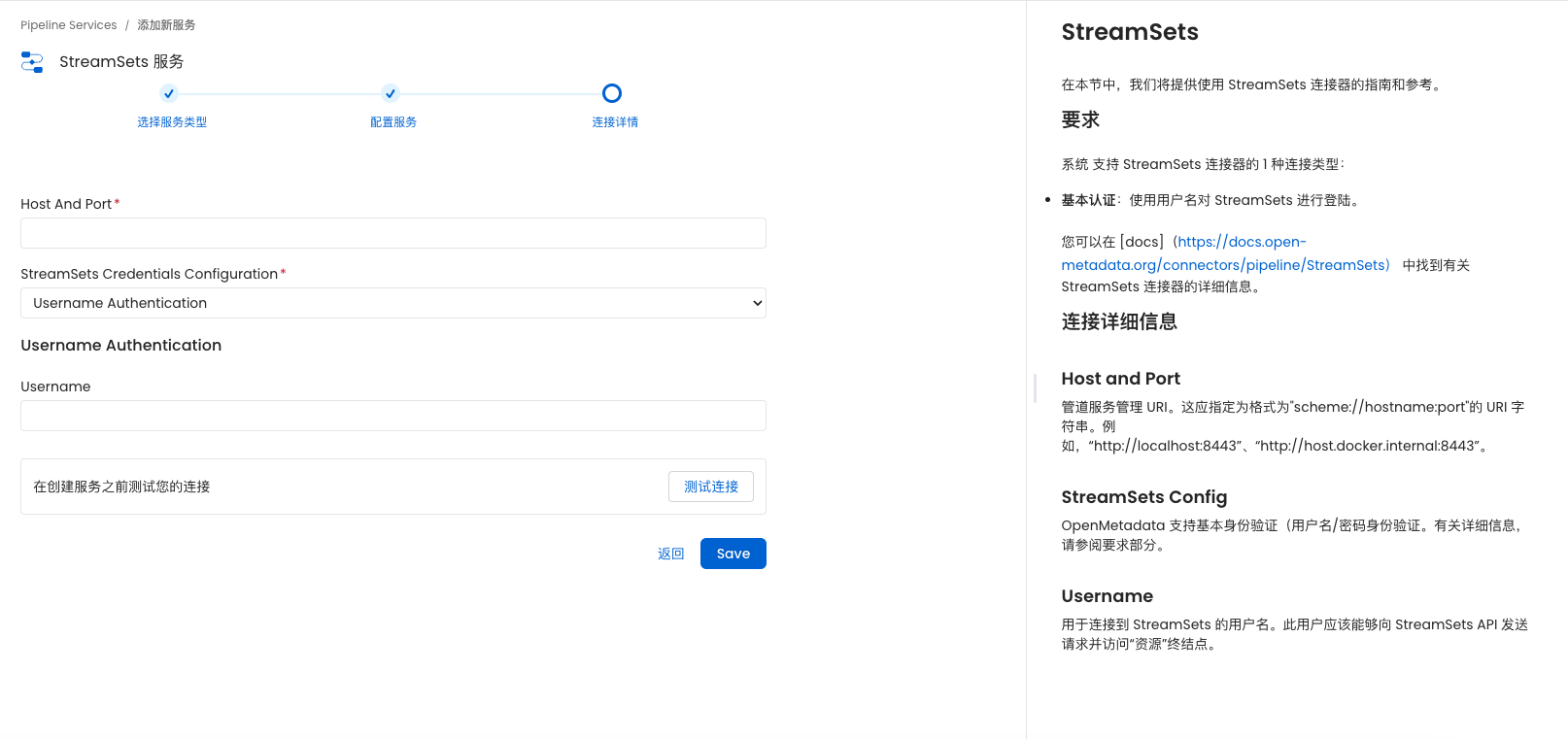
YOLO V7网络整体架构总结
YOLO v7网络架构的整体介绍
不同GPU和对应模型:
- 边缘GPU:YOLOv7-tiny
- 普通GPU:YOLOv7
- 云GPU的基本模型: YOLOv7-W6
激活函数:
- YOLOv7 tiny: leaky ReLU
- 其他模型:SiLU
同时,我们还针对不同的业务需求,使用基础模型进行模型缩放,得到不同类型的模型。 对于YOLOv7,我们对颈部进行stack scaling,并使用提出的复合缩放方法对整个模型的深度和宽度进行缩放,并以此获得YOLOv7-X。
- YOLOv7缩放得到了YOLOv7-X
- 对YOLOv7-W6我们使用新提出的复合缩放方法得到 YOLOv7-E6 和 YOLOv7-D6
- EELAN 用于 YOLOv7-E6,从而完成了 YOLOv7E6E
模型缩放模块
复合的模型缩放策略是YOLO v7中提出的一个核心的创新点之一。其中的缩放倍数包括了1.25倍和1.5倍
基础模块YOLOv7

首先论文中和Yolov7.yaml文件中使用到的基础模块是ELAN模块对应的结构图如下所示。

同时在Yolov7.yaml文件中的head部分我们使用了另外的一个基础模块ELAN’模块它是对ELAN模块进行模型变形处理得到了,ELAN’模块对应yolov7配置文件中的56到63层的信息。
之前的4个卷积组成了2个分路ELAN’可以看作是ELAN的变形,即4个卷积组成了4个分路

YOLOV7X模块

我们在这里先提前的进行总结和说明yolov7和yolov7x模型之间的差别点。首先yolov7x是在YOLOv7的基础上经过缩放得到的用于普通GPU的网络结构。
- 将yolov7中的所有ELAN和ELAN’模块全部替换为了ELAN+模块
- 将最后的三个repconv替换为了三个普通的Conv
- 所有通道数变为原来的1.25倍
ELAN+模块即将ELAN模块缩放1.25倍得到的结构。在原来的基础上多加了两个卷积层,通道数扩充为原来的1.25倍

YOLOv7w6模块
yolov7w6模块也可以看作是一个用于云GPU的基础模块,其他的云GPU使用的模型是在YOLOv7w6的基础上经过模型缩放改进的。

首先说明YOLOv7w6模型和YOLOv7模型的主要区别
- yolov7w6模型的预测特征层有4个多了一个10x10的预测特征层来进行预测。
- 使用3x3步长为2的普通卷积来替代yolov7模型中的MP1模块
- 使用3x3步长为2的普通卷积加上一个concat层来替代head中的MP2模块。
- 前两层的卷积被替换为了一个ReOrg模块
ReOrg模块
ReOrg模块可以简单的看作参考了YOLOV56.0版本中的focus模块,在common.py中的源代码如下所示。
class ReOrg(nn.Module):def __init__(self):super(ReOrg, self).__init__()def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
作用每隔一个位置对输入图片的像素值进行抽取操作。将通道数扩展为四倍对应4c,宽高缩短为原来的一半。

YOLOV7e6模块
YOLOV7e6的网络结构也是一个用在云GPU上的网络结构,是在YOLOv7w6的基础上经过缩放得到的网络结构。

- 在w6网络模型的基础上进行缩放得到对应的网络结构将ELAN替换为ELAN+ 将ELAN’替换为了ELAN’+
- 将普通的卷积替换为了Downc这种固定的结构
ELAN’+
ELAN’+在ELAN’的基础上进行模型的缩放缩放倍数为1.25倍,输出的通道数也变为原来的1.25倍。

Downc模块
class DownC(nn.Module):# Spatial pyramid pooling layer used in YOLOv3-SPPdef __init__(self, c1, c2, n=1, k=2):super(DownC, self).__init__()c_ = int(c1) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c_, c2//2, 3, k)self.cv3 = Conv(c1, c2//2, 1, 1)self.mp = nn.MaxPool2d(kernel_size=k, stride=k)
通过源代码可以看出Downc模块和之前的MP1模块结构上基本上是完全相同的,只有通道数有一些差异。1x1部分不改变通道数,输出结构的通道数翻倍

Yolov7d6模块
Yolov7d6模块是在YOLOV7e6模块的基础上再次进行缩放得到的结构,缩放的倍数达到了1.5倍。

整个模型及结构和之前的YOLOe6结构的主要的区别就在于将之前的ELAN+和ELAN’+模块进行进一步的模型缩放,得到了ELAN++和ELAN’++模块
本质上也就是在拓展一次得到最终的结果。
ELAN++和ELAN’++模块

YOLO V7e6e模块
YOLO V7e6e模块,顾名思义就是将YOLO V7e6模块中的所有ELAN相关的部分替换为了E-ELAN相关的元素组合。

YOLOv7tiny模块
YOLOv7tiny模块是YOLOv7向下进行缩放所得到的模块。整个模块使用的激活函数改为了使用LeakyReLU激活函数来进行实现。

- 直接使用了一个2x2的最大池化层来替代原来的MP1模块
- 使用了简化的模块ELAN’-
- 将MP2模块改为了使用普通的卷积在加一个concat拼接层
- 三个重参数化卷积替换为了conv
ELAN’-模块
ELAN’模块向下来进行缩放,减少两个输入的通道,来简化整个模型,整个模型全部使用的是ELAN’-

SPPCSPC-tiny
在边缘GPU网络中在head部分对SPPCSP模块也进行了一部分的简化操作
对应的是29到37层
[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-2, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[-1, 1, SP, [5]],[-2, 1, SP, [9]],[-3, 1, SP, [13]],[[-1, -2, -3, -4], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]],[[-1, -7], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1, None, 1, nn.LeakyReLU(0.1)]], # 37
SP部分就可以看作是一个3x3步长为1的maxpooling层,通过padding填充使得大小保持不变。
class SP(nn.Module):def __init__(self, k=3, s=1):super(SP, self).__init__()self.m = nn.MaxPool2d(kernel_size=k, stride=s, padding=k // 2)def forward(self, x):return self.m(x)

在最后的训练用的模块中会在中间的部分加入一些辅助头,用来实现之前提到过的深度监督的相关功能。
正负样本匹配的SimOTA
SimOTA是由OTA(OptimalTransportAssignment)简化得到的,OTA也是旷视科技同年出的一篇文章,论文名称叫做《Optimal transport assignment for object detection》目的是将匹配正负样本的过程看成一个最优传输问题。