1.背景
最近在做 ES 相关东西,只最会在查询的时候给不同的字段设置不同的权重,但是得分具体怎么算的不太明白,花了4-5 天研究和总结了一下。这样不至于被别人问到“这个分数怎么算出来的?”,两眼一抹黑,不知其所以然,总结下方便之后学习;
2.准备



- 我创建了一个 book 索引,是
一个分片一个副本,有三条数据;我 match 查询 java 时, java 编程思想 的得分 0.5619609,深入理解 Java 虚拟机得分 0.40390933;(分片会影响得分,请先使用一个片,后面会给出解释)
3.详情
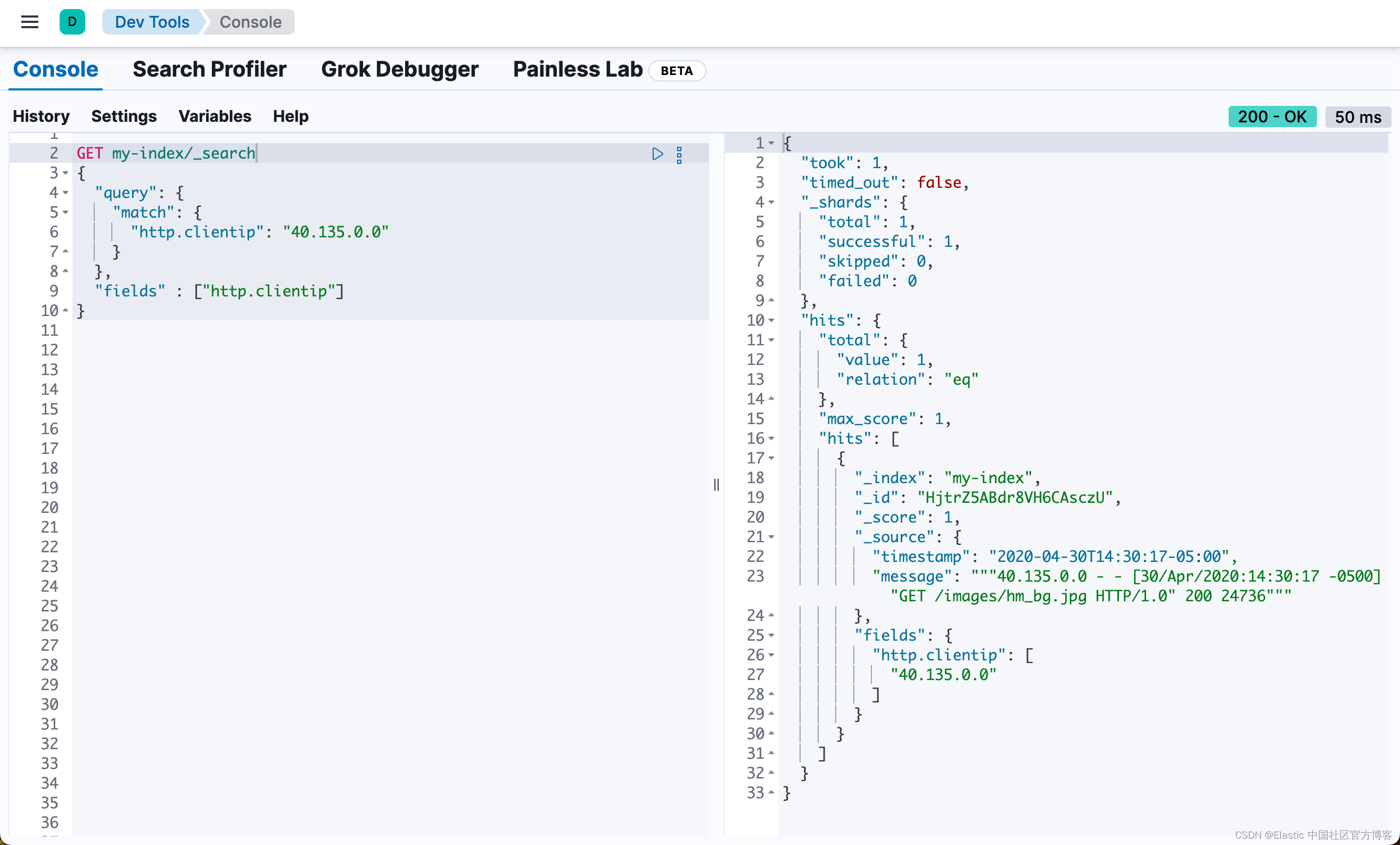
- 使用 explain 参数查询会给出得分计算过程

- 把 detail 全拿出来就是
"details" : [{"value" : 0.5619609,"description" : "score(freq=1.0), computed as boost * idf * tf from:","details" : [{"value" : 2.2,"description" : "boost","details" : [ ]},{"value" : 0.47000363,"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:","details" : [{"value" : 2,"description" : "n, number of documents containing term","details" : [ ]},{"value" : 3,"description" : "N, total number of documents with field","details" : [ ]}]},{"value" : 0.54347825,"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:","details" : [{"value" : 1.0,"description" : "freq, occurrences of term within document","details" : [ ]},{"value" : 1.2,"description" : "k1, term saturation parameter","details" : [ ]},{"value" : 0.75,"description" : "b, length normalization parameter","details" : [ ]},{"value" : 3.0,"description" : "dl, length of field","details" : [ ]},{"value" : 5.0,"description" : "avgdl, average length of field","details" : [ ]}]}]}]
3.1 粗略查看 ES 得分详情
- 我们发现第四行好像就是公式 ,而且与 details 数组的元素对应

- 而且每个元素都有一个 value 值,把 value 值带进公式,正好等于 0.5619608507173045

3.2 详细查看 es 得分
- 第一项 2.2 不用解释,是 es 默认的一个常数,我们看第二项
idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:和第三项tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from: - 第二项截图

小 n :number of documents containing term,翻译一下,包含词项(也就是 java) 的文档数量,因为我们查询的是 name 字段,所以就是所有文档中 name 字段,包含 java 的文档数量,即 Java 编程思想 和深入理解 Java 虚拟机 ,vulue 等于 2 。
大 N :total number of documents with field,翻译一下,有 name 这个字段的文档的数量,我们的三个文档都有 name 这个字段,即 Java 编程思想 、深入理解 Java 虚拟机 、Spring 5 个核心原理 value 等于 3 。 log(1 + (N - n + 0.5) / (n + 0.5)) = log(1 + (3 - 2 + 0.5) / (2 + 0.5) = log(1 + 1.5 / 2.5) = log1.6 =0.47000363,取的是自然数的对数,如图:

3.2 第三项
- 第三项截图

freq:occurrences of term within document,翻译一下,freq 是 frequency 的简写,频率的意思,即词项(java)在 Java 编程思想发生的频率, value 等于 1.
k1:term saturation parameter,翻译一下,词项饱和度参数,value 是一个常数 1.2
b:length normalization parameter,翻译一下,长度规格化参数,value 是一个常数 0.75
dl:length of field,翻译一下,“字段”的长度,这里长度可不是 Java 编程思想.length(),而是Java 编程思想能分成多少个词,看下面 3.3 截图,
avgdl:average length of field,翻译一下,“字段”的平均长度,同样也不是Java 编程思想 、 深入理解 Java 虚拟机、Spring 5 个核心原理.length()/3,而是Java 编程思想 、 深入理解 Java 虚拟机、Spring 5 个核心原理分词后的长度除以 3,3是有name 字段的数量,也看下面 3.3 截图
3.3 ik 分词器分词

- Java 编程思想 、 深入理解 Java 虚拟机、Spring 5 个核心原理,分词后词项太多截图不全,我放到 JSON 解析器下,可以看到 数量是 15 ,平均数量是 5


freq / (freq + k1 * (1 - b + b * dl / avgdl) = 1 /(1 + 1.2 * (1 - 0.75 + 0.75 * 3 /5)) = 1 / (1 + 1.2 * (0.25 + 0.75 * 0.6)) = 1 / (1 + 1.2 * 0.7) = 1 / 1.84 = 0.54347826 约等于0.54347825,不纠结那 0.00000001至此,得分的所有项解读完毕,另一个查询结果“深入理解 Java 虚拟机”也可以按照这个方式计算出来
4.公式解释
- 已经知其然了,现在看知其所以然,它是根据公式及经过大数据量实验设置参数后计算的结果。主角就是 BM25 算法,公式如下

- 我们在 kibana 上 explain 后公式的第二项和第三项分别对应这个公式的这两部分:

- 倒写的 3,表示求和,就是查询项分词后,每个分词都要计算分数,把每个查询词项的分数相加,比如我查询的是 “Java Spirng”,那么会把 Java 得分计算出来,再把 Spring 得分计算出来,然后相加;
- 第二项,原谅我打不出这个公式,就是上面截图中上面两个箭头的第一个, idf 是 inverse document frequency 的简写,翻译一下,逆文档频率,详情是
log(1 + (N - n + 0.5) / (n + 0.5));如果小 n 趋近于 大 N,那么整个公式值越小,大家可以把 N 固定为 3,然后小 n 分别为 1、2、3 时,换算下是不是 小 n 越大,计算结果越小。翻译成人话就是,当一个词在所有文档中都出现了,那么它显得不那么重要,得分就低了。 - 第三项,上面截图中上面两个箭头的第二个,如果说第二项是各个文档之间的纵向的比较,那么第三项更倾向于定位某个文档后的横向比较,
- 第三项(1),比较频率,即这个词项出现的次数 ,ES 的的公式是
freq / (freq + k1 * (1 - b + b * dl / avgdl)),比 BM25 分子少乘了一个(k1 + 1),有区别,但差别不大;因为分母k1 * (1 - b + b * dl / avgdl))可以看作是一个常数,那么当 freq 越大时,freq / (freq + k1 * (1 - b + b * dl / avgdl))值越大,但是最大值不超过 1,是无限趋近于 1 的数,当 freq 越小时,计算结果越小,翻译成人话也好理解,此项频率越高,得分越高。 - 第三项(2),比较词项占比,这里的此项是 name 字段分词后的个数除以所有 name 字段分词平均值,当
dl越大时分母越大,得分越小,翻译成人话是,比如我的 name 有一千个字且包含 java ,其他文档是十个字且包含 Java,那么我一千个字里面有个 Java 显得没那么重要。
4.分片情况下
如果你按照我上面计算时,发现中分词数量计算不对,那么很可能是你有多个分片,ES 不会把同一个字段各个分片的内容统一计算,而是每个片单独计算得分后就排名了,你可以通过指定 routing 来固定某个分片,验证得分结果。

5.前人的解读,帮助很大
bm25算法详解-bilibili
Elasticsearch BM25相关度评分算法超详细解释
6.一个不太成熟的使用
- 我项目中有一个索引,有两个字段,分别记录用户搜索的内容 searchFor 和这个内容被搜索的次数 count,我想要把 count 也融入得分公式中,ES 默认的得分记作
_score,我本想把 count 按 log10 取对数变成_score*log10(count),但是当 count 超过很大时会把_score的得分放大很多倍,不同次数的文档得分跨度也比较大; - 研究 ES 的得分步骤后,我发现我的次数和第三项
freq / (freq + k1 * (1 - b + b * dl / avgdl))特别像,count 没有字段长度的比较所以我直接把关于长度b(饱和度)和dl/avgdl去掉了,改成count / (count+k1) = count / (count + 1.2),最终得分是_score*count / (count + 1.2) - 当然这样算不一定成熟,但是看起来起作用了,而且不同次数的文档得分跨度也变小了;但是因为我工作中的测试数据量不够,这个
类 BM25的公式可能也不能这么硬套,要经过实际数据测试及业务需求匹配度验证后才能下定论,这只是一个不太成熟但是有点道理的使用,希望大家多留言讨论