一、题型分析
1、Hadoop环境搭建
2、hadoop的三大组件
HDFS:NameNode,DataNode,SecondaryNameNode
YARN:ResourceManager,NodeManager (Yarn的工作原理)
MapReduce:Map,Reduce
3、大数据的特征:
4、hadoop特征:(重点hadoop可靠性)
5、Hive
数据库(OLTP)和数据仓库(OLAT)ETL:
UDF,UDTF,
数据表的分区,分桶
6、4个采集工具:DataX、Flume、Maxwell、kafka
二、考点涵盖
一、大数据基础知识文档
1、大数据需要解决的三个问题:数据采集、数据存储(hdfs)、数据计算(MapReduce)。
2、数据采集的4个工具:DataX、Flume、Maxwell、kafka
3、大数据(Big Data):指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
4、1byte=8bit 1k=1024byte 1MB=1024K 1G=1024M 1T 1P
- 大数据特点:大量、高速、多样性、价值性
- 大数据的生态体系,指由大数据相关产业、技术和应用构成的复杂庞大的系统。
- 大数据生态体系:数据源+数据存储+数据处理+数据应用
(1)Sqoop:Sqoop是一款开源的工具,主要用于在Hadoop、Hive与传统的数据库(MySQL)间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。Sqoop现已被DataX所替代。
(2)Flume:Flume是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
(3)Kafka:Kafka是一种高吞吐量的分布式发布订阅消息系统。
(4)Spark:Spark是当前最流行的开源大数据内存计算框架。可以基于Hadoop上存储的大数据进行计算。
(5)Flink:Flink是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
(6)Oozie:Oozie是一个管理Hadoop作业(job)的工作流程调度管理系统。
(7)Hbase:HBase是一个分布式的、面向列的开源数据库。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
(8)Hive:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务或Spark任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
(9)ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、名字服务、分布式同步、组服务等。
二、Hadoop基础文档
1、hadoop特征(四高一低):高可靠性、高扩展性、高效性、高容错性、低成本、
写出六到七个高可靠性体现的方面(简答)
Hadoop的高可靠性体现在以下几个方面:
1.数据冗余和副本机制:Hadoop通过数据冗余和副本机制,在集群中存储数据的多个副本,以防止数据天失。当某个节点发生故障时,可以从其他副本中恢复数据,确保数据的可靠性,
2.心跳机制和节点健康检测:Hadoop集群中的节点会定期发送心跳信号给主节点,用于检测节点的健康状态。如果某个节点长时间未发送心跳信号,Hadoop会认为该节点故障,并进行相应的处理,保证集群的稳定性。
3.机架感知和数据本地性优化:Hadoop的机架感知功能可以根据节点所处的机架位置来优化数据的存储和任务调度,减少跨机架的数据传输,提高数据本地性和作业执行效率
4.自动故障转移和自我修复:Hadoop具有自动故障转移和自我修复机制,能够在节点或任务发生故障时自动转移任务或数据,并自动修复一些常见的问题,确保集群的连续性和稳定性,
5.赢可用性架构:Hadoop提供了高可用性的解决方案,如HDFS的NameNode HA(高可用性)机制和VARN的ResourceManager HA机制,确保即使在节点故障的情况下,集群仍能保持高可用性,不影响作业的执行。
6.数据完整性和一致性保证:Hadoop画过数据校验和一致性机制来保证数据的完整性和一致性。数据在存储和传输过程中会进行校验和验证,避免数据损坏或算改,保证数据的准确性,
7.监控和日志记录:Hadoop集群提供了丰富的监控和日志记录功能,可以实时监校集群的状态和性能指标,及时发现问题并进行处理,提高集群的稳定性和可靠性,
2、hadoop的三大组件
HDFS分布式文件系统 数据存储:NameNode什么叫元数据哪些是元数据管理什么;DateNode分块保存数据;SecondaryNameNode日志和日志合并,不能做热备份
YARN资源调度:ResourceManager资源调度管理;NodeManager管理单个节点;yarn工作原理
MapReduce计算:Map并行计算; Reduce合并

Yarn的工作原理(简答)
1.资源管理器(ResourceManager):YARN的核心组件之一,负责整个集群的资源管理。
ResourceManager接收作业提交请求,分配资源给不同的应用程序,并监控资源的使用情况。
2.节点管理器(NodeManager):每个集群节点上都运行一个NodeManager,负责管理该节点的资源,NodeManager会定期向ResourceManager报告节点的资源使用情况,并按收来自ResourceManager的资源分配指令。
3.应用程序主管(ApplicationMaster):每个应用程序在YARN中都有一个对应的ApplicationMaster,负责应用程序的管理和协调。ApplicationMaster与ResourceManager通信,请求资源分配,并监控应用程序的执行状态。
4.作业调度器(Scheduler):YARN的调度器负责决定如何分配集群资源给不同的应用程序。调度器根据资源请求、优先级和队列设置等因素来进行资源分配决策。
总体来说,YARN的工作原理是通过ResourceManager和NodeManager同工作,
每个应用程序的资源需求和执行过程,从而实现高效的集群资源管理和作业调度
- Map阶段并行处理输入数据。
- Reduce阶段对Map结果进行汇总。

三、Hive全部文档
1、数据库(OLTP)和数据仓库(OLAT)ETL 区别:(简答)
数据库主要用于事务处理,即联机事务处理OLTP(On-Line Transaction Processing),也就是我们常用的面向业务的增删改查操作。OLTP要求实时性高,但处理数据量不是很大。
数据仓库主要用于数据分析,即联机分析处理OLAP(On-Line Analytical Processing),供上层决策,常见于一些查询性的统计数据。OLAP实时性要求不高,但处理的数据量很大。
2、

【课后作业】
1、简述数据库与数据仓库的区别。
2、简述OLTP的OLAP。

3、什么是ETL,ETL在数据处理过程中所起的作用是什么?
建立 OLAP 应用之前,我们要想办法把各个独立系统的数据抽取出来,经过一定的转换
和过滤,存放到一个集中的地方,成为数据仓库。这个抽取,转换,加载的过程叫 ETL(Extract
Transform,Load),目的是将企业中分散、零乱、标准不统一的数据整合到一起。
ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的
新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持 ETL 的正常和稳定。ETL
4、下面不是数据仓库特征的是(C)稳定性
A.主题性 B.集成性 C.实时性 D.时变性
5、关于hive描述,以下说法错误的是( D)
A.Hive本身不存储数据,Hive中每张表的数据存储在HDFS。
B.Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)。
C. Hive解析器(SQLParser)将SQL字符串转换成抽象语法树(AST)。
D.Hive仓库存储了数据库、表名、表的拥有者、列/分区字段、表的类型。
【课后作业】
4、Hive底层的计算由分布式计算框架实现,下列哪些计算引擎hive不支持( D)
A.MapReduce B.Tez C.Spark D.Flink
5、Hive默认在HDFS的工作目录配置在哪个参数配置文件中( B)
A. hive-default.xml B.hive-site.xml C.hive-log4j2.properties D.hive-env.sh
【课后作业】
4、下列HQL操作是属于反序列化的是( D)
A.INSERT B.ALERT C.DROP D.SELECT
5、下列存储格式不属于列式存储的是( A)
A. TEXTFILE B. ORC C. PARQUET D. RCFILE
【课后作业】
4、下列语句中,能够按照课程求平均值的是(D)
A.select 课程,avg( 成绩) 平均分 from 表
B. select 课程,分数,avg( 成绩) 平均分 from 表 group by 课程
C. select 课程, max( 成绩) 平均分 from 表 group by 课程
D. select 课程, sum( 成绩)/count(*) 平均分 from 表 group by 课程
5、Hive函数类别不包括(D)
A.一进一出 B. 多进一出 C. 一进多出 D. 多进多出
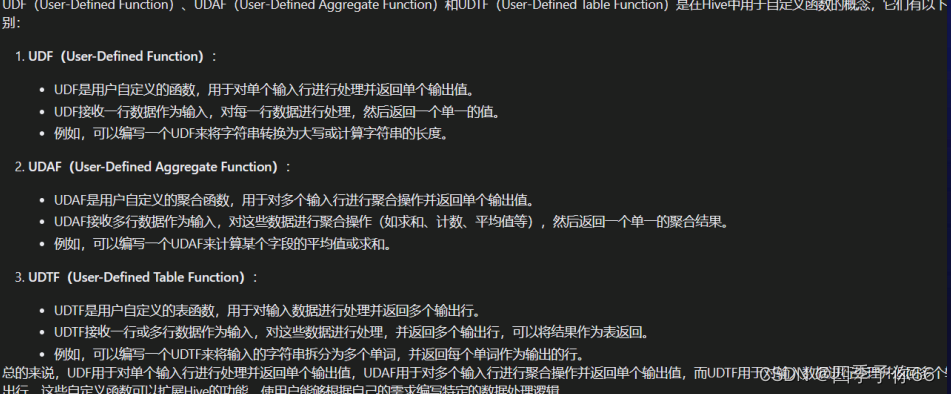
【课后作业】
- 简述UDF、UDAF、UDTF函数的区别。
UDF一进一出
UDAF多进一出
UDTF一进多出
3、函数substr('abcde',2,2)的的执行结果是(B)
A.ab B. bc C. cd D. de
4、下列关于窗口函数的说法错误的是( D)
A. partition by 分组类似group by,基于每一行数据所在的组进行计算并返回结果。
B. 窗口函数和聚合函数相似,窗口函数的输入也是多行记录。
C. order by 不仅在窗口内排序,还在窗口内从当前行到之前所有行的聚合。
D. 窗口若包含order by,则默认值为rows between 第一行 and 当前行。
【课后作业】
1、简述分区的原理和作用。
2、简述分桶的原理和作用。
3、简述动态分区和静态分区的区别和使用场景。
4、下列参数设置中,可以避免动态分区过多导致的性能问题( B)
A. hive.exec.max.dynamic.partitions
B. hive.exec.max.dynamic.partitions.pernode
C. hive.exec.max.created.files
D. hive.error.on.empty.partition
5、下列关于分区的说法错误的是( A)
A. Hive动态分区的分区字段必须是表的列
B. Hive分区通过设置虚拟列来进行动态分区,可以更加灵活地根据查询结果插入相应的分区。
C. Hive动态分区可以提高数据插入和查询的效率,同时也可能导致分区目录过多降低查询性能。
D.可以设置hive. exec. default. partition. name参数来处理分区字段值为空的情况。通过设置默认分区名,可以将分区字段值为空的数据插入到默认分区目录。
四、yarn文档
Yarn的工作原理
- mysql常用语句
MySQL初级篇——常用SQL语句(大总结)_查询薪资表中比java最高工资高的所有员工职位名称和薪资;-CSDN博客
MySQL常用SQL语句大全_数据库建表语句-CSDN博客