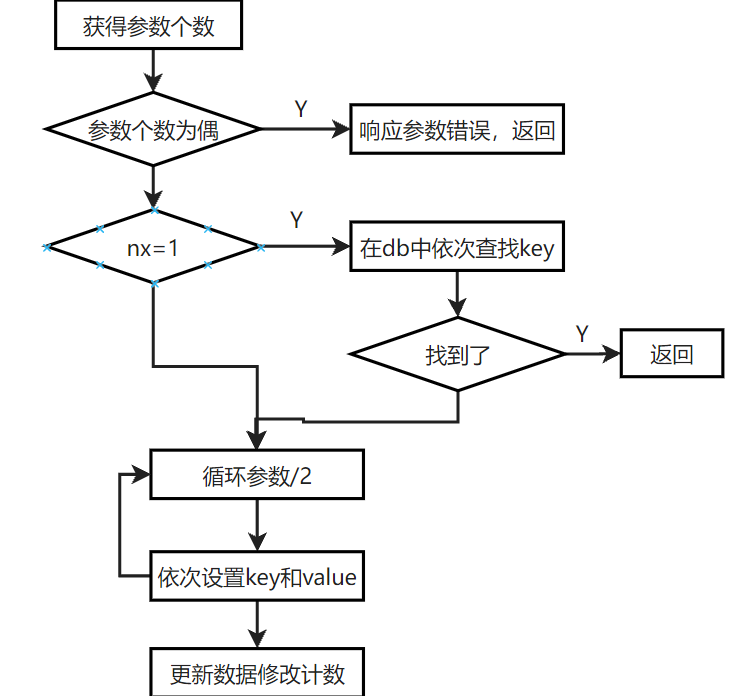
算法原理
贪心法的基本思路是在对问题求解时总是做出在当前看来是最好的选择,也即贪心法不从整体最优上考虑,所做的仅是某种意义上的局部最优选择。
贪心法所能解决的问题一般需要满足以下性质:
贪心选择性质:所求问题的整体最优解可以通过一系列局部最优选择(贪心选择)来达到。每一步用作决策依据的选择准则被称为最优度量标准(或贪心准则),选择最优度量标准是贪心法求解问题的核心。
最优子结构性质:如果一个问题的最优解包含其子问题的最优解,则称此问题具有最优子结构性质。最优子结构性质是问题可用贪心法(或动态规划法)求解的关键特征,证明问题是否具有最优子结构性质通常可采用数学归纳法。
贪心法的一般算法设计如下:
// 假设解向量(x0,x1,...,xn-1)类型为SolutionType,其分量类型为SType
SolutionType Greedy(STypea[],int n) {SolutionType x={};// 初始时解向量不包含任何分量for(int i=0; i<n; i++) {// 从a中选择一个当前最好的分量SType xi=Select(a);// 选择的分量可行if(Feasiable(xi)){// 将分量xi合并到当前解向量x中x=Union(x,xi); } }// 返回生成的最优解return x;
}
背包问题
题目描述
设有 n n n 个物品,第 i i i 个物品的重量为 w i w_i wi,价值为 v i v_i vi, w i , v i w_i, v_i wi,vi 均为整数。有一个可以携带的最大重量不超过 W W W 的背包。求,在不超过背包负重的前提下,装入背包的物品的价值之和的最大值(每个物品可以取一部分装入背包)。
输入输出
输入:第一行物品个数 n n n 和背包载重 W W W,第二行输入物品重量 w i w_i wi,第三行输入物品价值 v i v_i vi。
输出: x 1 , … , x n x_1,…,x_n x1,…,xn, 0 ≤ x i ≤ 1 , 1 ≤ i ≤ n 0≤x_i≤1,1≤i≤n 0≤xi≤1,1≤i≤n, x i x_i xi 为物品i装入背包部分的重量占物品 i i i 总重量的比例(小数点后保留两位)。
解题思路
根据题目要求,有如下约束函数和目标函数:
- $∑w_i × x_i≤W , , ,(0≤x_i≤1,1≤i≤n)$
- M a x { ∑ v i × x i } Max\{∑v_i × x_i\} Max{∑vi×xi},$ (0≤x_i≤1,1≤i≤n)$
因此,问题归结为寻找一个满足上述约束条件,并使得目标函数值达到最大的解向量 X = ( x 1 , x 2 , … , x n ) X=(x_1,x_2,…,x_n) X=(x1,x2,…,xn)。每次从物品集合中选择单位重量下价值最大的物品,如果其重量小于背包容量,就可以把它装入,并将背包容量减去该物品的重量,然后会面临一个最优子问题,否则取出物品的一部分(重量等于背包容量)装入背包,并将背包容量置为 0 0 0 。当背包容量为 0 0 0 时终止算法。
代码实现
struct good {int num; // 编号double w, v; // 重量 价值
};
good *gs; // 物品
int M, N; // 物品数 背包载重
double *x; // 解int main() {// 输入cin >> N >> M;gs = new good[N], x = new double[N];for (int i = 0; i < N; ++i) {cin >> gs[i].w;gs[i].num = i, x[i] = 0;}for (int i = 0; i < N; ++i)cin >> gs[i].v;// 求解solve();// 输出解printf("(");for (int i = 0; i < N; ++i)printf("%-.2f,", x[i]);printf("\b)");
}
/*** 求解背包问题*/
void solve() {// 按单位价值从大到小排序sort(gs, gs + N, comp);// 当前收益for (int i = 0; i < N; ++i) {if (gs[i].w < M) {x[gs[i].num] = 1; //全部放入M -= gs[i].w;} else if (M > 0) {x[gs[i].num] = M / gs[i].w; // 部分放入M = 0;} else break; // 背包已满}
}
// 单位价值从大到小排序
bool comp(const good &g1, const good &g2) {return (g1.v / g1.w) > (g2.v / g2.w);
}
时间复杂度: O ( n l o g ( n ) ) O(nlog(n)) O(nlog(n))。
空间复杂度: O ( n ) O(n) O(n)。
带时限的作业排序问题
题目描述
设有一个单机系统,无其它资源限制且每个作业运行相等时间,不妨假定每个作业运行 1 1 1 个单位时间。现有 n n n 个作业,每个作业都有一个截止期限 d i > 0 d_i>0 di>0, d i d_i di 为整数。如果作业能够在截止期限之内完成,可获得 p i > 0 p_i>0 pi>0 的收益。求得到一种作业调度方案,该方案给出作业的一个子集和该作业子集的一种排列,使得若按照这种排列次序调度作业运行,该子集中的每个作业都能如期完成,并且能够获得最大收益。
输入输出
输入:第一行输入 n n n 的值,第二行输入收益 p i p_i pi,第三行输入截止期限 d i d_i di(作业默认按照输入顺序从 1 1 1 开始编号)。
输出: ( x 1 , x 2 , … , x k ) (x1,x2,…,xk) (x1,x2,…,xk), x k x_k xk = 第 k k k 个加入作业子集的作业的编号。
解题思路
由于每个作业的运行时间均为一个单位时间,因此,只需每次选择收益最大的作业,并分配在其截止时间内且当前未被任何作业占用且尽可能靠后的时间段给它,让它完成即可,若不存在这样的时间段,则寻找下一个作业。具体做法是:
- ① 将所有作业按收益从大到小排序,同时设置数组 v i s vis vis(初始置为 0 0 0 )用于记录某时间段是否已被占用;
- ② 选择收益最大的作业(从前往后依次选择作业即可);
- ③ 从 j . d j.d j.d 开始往前寻找可用时间段(寻找 v i s [ i ] = 0 vis[i]=0 vis[i]=0 的位置),若找到,则将 v i s [ i ] vis[i] vis[i] 置为 1 1 1 并安排该作业完成,否则跳过此作业。
- ④ 重复步骤②和③,直到所有作业搜索完毕。
代码实现
struct job {int num, d; // 作业号 截止期限double p; // 收益
};
job *js; // 作业
int N, *vis, *res; // 作业数 时间段 结果集作业编号int main() {// 输入cin >> N;js = new job[N], res = new int[N];for (int i = 0; i < N; ++i) {cin >> js[i].p;js[i].num = i + 1;res[i] = 0;}int md = 0; // 最晚截止时间for (int i = 0; i < N; ++i)cin >> js[i].d, md = max(md, js[i].d);vis = new int[N];for (int i = 0; i <= md; ++i)vis[i] = 0;// 求解solve();// 输出printf("(");for (int i = 0; i < N && res[i]; ++i)printf("%d,", res[i]);printf("\b)");
}
/*** 求解带时限的作业排序问题*/
void solve() {sort(js, js + N, comp); // 按收益从大到小排序for (int i = 0, k = 0; i < N; ++i) {if (!vis[js[i].d]) { // 时间段未被占用vis[js[i].d] = 1;res[k++] = js[i].num; // 放入结果集} else {for (int j = js[i].d - 1; j >= 1; --j) { // 往前查找空闲时间段if (!vis[j]) { // 时间段未被占用vis[j] = 1;res[k++] = js[i].num; // 放入结果集break;}}}}
}
// 按收益从大到小排序
bool comp(const job &j1, const job &j2) {return j1.p > j2.p;
}
时间复杂度: O ( n 2 ) O(n^2) O(n2)。
空间复杂度: O ( n 2 ) O(n^2) O(n2)。
最小生成树
题目描述
一个无向连通图的生成树是一个极小连通子图,它包括图中全部结点,并且有尽可能少的边。一棵生成树的代价是树中各条边上的代价之和。一个网络的各生成树中,具有最小代价的生成树称为该网络的最小代价生成树(minimum-cost spanning tree)。求最小代价生成树的代价。
输入输出
输入:第一行输入结点个数 n n n 和边的个数 m m m,以下 m m m 行输入各边的两个端点 u u u、 v v v 及该边上的代价。
输出:如果有生成树,则输出最小生成树的代价;如果没有生成树,则输出 n o s p a n n i n g t r e e no spanning tree nospanningtree。
基础实现
设 V V V 表示顶点集合, X X X 表示已在树上的点,只需每次从 V − X V-X V−X 中选取到 X X X 距离最小的点添加到 X X X。需要维护一个 m i n C o s t minCost minCost 数组(初始为 I N F INF INF )记录所有点到 X X X 的距离,且每回添加点后,需要更新 m i n C o s t minCost minCost。
#define INF (INT_MAX>>1)int V, E; // 点数 边数
vector<bool> used; // 各点到已在树上的点的集合的最短距离,初始为INF
vector<int> d; // 各点到已在树上的点的集合的最短距离,初始为INF
vector<vector<int>> cost; // 图int main() {// 输入cin >> V >> E;cost.resize(V, vector<int>(V, INF));for (int i = 0; i < V; ++i) cost[i][i] = 0;for (int i = 0, x, y, c; i < E; ++i) {cin >> x >> y >> c;cost[x][y] = cost[y][x] = c;}// 辅助数组used.resize(V, false);d.resize(V, INF);// 求解int res = solve();// 输出res != INF ? cout << res : cout << "no Spanning Tree";
}
/*** 求解最小生成树代价* @return 最小生成树代价*/
int solve() {if (E < V - 1)return INF; // 至少需要V-1条边d[0] = 0; // 将第一个点到树上的距离置为0int res = 0;while (true) {// 找到距树最近的点int v = -1;for (int i = 0; i < V; ++i) {if (!used[i] && (v == -1 || d[v] > d[i])) v = i;}if (v == -1)break; // 所有点都已在树上used[v] = true; // 把点v加到树上res += d[v];for (int i = 0; i < V; ++i) { // 更新各点到树上的最短距离if (d[i] > cost[v][i])d[i] = cost[v][i];}}return res > INF ? INF : res;
}
时间复杂度: O ( V 2 ) O(V^2) O(V2)。
空间复杂度: O ( V + E ) O(V+E) O(V+E)。
队列优化
在基础实现中,寻找未添加到生成树且离生成树最近的点的时间复杂度为 O ( V ) O(V) O(V),为了降低查找的时间复杂度,采用优先队列来存储未添加到树上的结点,查找的时间复杂度可降为 O ( l o g ( V ) ) O(log(V)) O(log(V))。同时,方便更新各点到生成树的距离,改用邻接表存储图。
#define INF (INT_MAX/2)struct edge { // 边int to, cost;
};
typedef pair<int, int> P; // (距离,结点编号)
int V, E; // 点数 边数
vector<int> d; // 各点到已在树上的点的集合的最短距离,初始为INF
vector<vector<edge>> G; // G[i]为起点为i的边的集合int main() {// 输入cin >> V >> E;G.resize(V, vector<edge>());for (int i = 0, x, y, c; i < E; ++i) {cin >> x >> y >> c;G[x].push_back({y, c});G[y].push_back({x, c});}d.resize(V, INF);// 求解int res = solve();// 输出res != INF ? cout << res : cout << "no Spanning Tree";
}
/*** 求最小生成树问题* @return 最小生成树代价*/
int solve() {if (E < V - 1)return INF; // 至少需要V-1条边priority_queue<P, vector<P>, greater<P>> Q;d[0] = 0; // 将第一个点到树上的距离置为0Q.push({0, 0}); // 初始结点入队int res = 0; // 代价while (!Q.empty()) {// 距离树最近的点P p = Q.top();Q.pop();int v = p.second;// f[v]已在处理v之前的点的过程中被修改且变短了,不必再处理,直接返回// 同时也能保证了根据点v更新其相邻点的操作进行一次if (d[v] < p.first)continue;d[v] = 0; // 添加到树上后距离置为0res += p.first;// 只遍历与结点v相连的结点for (int i = 0; i < G[v].size(); ++i) {edge e = G[v][i];if (d[e.to] > e.cost) {d[e.to] = e.cost;Q.push({e.cost, e.to});}}}return res;
}
时间复杂度: O ( E + V l o g ( V ) ) O(E+Vlog(V)) O(E+Vlog(V))。
空间复杂度: O ( E + V ) O(E+V) O(E+V)。
经验总结
贪心算法设计的核心在于最优量度标准(或贪心准则),通过每次依据最优量度标准所做的局部最优解,必须能产生一个全局最优解。选定最优量度标准后,代码实现相对而言较为简单,每次只需根据最优量度标准做出局部最优选择即可,局部最优选择仅依赖于以前的决策,不依赖于以后的决策。
贪心问题的难点在于贪心准则的选取,只能通过不断尝试来选出一个满足条件的贪心准则,是否满足条件需要通过严格的证明。通常,选定贪心准则后需要根据贪心准则排序,所以,当不知道该如何选取贪心准则时,不妨先将元素按照某个属性值或属性的组合值排序,再尝试所有可能的准则。贪心准则的选取有时需要借助不等式,如仓库选址问题。选取一个元素后,如果剩余未选择的元素的相对顺序会因此发生变化,则可考虑采用优先队列/堆来维护所有元素。
END
文章文档:公众号 字节幺零二四 回复关键字可获取本文文档。