-
AutoRec模型
前置知识:推荐算法学习笔记1.1:传统推荐算法-协同过滤算法AutoRec模型通过引入自编码器结构,将共线矩阵中的用户向量(基于用户的U-AutoRec)或物品向量(基于物品的I-AutoRec)嵌入到低维空间后还原,从而使模型可以估计未知的用户评分。其公式如下所示:
h ( r ; W , b , V , μ ) = f ( W g ( V r + μ + b ) ) h(\mathbf{r};\mathbf{W,b,V},\boldsymbol{\mu})=f(\mathbf{W}g(\mathbf{Vr+}\boldsymbol{\mu}+\mathbf{b})) h(r;W,b,V,μ)=f(Wg(Vr+μ+b))
其训练的损失函数如下所示:
m i n W , b , V , μ λ 2 ( ∥ W ∥ F , ∥ V ∥ F ) + ∑ i = 1 N ∥ r i − h ( r i ; W , b , V , μ ) ∥ 2 2 min_{\mathbf{W,b,V},\boldsymbol{\mu}} \frac{\lambda}{2}(\|\mathbf{W}\|_F,\|\mathbf{V}\|_F)+\sum_{i=1}^{N}\|\mathbf{r}^i-h(\mathbf{r}^i;\mathbf{W,b,V},\boldsymbol{\mu})\|_2^2 minW,b,V,μ2λ(∥W∥F,∥V∥F)+i=1∑N∥ri−h(ri;W,b,V,μ)∥22
m其网络结构如下所示:

在《深度学习推荐系统》书中,把输出层描述成多分类层是存在歧义的。原论文中输出层实际的激活函数为 f ( x ) = x f(x)=x f(x)=x。

该模型的训练以及推荐过程如下(以U-AutoRec为例):
输入所有用户向量 R = { r i ∣ i = 1 , 2 , . . N } \mathbf{R} = \{\mathbf{r}^i|i=1,2,..N\} R={ri∣i=1,2,..N}进行模型训练。推理时输入用户向量 r i \mathbf{r}^i ri,得到预测向量 r ^ i \hat{\mathbf{r}}^i r^i,其中对于物品 I t e m k Item_k Itemk,用户的预测评分为 r ^ i [ k ] \hat{\mathbf{r}}^i[k] r^i[k]。
总结:
- 优点:通过从所有物品向量(或用户向量)中学习到核心的低维表示,从而在输入含未知取值的物品向量(或用户向量)时,可以估计未知取值的得分,从而提高泛化能力。
- 缺点:结构比较简单,存在表达能力不足的问题,另一方面只使用了共现矩阵的信息, 没法利用用户和物品的特性。
推荐算法学习笔记2.1:基于深度学习的推荐算法-基于共线矩阵的深度推荐算法-AutoRec模型
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/370281.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章

在 PostgreSQL 中,如何处理大规模的文本数据以提高查询性能?
文章目录 一、引言二、理解 PostgreSQL 中的文本数据类型三、数据建模策略四、索引选择与优化五、查询优化技巧六、示例场景与性能对比七、分区表八、数据压缩九、定期维护十、总结 在 PostgreSQL 中处理大规模文本数据以提高查询性能 一、引言
在当今的数据驱动的世界中&…

HashMap中的put()方法
一. HashMap底层结构
HashMap底层是由哈希表(数组),链表,红黑树构成,哈希表存储的类型是一个节点类型,哈希表默认长度为16,它不会每个位置都用,当哈希表中的元素个数大于等于负载因子(0.75)*哈希表长度就会扩容到原来的2倍 二. 底层的一些常量 三. HashMap的put()方法 当插入一…
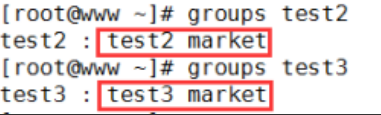
Linux 系统管理4——账号管理
一、用户账号管理
1、用户账号概述
(1)用户账号的常见分类: 1>超级用户:root uid0 gid0 权限最大。 2>普通用户:uid>500 做一般权限的系统管理,权限有限。 3>程序用户:1<uid&l…


生物化学笔记:电阻抗基础+电化学阻抗谱EIS+电化学系统频率响应分析
视频教程地址
引言 方法介绍 稳定:撤去扰动会到原始状态,反之不稳定,还有近似稳定的 阻抗谱图形(Nyquist和Bode图)
阻抗谱图形是用于分析电化学系统和材料的工具,主要有两种类型:Nyquist图和B…

Drools开源业务规则引擎(三)- 事件模型(Event Model)
文章目录 Drools开源业务规则引擎(三)- 事件模型(Event Model)1.org.kie.api.event2.RuleRuntimeEventManager3.RuleRuntimeEventListener接口说明示例规则文件规则执行日志输出 4.AgentaEventListener接口说明示例监听器实现类My…

Java 7新特性深度解析:提升效率与功能
文章目录 Java 7新特性深度解析:提升效率与功能一、Switch中添加对String类型的支持二、数字字面量的改进三、异常处理(捕获多个异常)四、增强泛型推断五、NIO2.0(AIO)新IO的支持六、SR292与InvokeDynamic七、Path接口…

WordPress网站添加插件和主题时潜在危险分析
WordPress 最初只是一个简单的博客软件,现在据估计为全球前 1000 万个网站中的 30% 提供支持。WordPress受欢迎的因素之一是可以轻松创建插件和主题来扩展它并提供比默认设置更多的功能。 目前,WordPress 网站列出了 56,000 多个插件以及数千个主题。插件…

DatawhaleAI夏令营2024 Task2
#AI夏令营 #Datawhale #夏令营 赛题解析一、Baseline详解1.1 环境配置1.2 数据处理任务理解2.3 prompt设计2.4 数据抽取 二、完整代码总结 赛题解析
赛事背景 在数字化时代,企业积累了大量对话数据,这些数据不仅是交流记录,还隐藏着宝贵的信…
python读取csv出错怎么解决
Python用pandas的read_csv函数读取csv文件。 首先,导入pandas包后,直接用read_csv函数读取报错OSError,如下:
解决方案是加上参数:enginepython。
运行之后没有报错,正在我欣喜之余,输出一下d…

linux 服务器数据备份 和 mysql 数据迁移
查看域名ip 查看程序所处文件位置
list open files
1、 lsof -i :port 查看端口获取进程 pid
2、lsof -i pid 1、scp 下载服务器文件到本地
security copy protocol 2、导出服务器 mysql 数据库(表)到本地 mysqldump是MySQL自带的一个实用程序&…
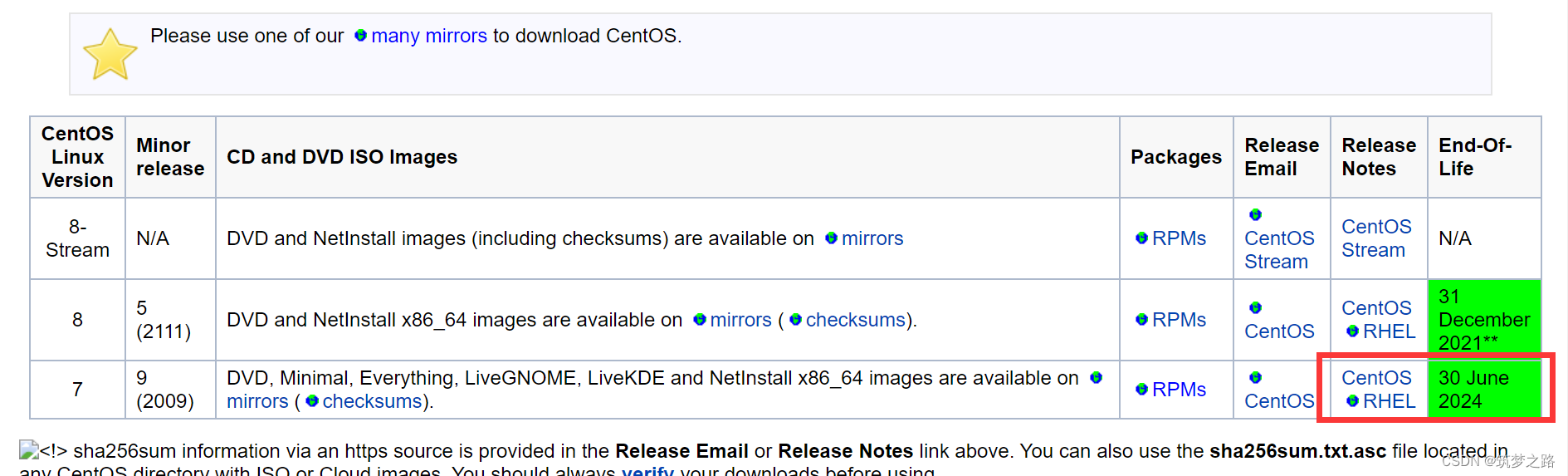
CentOS 7.9 停止维护(2024-6-30)后可用在线yum源 —— 筑梦之路
众所周知,centos 7 在2024年6月30日,生命周期结束,官方不再进行支持维护,而很多环境一时之间无法完全更新替换操作系统,因此对于yum源还是需要的,特别是对于互联网环境来说,在线yum源使用方便很…


Qt5.9.9 关于界面拖动导致QModbusRTU(QModbusTCP没有测试过)离线的问题
问题锁定
参考网友的思路:
Qt5.9 Modbus request timeout 0x5异常解决
网友认为是Qt的bug, 我也认同;网友认为可以更新模块, 我也认同, 我也编译了Qt5.15.0的code并成功安装到Qt5.9.9中进行使用,界面拖…
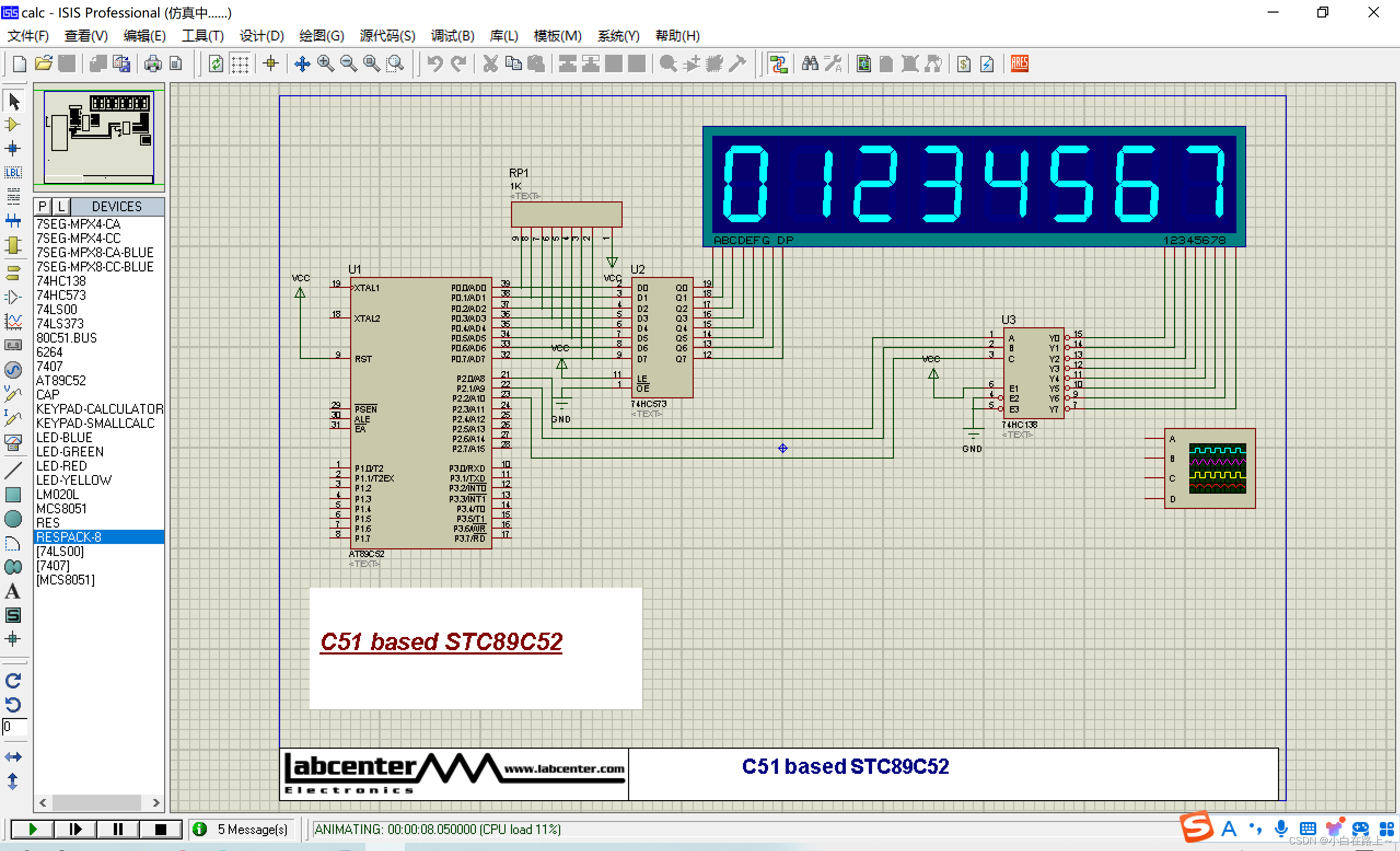
51单片机嵌入式开发:3、STC89C52操作8八段式数码管原理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 STC89C52操作8八段式数码管原理 1 8位数码管介绍1.1 8位数码管概述1.2 8位数码管原理1.3 应用场景 2 原理图图解2.1 74HC573原理2.2 74HC138原理2.3 数码管原理 3 数码管程序…

树模型详解2-GBDT算法
与adaboost一样,GBDT也是采用前向分步算法,只是它会用决策树cart算法作为基学习器,因此先要从分类树和回归树讲起
决策树-提升树-梯度提升树
决策树cart算法
回归树:叶子结点的值是所有样本落在该叶子结点的平均值
如何构建&a…
【绿色版】Mysql下载、安装、配置与使用(保姆级教程)
大家都知道,Mysql安装版的卸载过程非常繁琐,而且卸载不干净会出现许多问题,很容易让大家陷入重装系统的窘境。基于此,博主今天给大家分享绿色版Mysql的安装、配置与使用。
目录
一、Mysql安装、配置与使用
1、下载解压
2、创建…
zabbix 配置钉钉告警
1.申请一个钉钉企业版
2.群内申请一个机器人
下载电脑版钉钉,登录后,在要接收群消息的群里,点击右上角设置图标,下滑找到机器人,添加一个机器人,保存机器人的webhook地址 保存这里的加签字符串 保存这里的…

深度网络现代实践 - 深度前馈网络之反向传播和其他的微分算法篇
序言
反向传播(Backpropagation,简称backprop)是神经网络训练过程中最关键的技术之一,尤其在多层神经网络中广泛应用。它是一种与优化方法(如梯度下降法)结合使用的算法,用于计算网络中各参数的…

香橙派AIpro开发板评测:部署yolov5模型实现图像和视频中物体的识别
OrangePi AIpro 作为业界首款基于昇腾深度研发的AI开发板,自发布以来就引起了我的极大关注。其配备的8/20TOPS澎湃算力,堪称目前开发板市场中的顶尖性能,实在令人垂涎三尺。如此强大的板子,当然要亲自体验一番。今天非常荣幸地拿到…
推荐文章
- 腾讯定性微信QQ故障为一级事故,总办成员遭处罚;OpenAI CEO考虑在日本开设办事处;OpenBSD 7.3发布|极客头条...
- MySQL 5.7和8.0版本在多个方面存在显著区别,主要包括性能优化、新特性引入以及安全性提升
- # linux从入门到精通-从基础学起,逐步提升,探索linux奥秘(九)--网络设置与文件上传下载
- #Js篇:数组的方法es5和es6
- (01)Unity使用在线AI大模型(使用百度千帆服务)
- (1)(1.13) SiK无线电高级配置(一)
- (151)时序收敛--->(01)时序收敛一
- (2)(2.9) Holybro Microhard P900无线电遥测设备
- (C语言)球球大作战
- (ROOT)KAFKA详解
- (SSO单点登录)多个系统之间如何实现账号互通
- (二)Web服务器之Linux多进程