深度学习数学基础
- 数学基础
- 线性代数-标量和向量
- 线性代数-向量运算
- 向量加和
- 向量内积
- 向量夹角余弦值
- 线性代数-矩阵
- 矩阵加法
- 矩阵乘法
- 矩阵点乘
- 矩阵计算的其他内容
- 人工智能-矩阵的操作
- 矩阵转置(transpose)
- 矩阵与向量的转化
- 线性代数-张量(tensor)
- 常见张量操作
- 转置操作(transpose)
- 张量展平(view)
- 导数
- 导数介绍
- 常见导数(一般都不常见)
- 复合函数基本求导法则
- 注释
数学基础
线性代数-标量和向量
标量(Scalar): 一个标量就是一个单独的数
向量(Vector): 一个向量就是一列数,即把向量看做空间中的点,只是有方向,有一个起始点指向所表示的空间位置。
示例:
A[0,0,1]由O执行A的箭头表示向量:

向量有几个数字,我们就叫几维向量
线性代数-向量运算
向量加和
条件 两个相加的向量维度相同,即有相同的位置或者长度
示例
A + B = B + A
[1,2] + [2,3] = [2,3] + [1,2] = [3,5]
向量内积
条件 两个相加的向量维度相同,即有相同的位置或者长度
示例
A + B = B + A
[1,4] + [2,3] = 12 + 43 = 14
规则:对应位置上的数相乘之和
向量夹角余弦值
条件 两个相加的向量维度相同,即有相同的位置或者长度
示例
A + B = B + A
Cosθ = A*B / |A| · |B|
余弦值的计算:即为内积除于两个向量模的乘积
|A|叫做A的模,可以理解为向量的长度的意思
模的计算:|A| = √(𝑥^2),即对A的所有数字的平方求和并开方
线性代数-矩阵
矩阵(matrix)释义: 字面意思,多个数组组成的矩形
示例
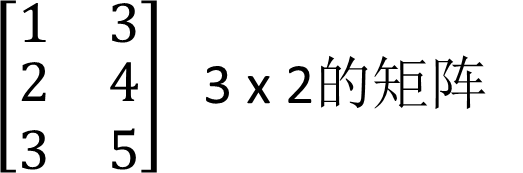
3乘2的矩阵就是有三行两列数字,如果是1乘3矩阵,就是有1行,三列数字的矩形
矩阵加法
条件: 相加的矩阵行列必须相同,即形状要一样
规则: 对应的位置数字相加即可
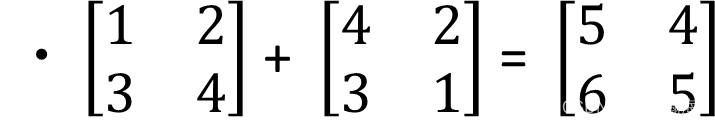
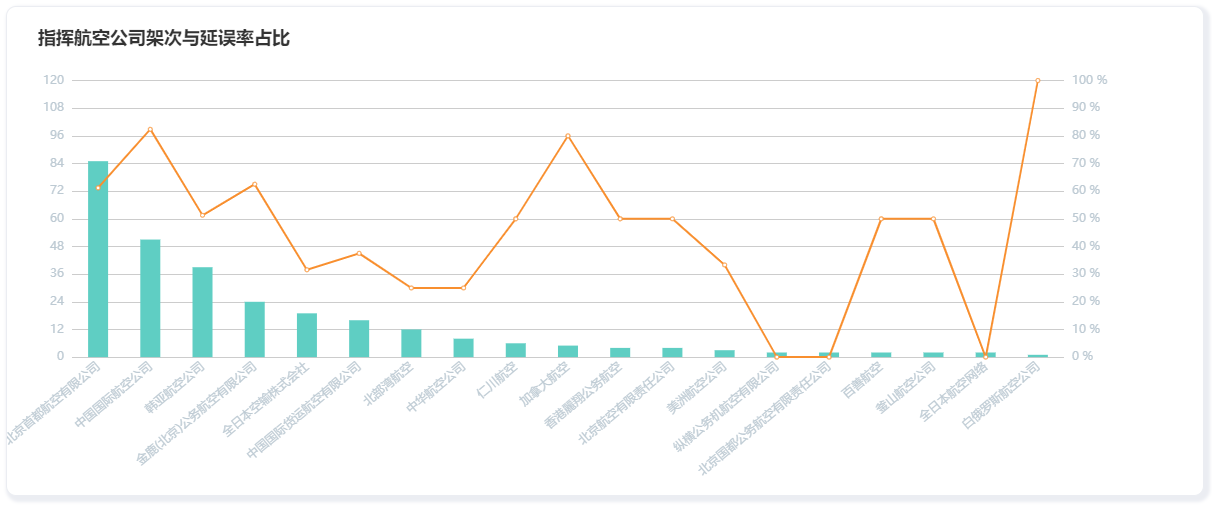
矩阵乘法
条件: 两个矩阵相乘,首先不能交换位置;其次左边的矩阵的列数必须于右边相乘矩阵的行数相同,即左边的宽必须等右边的长。
规则: 即为左侧矩阵的行与右侧矩阵的列对应序号的数字相乘之后作为所在行与所在列序号的结果,比如左侧第一行数字分别于右侧第一列的数字相乘之和得到的数字,在新的矩阵中的位置就是一行一列
注意特点: M x N 矩阵乘以 N x P矩阵得到M x P维度矩

矩阵点乘
条件: 两个矩阵点乘,必须形状一致,即必须是行列大小相同。
规则: 即为两个矩阵对应位置的数相乘,得到新的位置矩阵的数
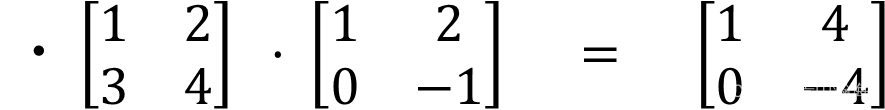
矩阵计算的其他内容
1.符合分配率
A*(B+C) =AB +AC
1.符合结合率
A*(BC) =(AB )*C
人工智能-矩阵的操作
矩阵转置(transpose)
释义: 就是将矩阵的行列互换,原来第一列的数据,改为第一行,数字的顺序不变,形成转置后的矩阵。
示例: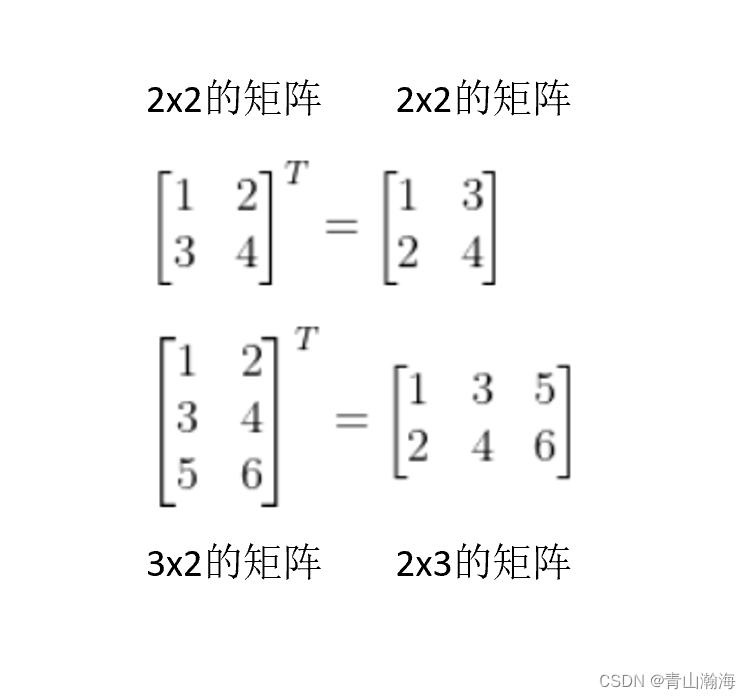
矩阵与向量的转化
释义:
向量转矩阵称为reshape,
规则即为,将向量的数字,按照形成的矩阵要求,从第一行从左到右数字填充,填完后再到第二行重复操作
矩阵转向量称为flatten,规则即为,将矩阵的数,从第一行由左到右,接着第二行由左到右写为一排即可
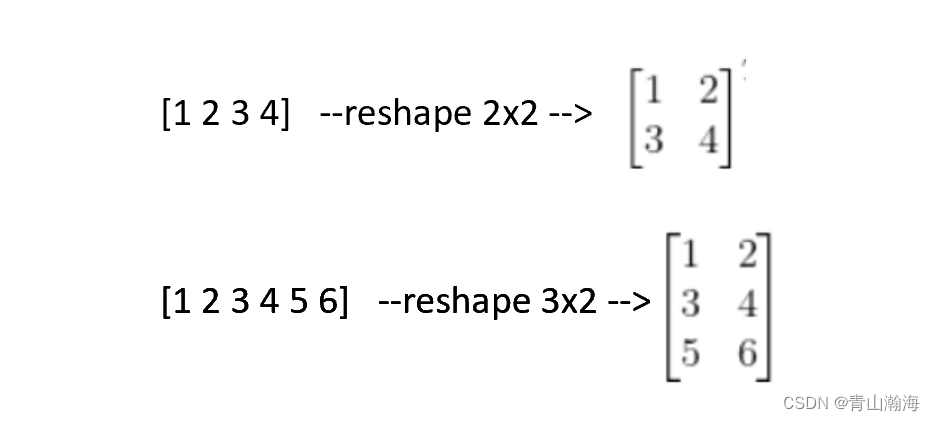

线性代数-张量(tensor)
张量释义: 将多个矩阵排列在一起,就是张量,那么排列在一起的矩阵必须形状一致才行,比如是MxN的矩阵,有S个排列在一起,就称为SxMxN的张量;更进一步 将K个SxMxN的张量排列在一起,就可以称为KxSxMxN维度的张量。
注意:
张量是神经网络训练中最为常见的数据形式
所有的输入,和输出、中间结果基本都是以张量形式存在的
张量中的矩阵一般形状都是相同的即行列大小相同
下面是一个2x2x2维度的张量
***注意:***实际代码中,矩阵中每行的数字都由[]括起来的,是一种写法,不必纠结;等价于矩阵的整体的大括号[]

常见张量操作
原始的2x2x2的张量如下:

转置操作(transpose)
进行transpose(1,2)
含义,即原有的2x2x2的张量,其
中数字可以看做成一个数组[2,2,2],这里的transpose(1,2)即代表原有数组中的第二号位置和第三号位置,第二号代表行,第三号数字代表列,即原有的张量中的每一个矩阵内部行列转换。结果如下:

进行transpose(0,1)
含义:和上述一样,
代表的是原有张量中的第0号位置、和第1号位置,即分别代表张量和行,所以进行的转置是张量内的矩阵之前进行行交换

张量展平(view)
X.view(-1,2)
X.view(4,2)
释义: 上面两个展平的结果和作用在当前这个张量例子中是一样的效果,含义不一样。
X.view(-1,2),
代表需要将张量展平为2列的矩阵,-1就是一个占位的,直接写-1即可;如果张量有10个数字,展开就是5x2;即指定列数,行数自动给你算。
X.view(4,2),代表我目标就是展平为4x2的矩阵,这个是写的更明白,写-1更方便。注意哈,原来的张量有多少个数字,展平后,不管那种写法,原有的数字都不会减少和增多

导数
导数介绍
导数释义: 导数在数学中的含义,就是描述一个函数在某一点的变化趋势;简单点说就是,x增大,y增大还是减小,(y这个数随着x变化而变化的)这个关系由导数的正负表达。
示意图如下:

导数在深度学习中的用处拆解:
1.首先我们在深度学习训练中,有个重要的步骤,就是求模型预测值和我们想要的值之间的差距 –
loss
2.换一句话说,我们的想办法调整原来函数中举例:(y=k*x +b),可以调整的数,使得求出来的loss最小。
3.那以y=k*x +b)为例,啥参数可以调整呢?是:k、b吧;x是我们的输入数据、y是我们预测的数据哦别搞混了
4.那调整k、b,怎么调呢,哎,导数呗,导数可以知道当前k,b调大,loss是增大还是减小嘛,这就是最关键的作用。
常见导数(一般都不常见)

复合函数基本求导法则

注释
看到这的朋友,如果数学不太好的话,感觉有点懵,想和您说一声,辛苦了,其实上面使用的基础数学知识呢,对于一般的开发者来说,用不上。咱们都有框架了pytorch、Tensorflow…,还有各种numpy、…包;咱们只需要了解基本的原理就行,等需要用到时,一般也不是啥问题了。