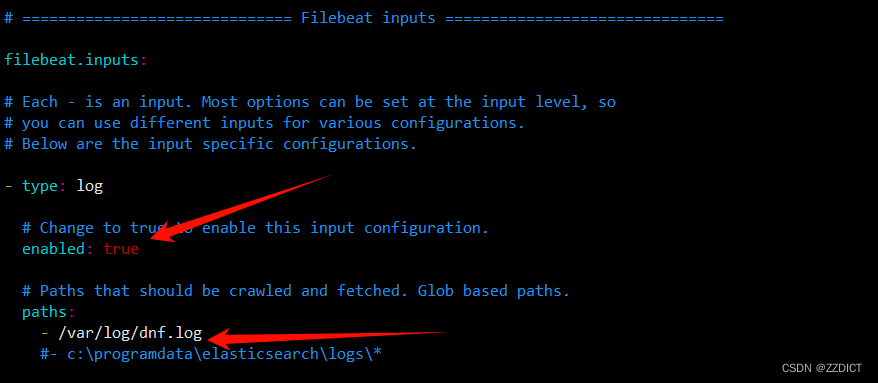

现在回到192.168.226.23主机,修改stdin.conf和stdout.conf文件
先停止logstash服务,再修改配置
[root@nginx ~]# vim /usr/local/logstash-7.13.2/conf/stdin.conf
input {beats {port => 5044}
}
filter {grok {match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} %{GREEDYDATA:message}" }}date {match => ["timestamp", "yyyy-MM-dd'T'HH:mm:ssZZ"]}
}
[root@nginx ~]# vim /usr/local/logstash-7.13.2/conf/stdout.confoutput {stdout {codec => rubydebug}elasticsearch {hosts => ["192.168.226.20","192.168.226.21","192.168.226.22"]index => 'dnf_log-%{+YYYY-MM-dd}'}
}
再次启动logstash
[root@nginx ~]# cd /usr/local/logstash-7.13.2
[root@nginx logstash-7.13.2]# ./bin/logstash -f conf/
4. 启动filebeat主机
[root@filebeat ~]# systemctl enable --now filebeat启动后切换到nginx主机,即192.168.226.23,看输出信息:
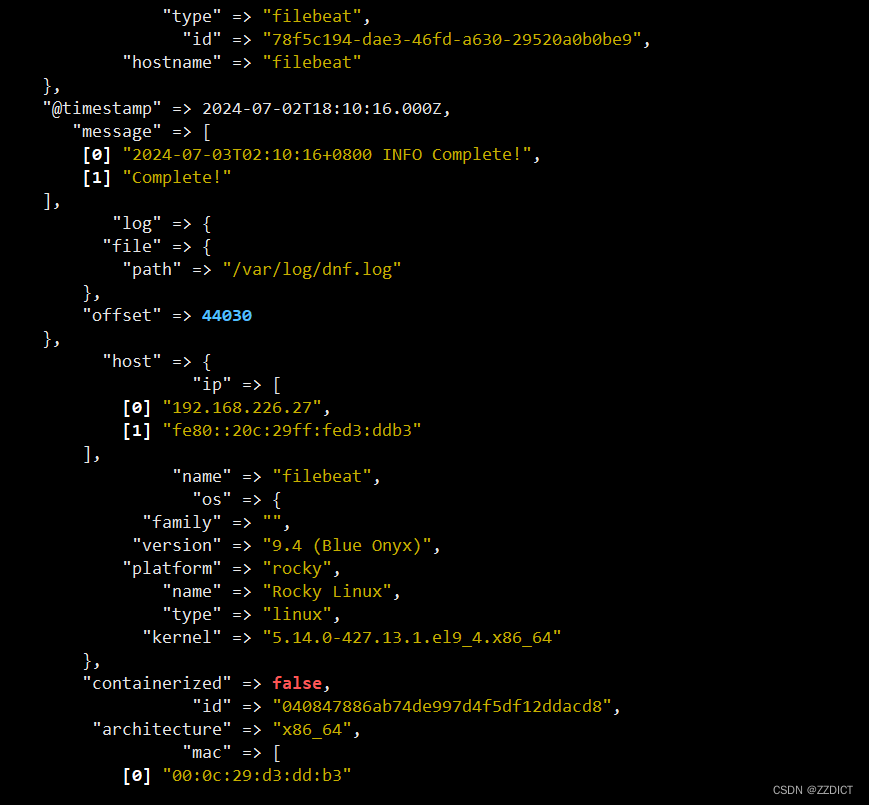
这样就是成功收集并处理了
5. 查看kibana的web页面
6. 创建索引

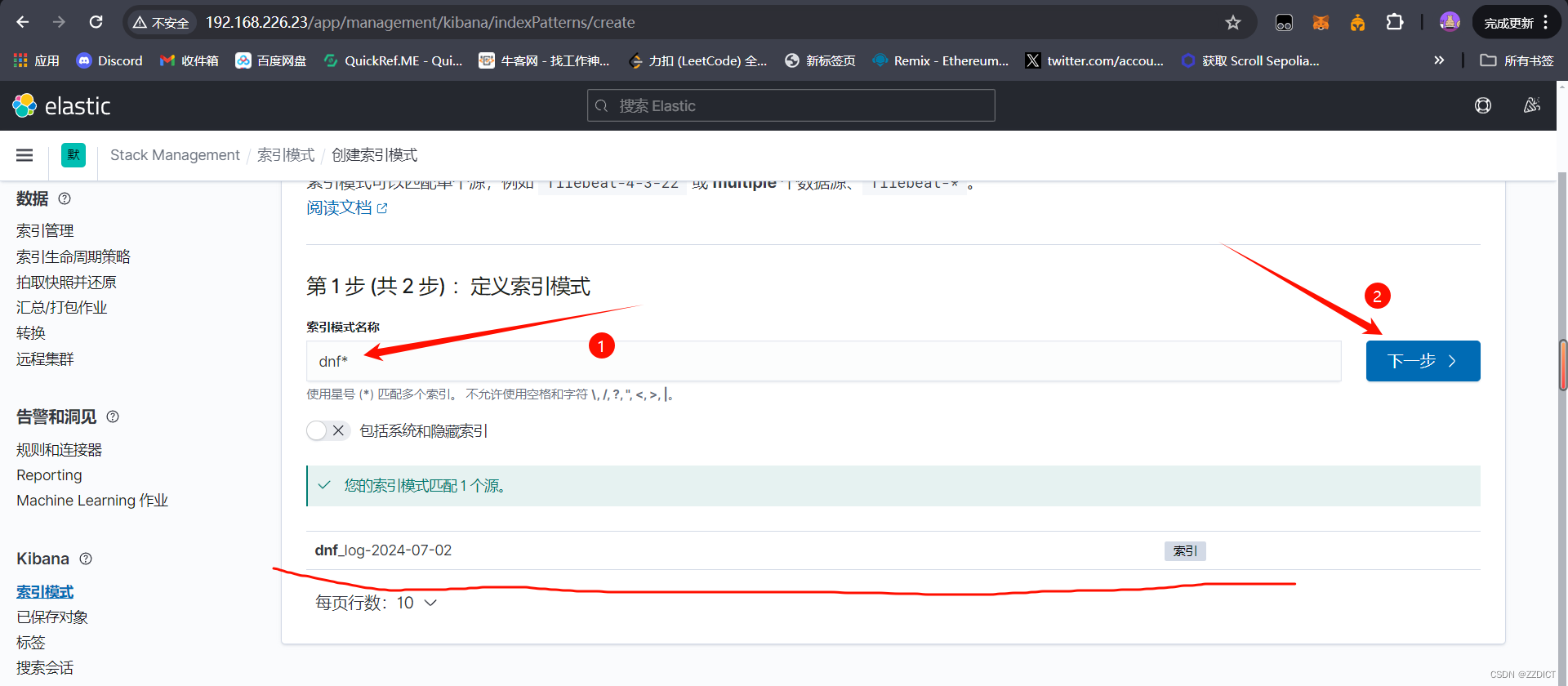
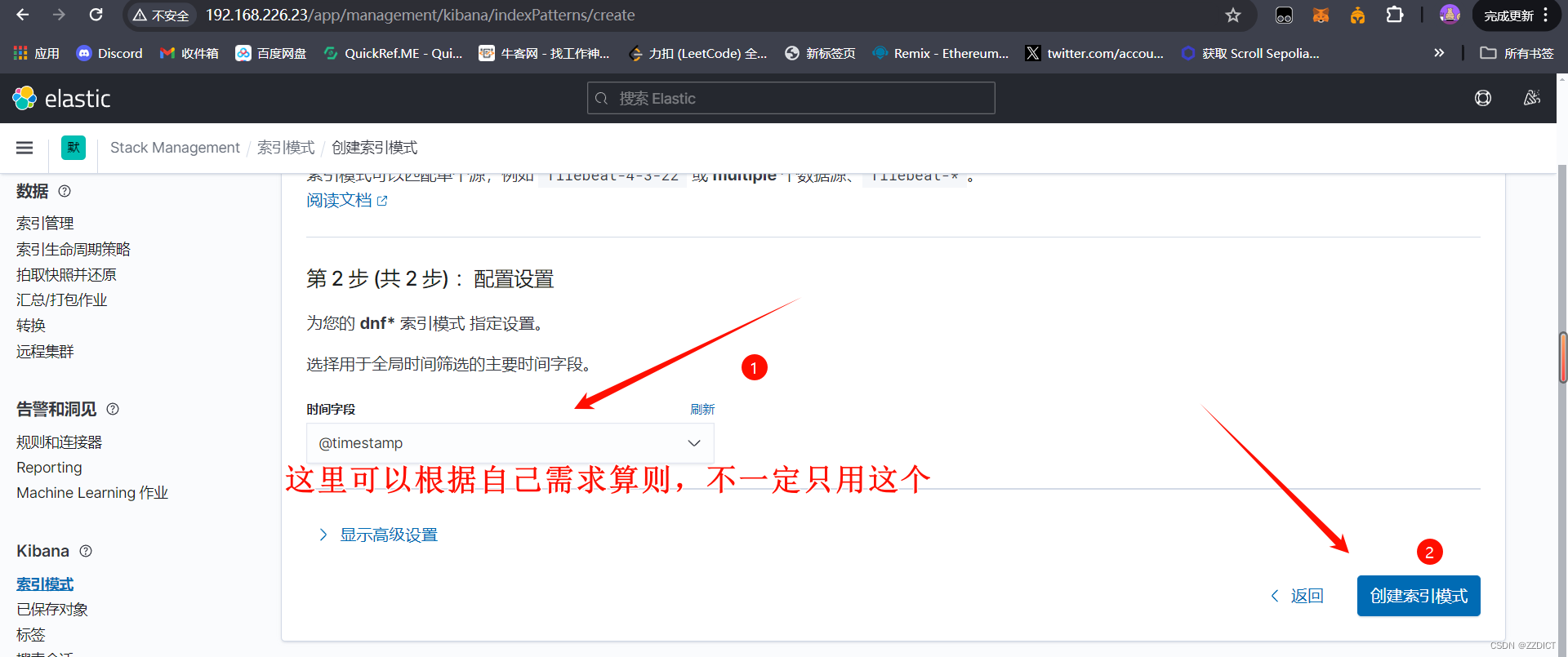

Filebeat只有输出和输出,需要安装在需要收集的应用主机中,它没有Logstash的过滤能力,但是可以通过Filebeat收集再输入给Logstash处理后再发送给ES集群存储,以上就是完成了通过Filebeat收集后转发给Logstash处理步骤。
7. 下载安装Filebeat收集ES的日志
打开Kibana官方配置文档参考

切换到es1主机,即192.168.226.20主机
下载并安装
[root@es1 ~]# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.2-x86_64.rpm
[root@es1 ~]# sudo rpm -vi filebeat-7.13.2-x86_64.rpm8. 配置Filebeat
参考修改
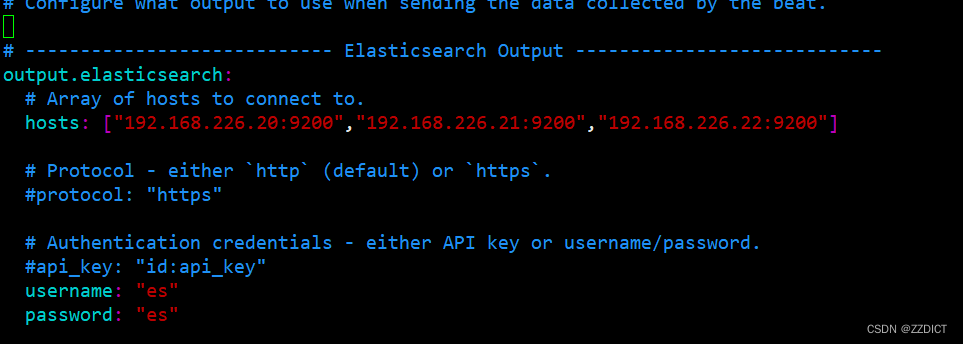
[root@es1 ~]# vim /etc/filebeat/filebeat.yml
setup.kibana:host: "192.168.226.20:5601"
output.elasticsearch:hosts: ["192.168.226.20:9200","192.168.226.21:9200","192.168.226.22:9200"]username: "es"password: "es"

9. 启用和配置 elasticsearch 模块
[root@es1 ~]# sudo filebeat modules enable elasticsearch打开这里配置文档第二行的链接是一个官方配置文档
Elasticsearch module | Filebeat Reference [7.13] | Elastic
根据文档提示,选择要收集的日志,并配置正确的该类型日志路径,不想收集的类型可以选择可以配置false即可。
[root@es1 ~]# vim /etc/filebeat/modules.d/elasticsearch.yml
# Module: elasticsearch
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.13/filebeat-module-elasticsearch.html- module: elasticsearch# Server logserver:enabled: true# Set custom paths for the log files. If left empty,# Filebeat will choose the paths depending on your OS.var.paths:- /data/elasticsearch/logs/*.log- /data/elasticsearch/logs/*_server.jsongc:enabled: true# Set custom paths for the log files. If left empty,# Filebeat will choose the paths depending on your OS.var.paths:- /data/elasticsearch/logs/gc.log.[0-9]*- /data/elasticsearch/logs/gc.logaudit:enabled: true# Set custom paths for the log files. If left empty,# Filebeat will choose the paths depending on your OS.var.paths:- /data/elasticsearch/logs/*_access.log- /data/elasticsearch/logs/*_audit.jsonslowlog:enabled: true# Set custom paths for the log files. If left empty,# Filebeat will choose the paths depending on your OS.var.paths:- /data/elasticsearch/logs/*_index_search_slowlog.log- /data/elasticsearch/logs/*_index_indexing_slowlog.log- /data/elasticsearch/logs/*_index_search_slowlog.json- /data/elasticsearch/logs/*_index_indexing_slowlog.jsondeprecation:enabled: true# Set custom paths for the log files. If left empty,# Filebeat will choose the paths depending on your OS.var.paths:- /data/elasticsearch/logs/*_deprecation.log- /data/elasticsearch/logs/*_deprecation.json 
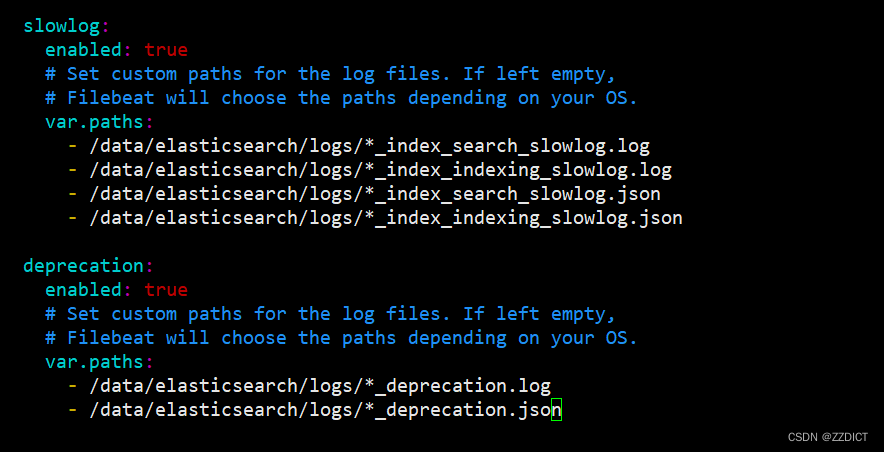
10. 启动 Filebeat
setup 命令加载 Kibana 仪表板。如果仪表板已设置,就省略此命令。
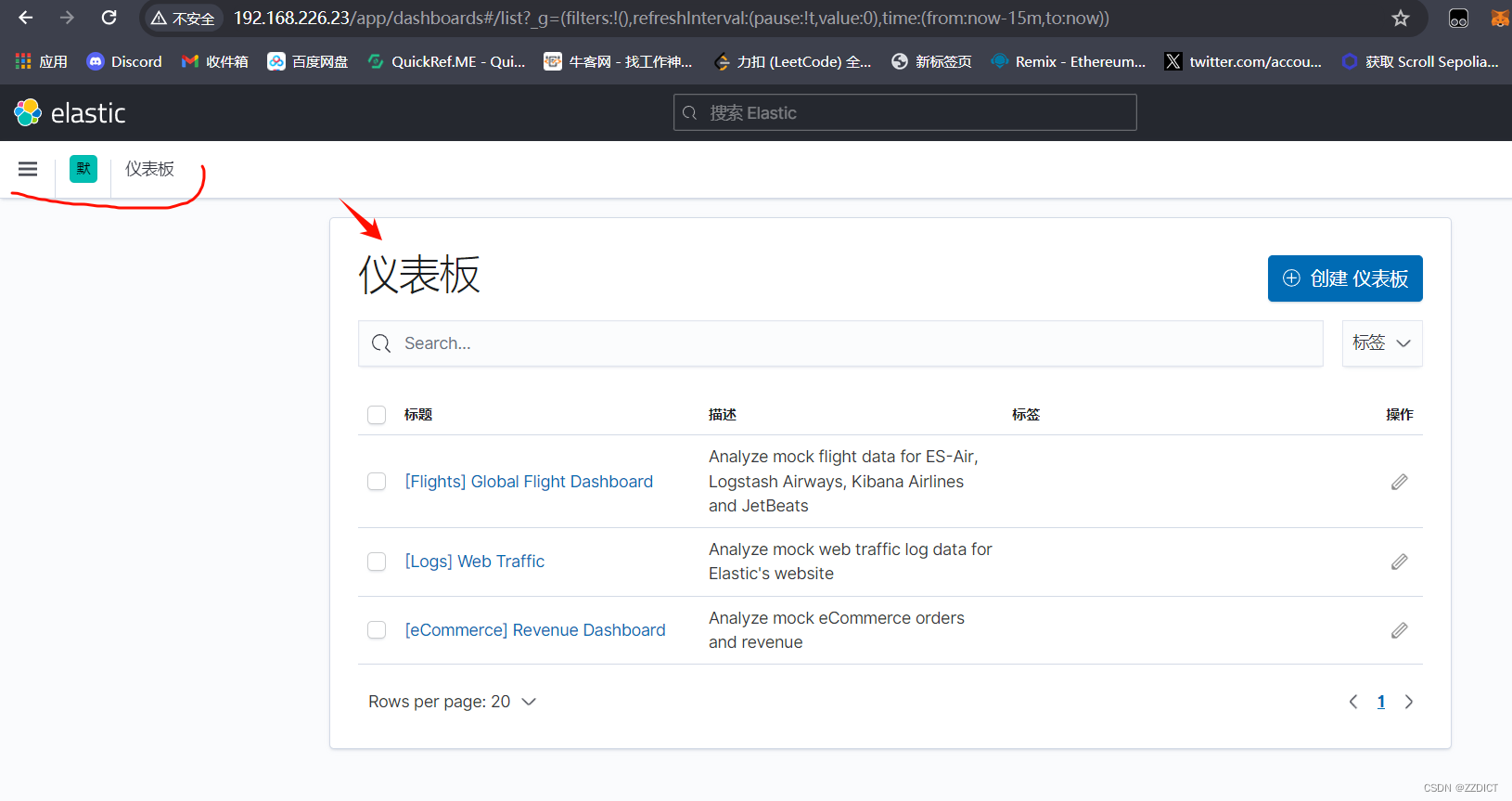
这里我也没有显示,因此我也要执行加载仪表盘命令,执行后等待一会即可。
[root@es1 ~]# sudo filebeat setup刷新后看仪表盘加载出来了多条

#使用systemctl方式启动,因为版本问题,不要使用service filebeat start去启动
[root@es1 ~]# systemctl start filebeat11. 检查数据
回到Kibana得web页面,在配置得操作文档中点击检查数据,这个会帮你检查是否成功。

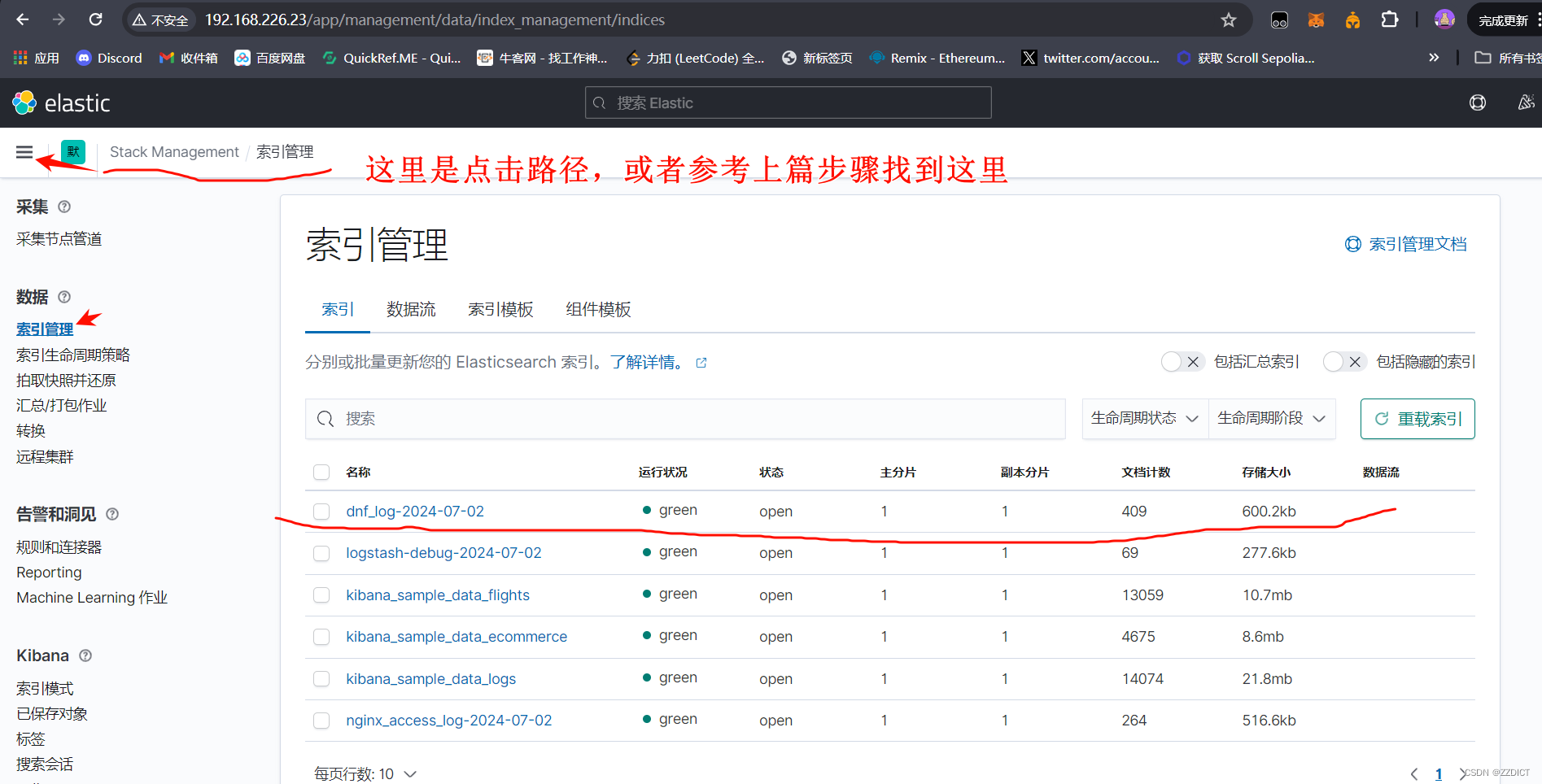
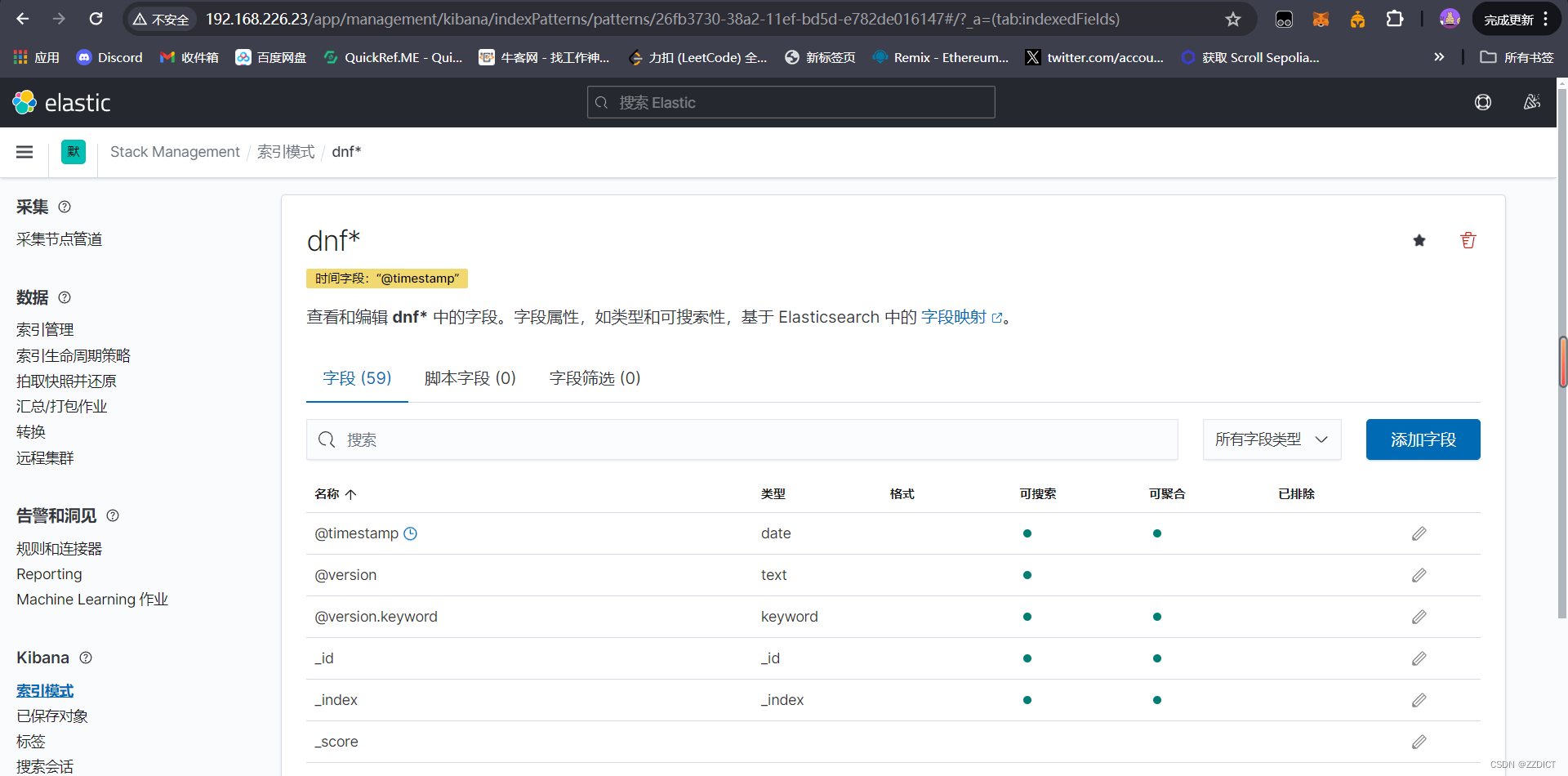
12. 创建索引
来到索引管理可以看到我们刚收集到得日志
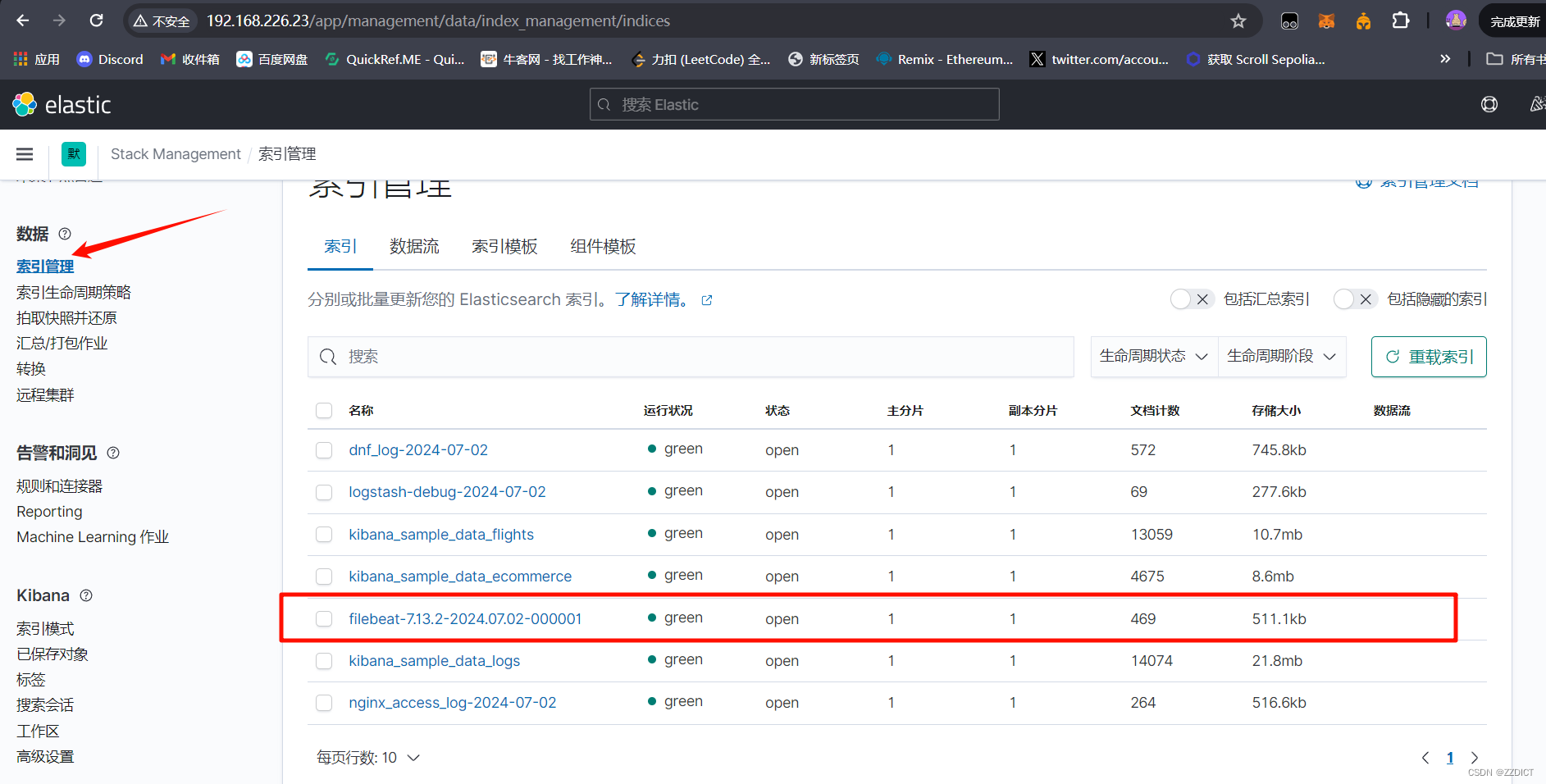
现在去创建索引


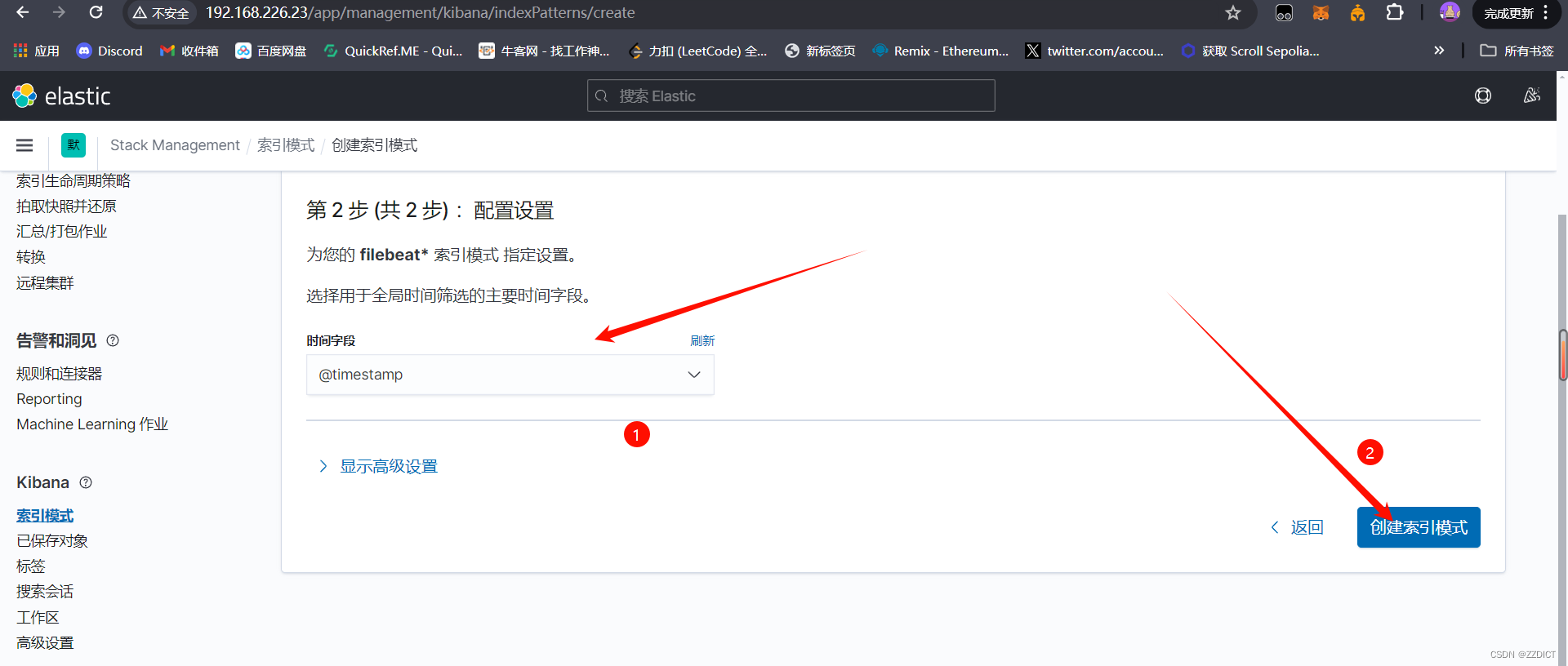

这种方式就是通过Filebeat中得input和output直接收集ES日志并输出到ES集群中,并用Filebeat加载了一下Kibana的仪表盘,通过Kibana展示数据。
八. 部署Kafka
新增三台虚拟机参照如下配置并进行初始化操作
软件版本:jdk-8u211-linux-x64.tar.gz、kafka_2.11-2.0.0.tgz
| 安装软件 | 主机名 | IP地址 | 系统版本 | 配置 |
|---|---|---|---|---|
| zookeeper/kafka | Kafka1 | 192.168.226.24 | Rocky_linux9.4 | 1核2G |
| zookeeper/kafka | Kafka2 | 192.168.226.25 | Rocky_linux9.4 | 1核2G |
| zookeeper/kafka | Kafka3 | 192.168.226.26 | Rocky_linux9.4 | 1核2G |
修改主机名
#对192.168.226.24主机操作
[root@localhost ~]# hostnamectl set-hostname Kafka1#对192.168.226.25主机操作
[root@localhost ~]# hostnamectl set-hostname Kafka2#对192.168.226.26主机操作
[root@localhost ~]# hostnamectl set-hostname Kafka3关闭防火墙和selinux,进行时间同步,IP固定,初始化脚本可以用上集里的配置。
1. 上传安装jdk8,三台Kafka都安装
[root@Kafka1 ~]# ll
total 244884
-rw-------. 1 root root 815 Jun 6 14:00 anaconda-ks.cfg
-rw-r--r-- 1 root root 194990602 Jul 2 20:11 jdk-8u211-linux-x64.tar.gz
-rw-r--r-- 1 root root 55751827 Jul 2 11:39 kafka_2.11-2.0.0.tgz
-rw-r--r--. 1 root root 4747 Jun 24 19:46 rocky_linux.sh
[root@Kafka1 ~]# tar -zxvf jdk-8u211-linux-x64.tar.gz -C /usr/local/
[root@Kafka1 ~]# echo '
JAVA_HOME=/usr/local/jdk1.8.0_211
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME PATH
' >>/etc/profile
[root@Kafka1 ~]# source /etc/profile
[root@Kafka1 ~]# java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)
2. 安装配置ZK,三台Kafka都安装
Kafka运行依赖ZK,Kafka官网提供的tar包中,已经包含了ZK,这里不再额下载ZK程序。
[root@Kafka1 ~]# ll
total 244884
-rw-------. 1 root root 815 Jun 6 14:00 anaconda-ks.cfg
-rw-r--r-- 1 root root 194990602 Jul 2 20:11 jdk-8u211-linux-x64.tar.gz
-rw-r--r-- 1 root root 55751827 Jul 2 11:39 kafka_2.11-2.0.0.tgz
-rw-r--r--. 1 root root 4747 Jun 24 19:46 rocky_linux.sh
下面这个配置文件中,kafka集群IP:Port .1为id 3处要对应
[root@Kafka1 ~]# tar -zxvf kafka_2.11-2.0.0.tgz -C /usr/local/
[root@Kafka1 ~]# echo '
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=192.168.226.24:2888:3888
server.2=192.168.226.25:2888:3888
server.3=192.168.226.26:2888:3888
'> /usr/local/kafka_2.11-2.0.0/config/zookeeper.properties配置项含义:
dataDir ZK数据存放目录。
dataLogDir ZK日志存放目录。
clientPort 客户端连接ZK服务的端口。
tickTime ZK服务器之间或客户端与服务器之间维持心跳的时间间隔。
initLimit 允许follower(相对于Leaderer言的“客户端”)连接并同步到Leader的初始化连接时间,以tickTime为单位。当初始化连接时间超过该值,则表示连接失败。
syncLimit Leader与Follower之间发送消息时,请求和应答时间长度。如果follower在设置时间内不能与leader通信,那么此follower将会被丢弃。
server.1=192.168.226.24:2888:3888 2888是follower与leader交换信息的端口,3888是当leader挂了时用来执行选举时服务器相互通信的端口。#创建data、log目录
[root@kafka1 ~]# mkdir -p /opt/data/zookeeper/{data,logs}
#创建myid文件,每个节点的id不一样对192.168.226.24
[root@Kafka1 ~]# echo 1 > /opt/data/zookeeper/data/myid对192.168.226.25
[root@Kafka2 ~]# echo 2 > /opt/data/zookeeper/data/myid对192.168.226.26
[root@Kafka3 ~]# echo 3 > /opt/data/zookeeper/data/myid创建log目录
[root@Kafka1 ~]# mkdir -p /opt/data/kafka/logs3. 配置Kafka,这里三台虚拟机要主机配置中的IP
参考参数解释去修改你对应的broker.id和listeners
[root@Kafka1 ~]# echo '
broker.id=1
listeners=PLAINTEXT://192.168.226.24:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.226.24:2181,192.168.226.25:2181,192.168.226.26:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
' >/usr/local/kafka_2.11-2.0.0/config/server.properties配置项含义:
broker.id 每个server需要单独配置broker id,如果不配置系统会自动配置。
listeners 监听地址,格式PLAINTEXT://IP:端口。
num.network.threads 接收和发送网络信息的线程数。
num.io.threads 服务器用于处理请求的线程数,其中可能包括磁盘I/O。
socket.send.buffer.bytes 套接字服务器使用的发送缓冲区(SO_SNDBUF)
socket.receive.buffer.bytes 套接字服务器使用的接收缓冲区(SO_RCVBUF)
socket.request.max.bytes 套接字服务器将接受的请求的最大大小(防止OOM)
log.dirs 日志文件目录。
num.partitions partition数量。
num.recovery.threads.per.data.dir 在启动时恢复日志、关闭时刷盘日志每个数据目录的线程的数量,默认1。
offsets.topic.replication.factor 偏移量话题的复制因子(设置更高保证可用),为了保证有效的复制,偏移话题的复制因子是可配置的,在偏移话题的第一次请求的时候可用的broker的数量至少为复制因子的大小,否则要么话题创建失败,要么复制因子取可用broker的数量和配置复制因子的最小值。
log.retention.hours 日志文件删除之前保留的时间(单位小时),默认168
log.segment.bytes 单个日志文件的大小,默认1073741824
log.retention.check.interval.ms 检查日志段以查看是否可以根据保留策略删除它们的时间间隔。
zookeeper.connect ZK主机地址,如果zookeeper是集群则以逗号隔开。
zookeeper.connection.timeout.ms 连接到Zookeeper的超时时间。4. 启动、验证ZK集群,三台都启动
[root@Kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@Kafka1 kafka_2.11-2.0.0]# nohup bin/zookeeper-server-start.sh config/zookeeper.properties &
5. 检查三台ZK状态
在三个节点依次执行:
[root@Kafka1 kafka_2.11-2.0.0]# yum -y install nmap lsof
#查看ZK配置
[root@Kafka1 kafka_2.11-2.0.0]# echo conf | nc 127.0.0.1 2181
clientPort=2181
dataDir=/opt/data/zookeeper/data/version-2
dataLogDir=/opt/data/zookeeper/logs/version-2
tickTime=2000
maxClientCnxns=60
minSessionTimeout=4000
maxSessionTimeout=40000
serverId=1
initLimit=20
syncLimit=10
electionAlg=3
electionPort=3888
quorumPort=2888
peerType=0#查看ZK状态
[root@Kafka1 kafka_2.11-2.0.0]# echo stat |nc 127.0.0.1 2181
Zookeeper version: 3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 00:39 GMT
Clients:/127.0.0.1:57044[0](queued=0,recved=1,sent=0)Latency min/avg/max: 0/0/0
Received: 2
Sent: 1
Connections: 1
Outstanding: 0
Zxid: 0x100000000
Mode: follower
Node count: 4#查看端口
[root@Kafka1 kafka_2.11-2.0.0]# lsof -i:2181
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 3753 root 95u IPv6 34970 0t0 TCP *:eforward (LISTEN)6. 启动Kafka
在三个节点依次执行:
[root@kafka1 ~]# cd /usr/local/kafka_2.11-2.0.0/
[root@kafka1 ~]# nohup bin/kafka-server-start.sh config/server.properties &7. 验证Kafka
在192.168.226.24上创建topic
[root@Kafka1 kafka_2.11-2.0.0]# bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testtopic查询192.168.226.24上的topic
[root@Kafka1 kafka_2.11-2.0.0]# bin/kafka-topics.sh --zookeeper 192.168.226.24:2181 --list查询192.168.226.25上的topic
[root@Kafka2 kafka_2.11-2.0.0]# bin/kafka-topics.sh --zookeeper 192.168.226.25:2181 --list查询192.168.226.26上的topic
[root@Kafka3 kafka_2.11-2.0.0]# bin/kafka-topics.sh --zookeeper 192.168.226.26:2181 --list
模拟消息生产和消费
发送消息到192.168.226.24
[root@Kafka1 kafka_2.11-2.0.0]# bin/kafka-console-producer.sh --broker-list 192.168.226.24:9092 --topic testtopic
>hello
>word!
>hi who are you 从192.168.226.25接受消息
[root@Kafka2 kafka_2.11-2.0.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.226.25:9092 --topic testtopic --from-beginning
hello
word!
hi who are you8.监控 Kafka Manager
Kafka-manager 是 Yahoo 公司开源的集群管理工具。
可以在 Github 上下载安装:GitHub - yahoo/CMAK: CMAK is a tool for managing Apache Kafka clusters
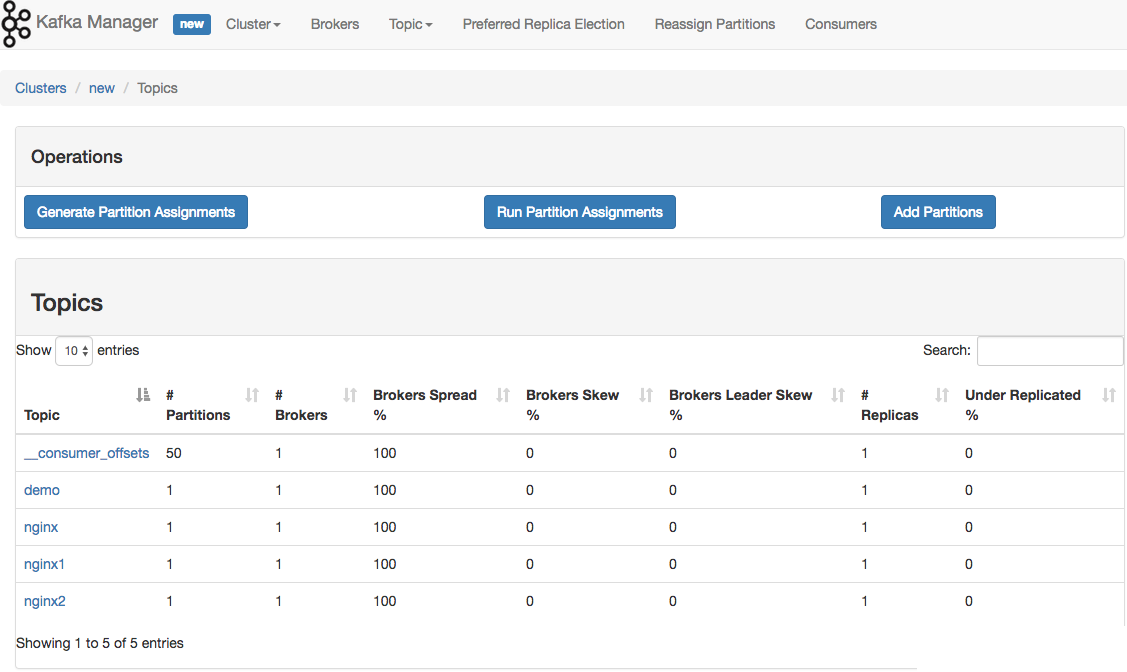
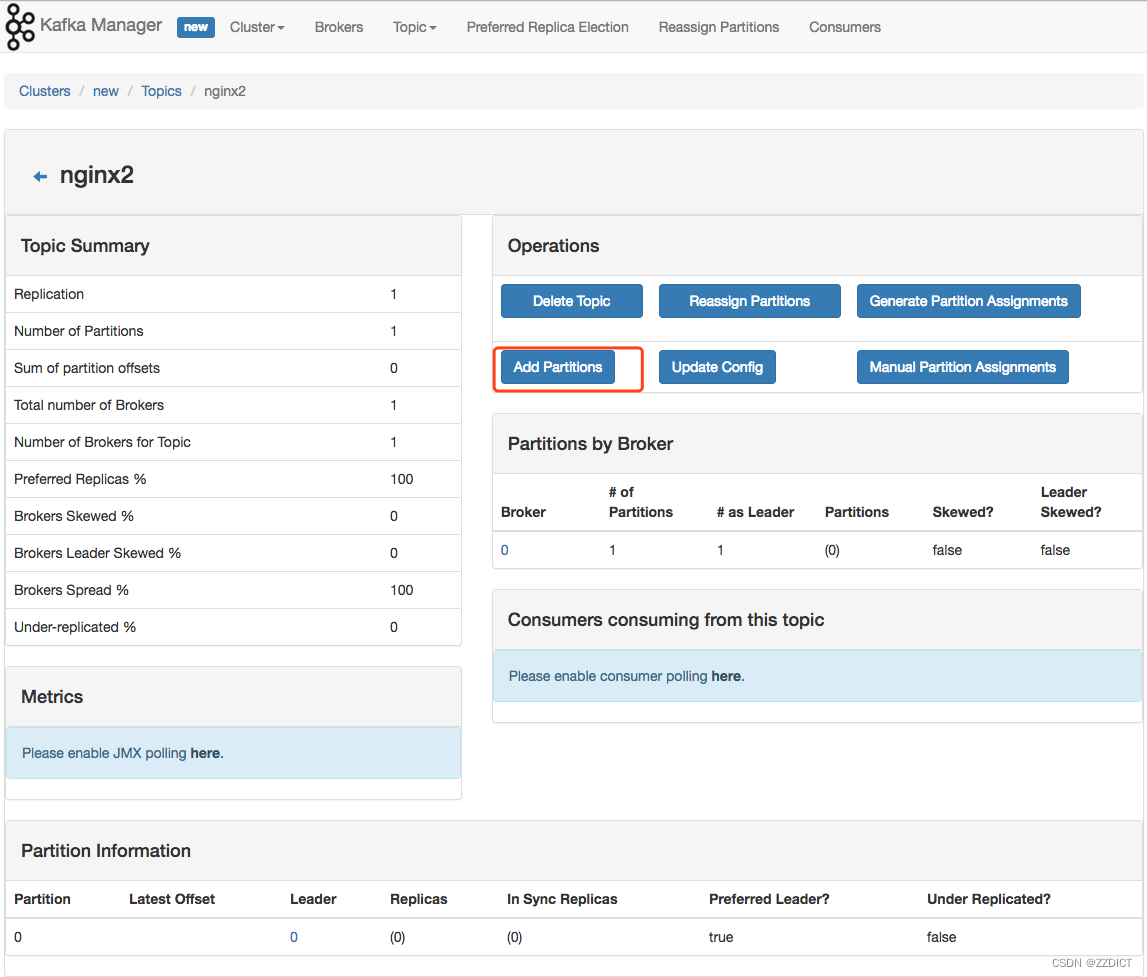
如果遇到 Kafka 消费不及时的话,可以通过到具体 cluster 页面上,增加 partition。Kafka 通过 partition 分区来提高并发消费速度
九. 集群测试
1. 在192.168.226.27主机操作
[root@filebeat ~]# yum install -y nginx[root@filebeat ~]# vim /etc/nginx/nginx.conf
#在http模块里替换原来的日志格式log_format main '{"user_ip":"$http_x_real_ip","lan_ip":"$remote_addr","log_time":"$time_iso8601","user_req":"$request","http_code":"$status","body_bytes_sents":"$body_bytes_sent","req_time":"$request_time","user_ua":"$http_user_agent"}';

启动并设置开机自启
[root@filebeat ~]# systemctl enable --now nginx
浏览器访问该主机nginx的网页

2. 配置 192.168.226.27主机的filebeat
[root@filebeat ~]# vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/access.logjson.keys_under_root: truejson.add_error_key: truejson.message_key: logoutput.kafka:hosts: ["192.168.226.24:9092","192.168.226.25:9092","192.168.226.26:9092"]topic: 'nginx-access-log' 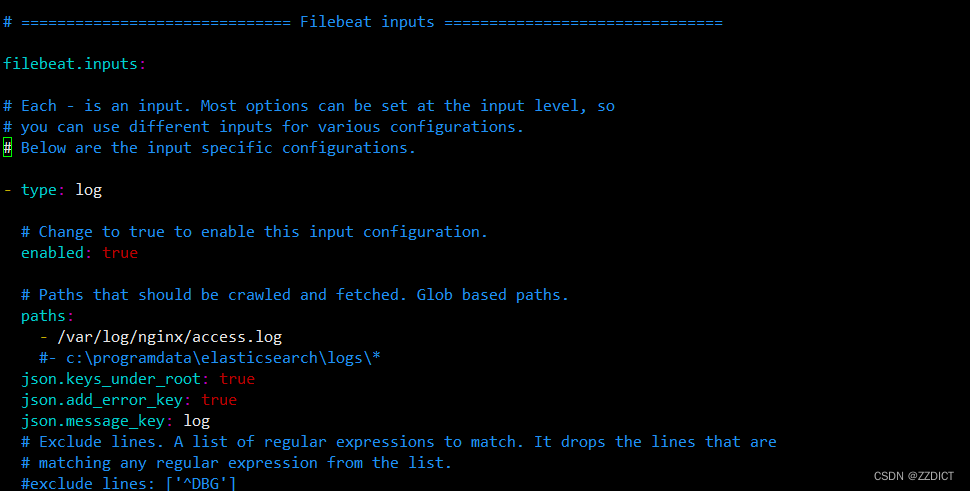

3. 配置logstash配置文件,即192.168.226.23主机
[root@nginx ~]# vim /usr/local/logstash-7.13.2/conf/stdin.conf
input {kafka {type => "audit_log" codec => "json"topics => ["nginx-access-log"]auto_offset_reset => "earliest"bootstrap_servers => ["192.168.226.24:9092,192.168.226.25:9092,192.168.226.26:9092"]#decorate_events => true#enable_auto_commit => true}
}filter {if [message] =~ "%{COMBINEDAPACHELOG}" { # 可选条件,确保只有符合格式的日志被处理grok {match => { "message" => "%{COMBINEDAPACHELOG} %{QS:x_forwarded_for}" }}date {match => [ "timestamp", "dd/MMM/YYYY:HH:mm:ss Z" ]}geoip {source => "lan_ip"}}
}此处的IP是Kafka集群IP
[root@nginx ~]# vim /usr/local/logstash-7.13.2/conf/stdout.conf
output {if [type] == "audit_log" { # 如果Kafka消息中没有type字段,这里可能永远不会为真 stdout { codec => rubydebug}elasticsearch {hosts => ["192.168.226.20", "192.168.226.21", "192.168.226.22"]index => 'access-log-%{+YYYY.MM.dd}' # 修改索引名称为更合适的名称}}
}
此处的IP是ES集群IP
4. 重启192.168.226.27主机上的filebeat
[root@filebeat ~]# systemctl restart filebeat
5. 查看Kafka
对192.168.226.24操作
列出 Kafka 集群中所有可用的主题的
[root@Kafka1 kafka_2.11-2.0.0]# bin/kafka-topics.sh --zookeeper 192.168.226.24:2181 --list

查看 nginx-access-log 的topic的消息
[root@Kafka1 kafka_2.11-2.0.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.226.24:9092 --topic nginx-access-log --from-beginning 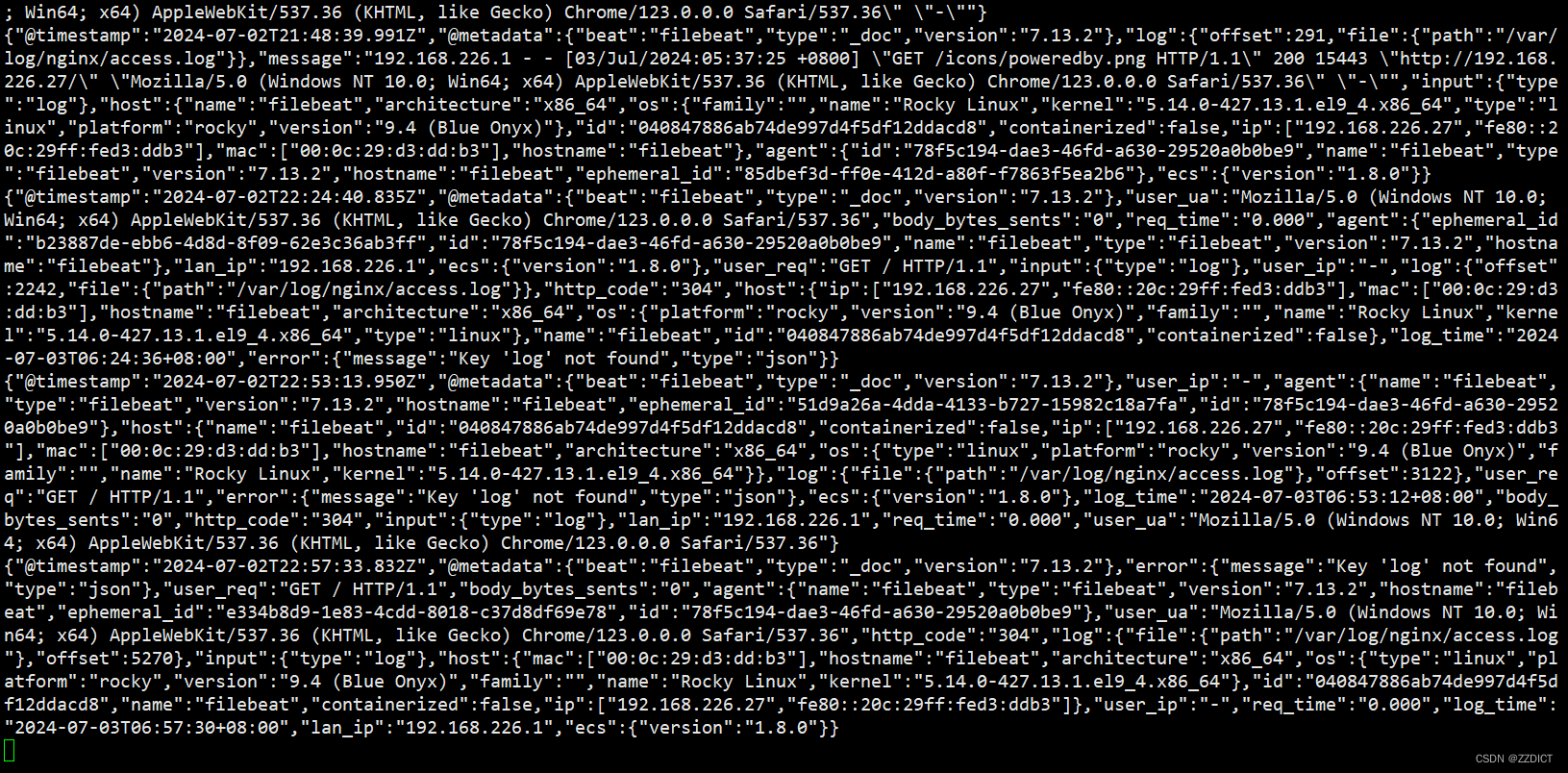
6. 启动logstash
对192.168.226.23主机操作
[root@nginx conf]# cd ..
[root@nginx logstash-7.13.2]# ./bin/logstash -f conf/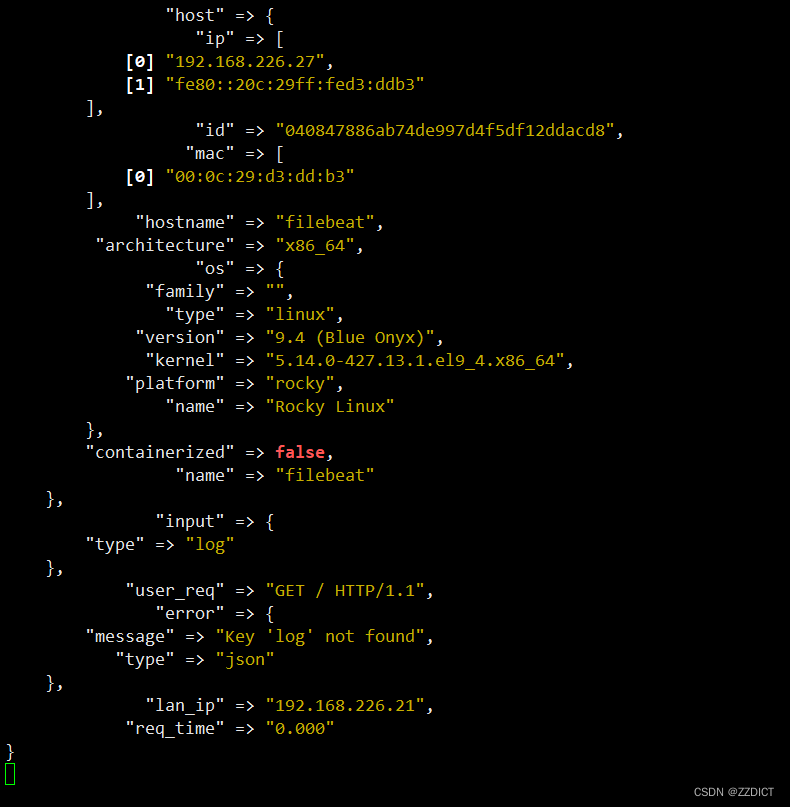
使用其他主机进行如下命令进行请求访问
然后看logstash的弹出信息。
[root@es2 logs]# curl http://192.168.226.27
7. 访问Kibana的web页面
即访问192.168.226.23

注:如遇时间不对,即集群中主机时间同步和时区未同步设定好。建议执行下述命令同步
sudo dnf install chrony
sudo systemctl enable --now chronyd
sudo systemctl restart chronyd
到此就完成了整个架构部署!