背景
学习极客实践课程《检索技术核心20讲》https://time.geekbang.org/column/article/215243,文档形式记录笔记。
内容
主要是海量数据的大倒排索引的一些原理设计思想,ES底层就是基于这些设计思想以及原理,主要涉及读写分离、索引分层等思想。
构建大倒排索引
在一些超大规模的数据应用场景中,比如搜索引擎,它会对万亿级别的网站进行索引,生成的倒排索引会非常庞大,根本无法存储在内存中,还是需要存储在磁盘上。
倒排索引的结构就是dict + posting list,搜索引擎的倒排索引更加复杂,不仅需要为词编号,还要为词的每个字符存储dict中,因此完整词典项肯能会达到百万、千万的级别。
整个大的倒排索引全放入内存不太现实,可采用分治Map Reduce的思想,将大规模文档划分为多个小文档集合,为每个小文档创建倒排索引,在内存中,将倒排中的dict的key排序,对应的posting list中的记录也是有序的,在临时文件中,不需要存储dict key的编号,因为有后面会有很多临时倒排索引文件,最后生成临时倒排文件然后存入磁盘。
思考:为什莫要在内存中将dict key排序?便于后面多个小倒排索引合并,有序的话可以进行归并排序posting list。如果 posting list 可以完全读入内存,那我们就可以直接在内存中完成合并,然后把合并结果作为一条完整的记录写入最终的倒排文件中;如果 posting list 过大无法装入内存,但 posting list 里面的元素本身又是有序的,我们也可以将 posting list 从前往后分段读入内存进行处理,直到处理完所有分段。这样我们就完成了一条完整记录的归并。
每完成一条完整记录的归并,我们就可以为这一条记录的关键词赋上一个编号,这样每个关键词就有了全局唯一的编号。重复这个过程,直到多个临时文件归并结束,这样我们就可以得到最终完整的倒排文件。
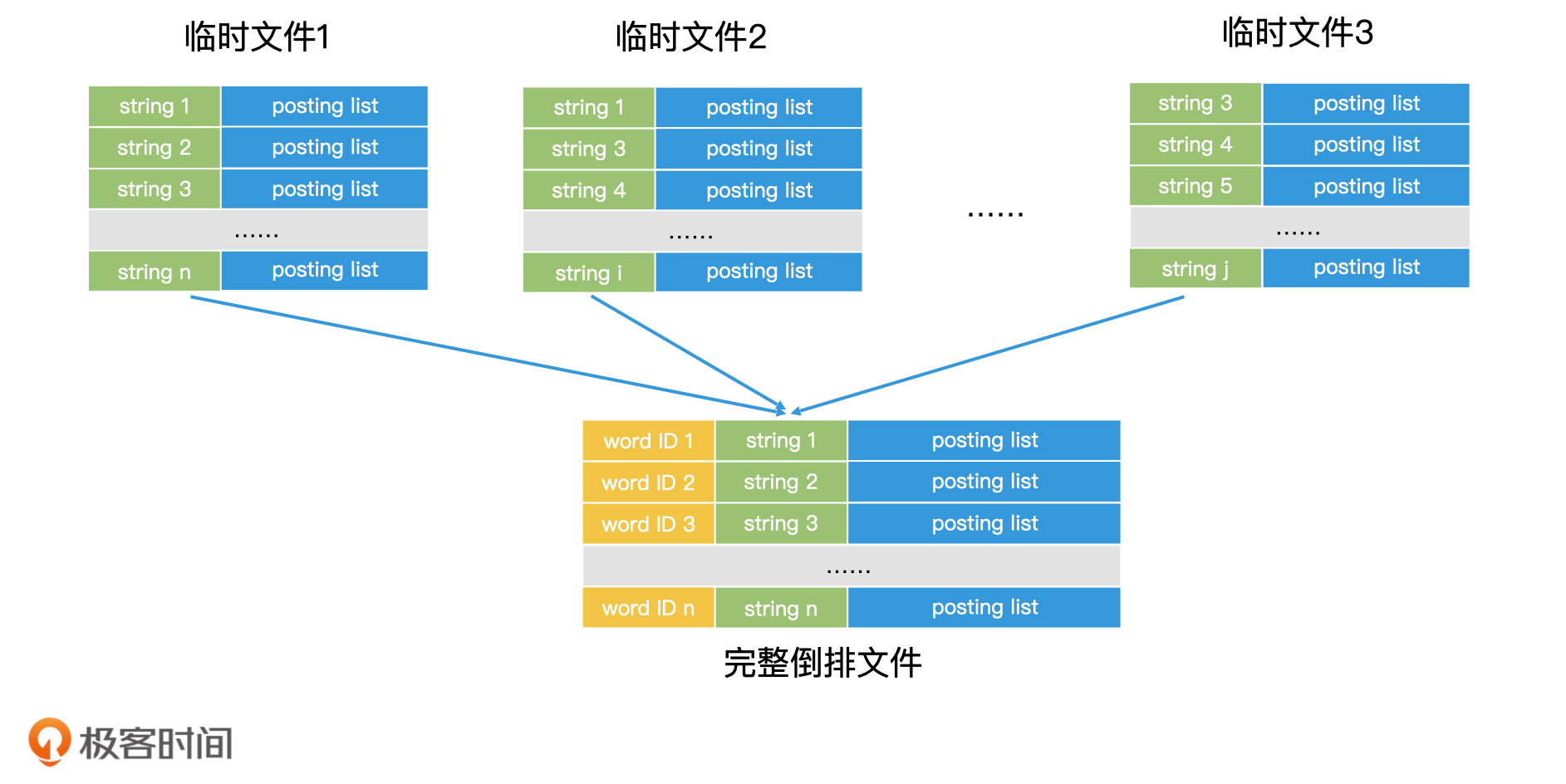
检索大倒排索引
内存的检索效率比磁盘高许多,因此
(1)对于小倒排索引dict,能加载到内存中的数据,我们要尽可能加载到内存中进行检索。
(2)对于大倒排索引的dict,存储在磁盘,内存有可能放不下
- 数据量如果不大可以从磁盘倒排文件全部读取出来,在内存使用Hash表建立词典。查询的时候,内存中找到key对应的posting list记录位置,再从磁盘将其读取到内存中处理。
- 数据量如果很大不能全部加载到内存,可以利用B+ 树来完成词典的检索,因为大倒排文件的dict key 都是有序的,构建B+树也比较简单。
另外说完dict,对于key找到的posting list过长无法全部加载到内存问题,比如搜索引擎热门关键词可能对应很多页面,导致posting list就会很大,这种情况也可以考虑使用B+树索引,只读取有用的数据块到内存,降低磁盘访问次数。包括在 Lucene 中,也是使用类似的思想,用分层跳表来实现 posting list,从而能将 posting list 分层加载到内存中。而对于长度不大的 posting list,我们仍然可以直接加载到内存中。
海量数据两个重要设计思想
- 尽可能将数据加载到内存,可以使用数索引据压缩。比如说在 Lucene 中,就使用了类似于前缀树的技术 FST,来对词典进行前后缀的压缩,使得词典可以加载到内存中。
- 将大数据集拆分为小数据集。
思考:倒排索引的dict如果能全部加载进内存,就会大幅提升效率,在hash表无法存入内存的情况,是否能用其他内存空间占用更小的数据结构,来将词典完全加载到内存,有序数组和二叉树是否可行?想要节省空间,哈希表中的key应该是每个词项的hash值,而value是这个词项的字符串以及postlist指针(需要一个结构体)主要是value占用的空间比较多。
可以考虑数组的连续空间存储
- 首先思路就是使用一个数组,每个数组元素存(结构体|length),但是结构体中的string词项是变长的,因此开辟数组空间只能以最长的为准,这样导致空间的浪费。
- 改进的思路就是使用可变长的char数组紧凑的存储(结构体),顺序查找是比较慢的,然后在使用一个int数组建立索引,每个元素都是int类型,存储结构体的hash值,指向char对应数组元素位置。
更新大倒排索引
对于内存中的倒排索引的更新,需要考虑要应对并发场景,一般来说,并发场景要靠锁来解决,比如给posting list加上读写锁,加锁会导致性能问题。
Double Buffer机制
为了使系统有更好的性能,在工业界有一种Double Buffer机制,双缓冲机制,可以使得在无锁的状态下完成索引更新。
Double Buffer机制:同时维护两个倒排索引A、B,一个作为只读,另外一个作为更新,一定数据量批量更新一次,更新完成通过原子操作挪动指针P指向最新的倒排索引;
特点:这种方案比较高效,但是数据量大的时候会造成Double的内存开销,像亿万级别的搜索引擎数据,基本是存储磁盘上,无法全部加载到内存使用Double Buffer机制。
划分全量增量索引
将系统分为全量索引、增量索引
- 全量索引:系统会周期性的处理全部的数据,生成一份完整的索引,称为全量索引,不能被实时修改,只做查询,效率比较高且不用加锁。
- 增量索引:处理实时更新的数据,将更新的数据单独建立一个内存中的倒排索引,当查询发生时会同时查询 全量索引 + 增量索引,对于删除的数据则保存到增量索引的删除列表,最后将合并的结果输出。另外就是增量索引是内存中比较小的索引,可以用Double Buffer机制进行无锁优化。
增量索引的合并
增强索引空间的持续增长如何处理?随着更新数据增多,内存中的倒排索引会逐渐变大,最终导致内存放不下,因此要进行增量索引的合并。
主要有三种常见的方法:
- 完全重建法:如果索引增长的速度不是很快,或者全量索引重建的代价不是很快,可以考虑这种,在内存满之前,重新整理索引文档,将增量索引数据更新到全量索引完成重建,期间不能查询,最后释放增量索引的数据。特点就是比较简单,效率不是很高。
- 再合并法:类似完全重建,只不过是将增强索引直接归并到全量索引,减少重新整理全部文档的开销。特点就是比完全重建效率高一些,但是全量、增量索引数据量相差比较大的时候,效率也不会很高,比如在搜索引擎中,增量索引只有上万条记录,但全量索引可能有万亿条记录。这样的两个倒排索引合并的过程中,只有少数词典中的关键词和文档列表会被修改,其他大量的关键词和文档列表都会从旧的全量索引中被原样复制出来,再重写入到新的全量索引中,这会带来非常大的无谓的磁盘读写开销。因此,对于这种量级差距过大的全量索引和增量索引的归并来说,如何避免无谓的数据复制就是一个核心问题。
- 滚动合并法:如果是直接原地更新,不生成新的全量索引,直接在全量索引上面做修改,这样就能减少重新构建全量索引的无谓的磁盘复制开销,但是要求全量索引的数据posting list是按照关键字单独存储的,并且超大规模量级的零散小文件的高效读写,许多操作系统是很难支持的。其次,由于只有一份全量索引同时支持读和写,那我们就需要“加锁”,这肯定也会影响检索效率。因此,在一些大规模工程中,我们并不会使用原地更新法。因此滚动更新法:滚动合并法。所谓滚动合并法,就是先生成多个不同层级的索引,然后逐层合并。
滚动合并机制的确是最复杂的一种。它的核心思想是“解决小索引和大索引合并的效率问题,避免大索引产生大量无谓的复制操作”。而解决方案则是“在小索引和大索引中间加入中索引进行过渡”。
滚动合并法比如说,一个检索系统在磁盘中保存了全量索引、周级索引和天级索引。所谓周级索引,就是根据本周的新数据生成的一份索引,那天级索引就是根据每天的新数据生成的一份索引。在滚动合并法中,当内存中的增量索引增长到一定体量时,我们会用再合并法将它合并到磁盘上当天的天级索引文件中。
这样不会造成大量无谓的磁盘数据复制开销,查询的时候需要多个粒度的索引,但是最终积累的多了,比如月级别索引积累的多了,还是要跟全量索引进行合并重建全量索引,类似减少系统定期重启。
思考:为什么删除数据不像LSM树那样做一个删除标记,而是在增量索引中保存一个删除列表?原因有几点
- 一个关键字的posting list会有很多docid,这样查找docid做删除标记的效率比较低,而LSM树则是k-v型数据库,key值是单一的。
- 删除的doc会涉及很多关键字,也就是会存储在很多posting list中,这样做删除标记的话,读写需要加锁,会影响很多posting list
- 加上删除标记的数据只有等到索引合并的时候才会删除,在查询的时候多文posting list取交集 效果等同于 直接和删除列表取交集,没有必要加一部增加删除标记的操作。
分布式加速大倒排索引查询
分布式技术就是将大任务分解成多个子任务,使用多台服务器共同承担任务,让整体系统的服务能力相比于单机系统得到了大幅提升。
如分布式技术提升大倒排索引构建的效率,为大于内存容量的数据构建倒排索引时,将一个大文件拆分为多个小文件,放到多个服务器中构建多个临时索引磁盘文件,再利用Map Reduce等框架多路归并为一个大的倒排索引磁盘文件。
那分布式技术也可以提升大倒排索引查询的效率,将数据拆分到多个服务器,多个服务器内存能放下拆分子数据的倒排索引,从而减少磁盘IO次数,加快效率。需要关注的是数据拆分问题。
数据拆分
索引拆分方案
- 基于业务:按照业务划分拆分数据,比如试卷、试题的业务数据,缺点是耦合度比较高,不易多业务复用。
- 基于文档(水平拆分):将所有的文档随机分片拆分,每一个分片都是一个倒排索引,缺点是检索结果需要合并每个分片的检索结果,需要分发服务进行路由、合并等。优点:划分比较均匀,能很好的负载均衡。
- 基于关键字(垂直拆分):将所有文档按照关键词分片拆分,优点:可以缓解上面基于文档拆分导致的一次查询分发服务复制请求、合并结果的次数以及压力。缺点:查询词没被划分到一个分片,那么仍需要分发服务复制请求查询多个分片;如果检索的词是热点词,那么dict中该hot key对应的posting list会非常长,检索性能也会下降。