目录:
- 1、云服务器介绍
- 2、云服务器界面
- 3、发布静态项目
- 1、启动nginx
- 2、ngixn访问
- 3、外网访问测试
- 4、拷贝静态资源到nginx目录下并重启nginx
1、云服务器介绍

2、云服务器界面
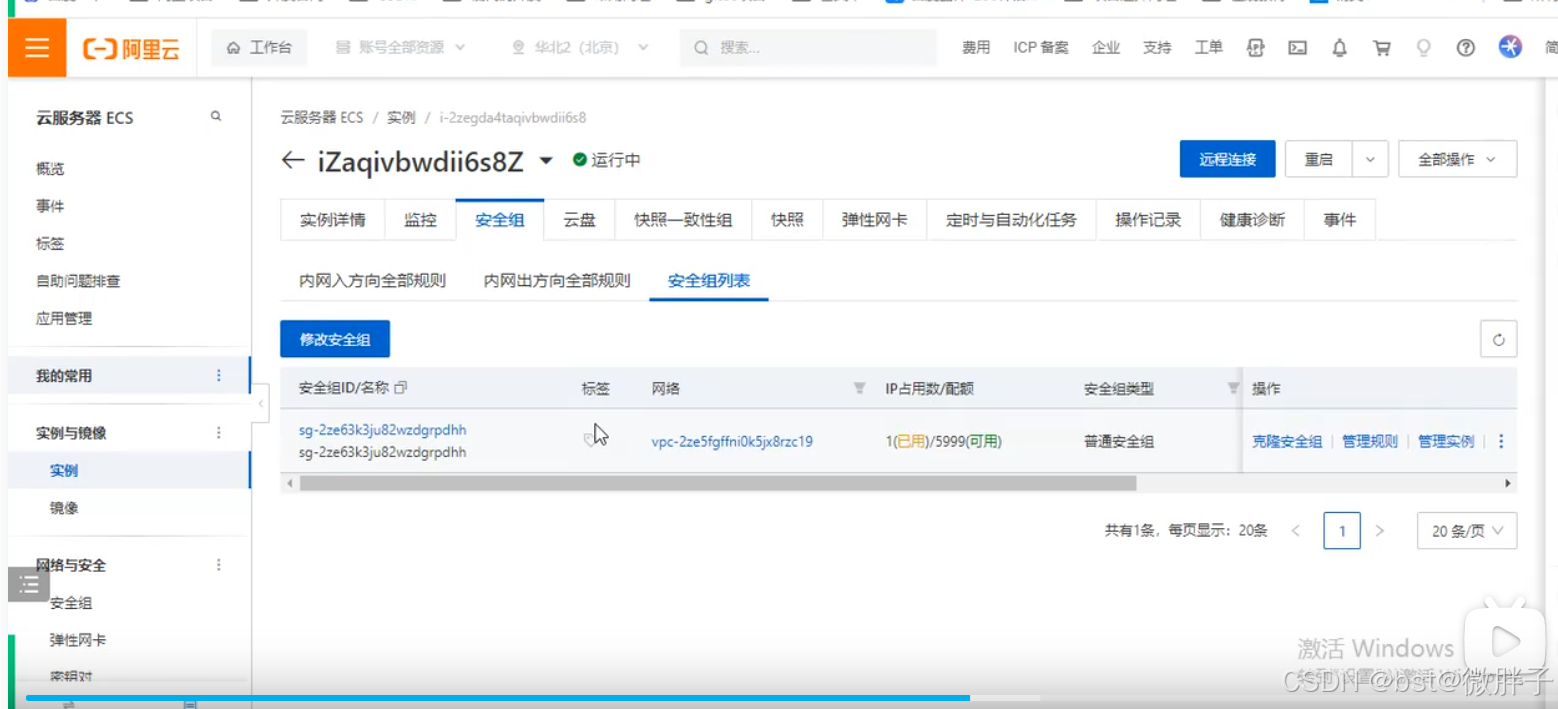

- 实例详情:里面主要显示云服务的内外网地址以及一些启动/停止的操作。
- 监控:里面可以查看一些cpu以及内存,流量等的使用情况。
- 安全组:主要配置网路策略以及进出口端口的开发配置规则。
- 云盘:默认是给定40g的内存存储空间。
- 快照:开启后会定时备份,一旦文件丢了可以通过快照找回。
3、发布静态项目
1、启动nginx

2、ngixn访问
localhost:80访问ngixn这个只能在内网访问,外网访问不了。

外网访问需要配置安全组,将端口暴漏到外网去才能访问。

3、外网访问测试

4、拷贝静态资源到nginx目录下并重启nginx



阿里云官方文档











![[特殊字符][特殊字符][特殊字符][特殊字符][特殊字符][特殊字符]壁紙 流光染墨,碎影入梦](https://i-blog.csdnimg.cn/img_convert/15d418f4f902e772cf45d061bdb459bb.jpeg)






![[samba配置]宿主机访问虚拟机目录](https://i-blog.csdnimg.cn/direct/9f5871e0332f4a4cb980983f325d8062.png#pic_center)
