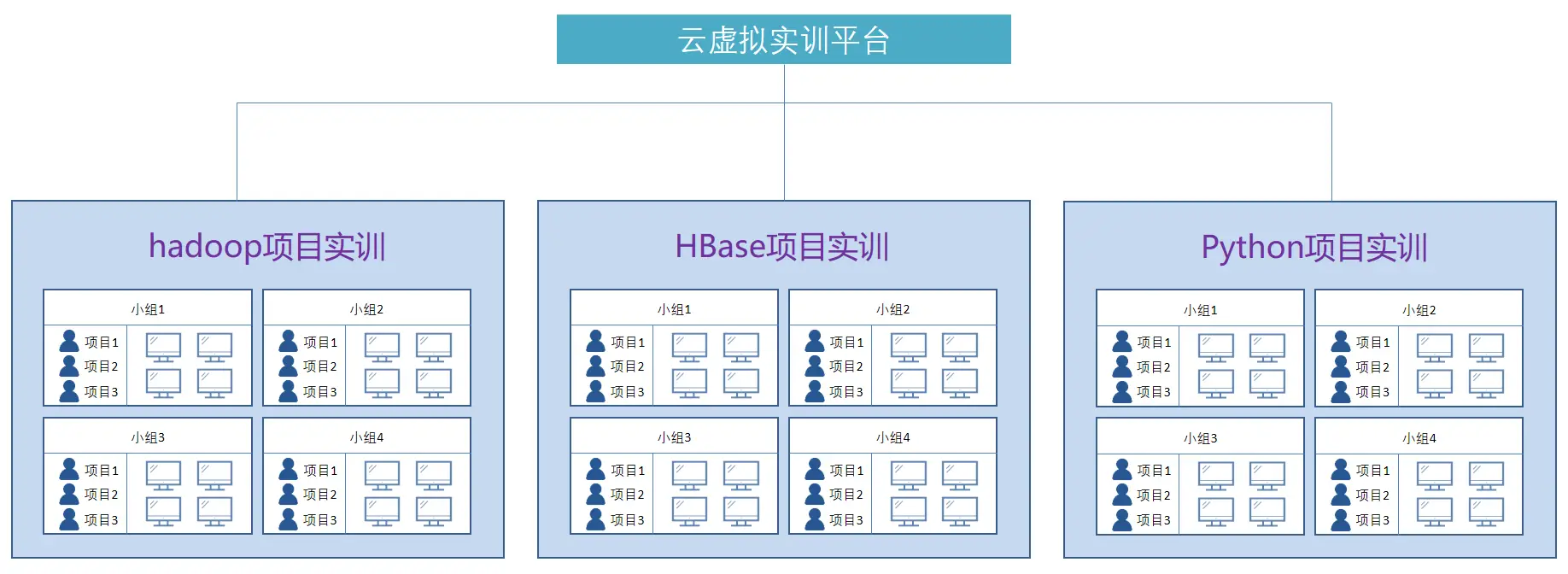
ver0.3
前言
前面我们已经通过三篇文章反反复复的讲Cache的概念、结构、架构,相信大家对Cache已经大概有了初步的了解。这里简单归纳一下:
(1) Cache从硬件视角看,是连接PE-Core和主存的一种存储介质,存储的数据是主存中数据的副本,特点是访问周期极短可以极大的提高PE-Core的执行效率,但是由于价格昂贵,一般容量有限。
(2) Cache的基本结构由Cache Line、Set、Way、Index等组成,通过way的视角看过去,Way中的Cache Line可以通过,直接相联结、组相联、全相联的方式和主存进行映射,但是考虑到实际的效率和成本,ARM采用的是组相联的方式。
(3) CPU使用的虚拟地址是通过一定的映射规则(VIVT、PIPT、VIPT)找到Cache中的Cache Line,这个过程其实就是确定TAG、Index、Offset的过程。
(4) Cache的多级架构,分为传统的Big.Little 和 比较新的DSU (Big.Little)两种架构模式,不同架构下Cache的组织形式也不一样。
上面的一堆一块放在那里还是冷冰冰的硬件,缺乏具体场景下的处理方式介绍,也就是Cache在运行过程中的一些策略问题,例如当CPU要访问一个虚拟地址中的数据,在读和写的过程中,不同的架构下、不同的场景下Cache是如何处理的。
正文
1. 策略相关的概念
我们打算结合具体的架构和场景来讲述Cache的相关策略,这里需要先要明确几个重要的概念:策略执行的单位、策略执行的场景、策略执行的控制器。
1.1 策略执行的单位
首先,我们需要先明确一个事情,就是本文中提到的相关策略的基本对象是Cache Line,换句话说,在ARM处理器中,Cache替换的单位通常被称为“Cache行”(Cache Line)或简称为“行”。这是一个重要的概念,因为它决定了Cache如何管理和替换其内部的数据块。
1.2 策略执行的场景
策略的执行场景大致可以分为:分配时的策略、替换时的策略、回写时的策略。当然我们在分析具体策略的时候要叠加Cache的多级架构,这样场景就更加的复杂一些。
There are a number of different choices that can be made in cache operation. Consider what causes a line from external memory to be placed into the cache (allocation policy) and how the controller decides which line within a set associative cache to use for the incoming data (replacement policy). What happens when the core performs a write that hits in the cache (write policy) must also be controlled.
1.3 策略执行的控制器
如果我们有一个放大镜放大一个PE-Core其实可以发现在CPU的执行单元和Cache之间还有一些电路组织,这个组织就是Cache控制器,如图1-1所示,它实际上也是Cache架构中Cache策略执行的单元。手册中对Cache 控制器有如下的描述:
The cache controller is a hardware block responsible for managing the cache memory, in a way that is largely invisible to the program. It automatically writes code or data from main memory into the cache. It takes read and write memory requests from the core and performs the necessary actions to the cache memory or the external memory.

正是有了Cache控制器,才能够使Cache执行不同的策略,进而是CPU的性能达到最优,那么Cache控制器内部长啥样? 其实由于该控制器对程序员来说是透明,我们不需要关心,但是为了文档的完整性,这里还是贴上来,让大家有一个感性的认识,如图1-2所示。

2. Cache的策略
前面已经明确Cache机制在运行中执行策略的基本概念,下面来详细梳理一下Cache的相关策略。
2.1 分配策略
cache的分配策略是指我们什么情况下应该为数据分配cache line。cache分配策略分为读和写两种情况。
2.1.1 读分配(read allocation)
读分配(read allocation)是指当CPU读数据时,发⽣cache缺失,这种情况下都会分配⼀个cache line,缓存从主存读取的数据。默认情况下,cache都⽀持读分配。
2.1.2 写分配(write allocation)
写分配(write allocation)是指当CPU写数据发⽣cache缺失时,才会考虑写分配策略。当我们不⽀持写分配的情况下,写指令只会更新主存数据,然后就结束了。当⽀持写分配的时候,我们⾸先从主存中加载数据到cache line中(相当于先做个读分配动作),然后会更新cache line中的数据。
2.2 写(更新)策略:
2.2.1 写回(Write Back)
当CPU执行写指令并在Cache命中时,只更新Cache中的数据。将Cache Line中有一个dirty bit来记录数据标记为被修改过。在适当的时候(如Cache Line被替换或显式地刷新),会将修改过的数据写回主存。如图2-1所示:

2.2.2 写直通(Write Through):
当CPU执行写指令并在Cache命中时,会同时更新Cache和主存中的数据。如图2-2所示:

2.3 替换策略
不管是读还是写的过程中,当发生Cache Line未命中的时候,Cache控制器就会从Cache Lines中选择一行进行替换。在使⽤直接相联映射的Cache中,由于每个主内存块都与某个Cache块有直接映射关系,因此不存在替换策略。⽽使⽤全相联映射或组相联映射的Cache,由于主内存块与Cache块没有固定的映射关系,当新的内存块需要加载到Cache中时,且Cache块没有空闲位置,则需要替换到Cache块上的数据,此时就存在替换策略的问题。
2.3.1常见替换策略:
• 随机法(Random):
随机法使⽤⼀个随机数⽣成器,随机地选择要被替换的Cache块。优点是实现简单,缺点是没有利⽤"局部性原理",⽆法提⾼缓存命中率。
• 伪随机(Pseudo-random):
伪随机替换策略是一种简单的缓存(Cache)替换算法,它使用随机或近似随机的方法来选择哪个缓存块(Cache Block)将被替换。
• 先进先出法(FIFO):
记录各个Cache块的加载事件,最早调⼊的块最先被替换。缺点同样是没有利⽤"局部性原理",⽆法提⾼缓存命中率。
• 最近最少使⽤法(LRU):
LRU是通过记录各个Cache块的使⽤情况,最近最少使⽤的块最先被替换。这种⽅法相对⽐较复杂,也有类似的简化⽅法,即记录各个块最近⼀次使⽤时间,最久未访问的最先被替换。与前2种策略相⽐,LRU策略利⽤了"局部性原理",平均缓存命中率更⾼。
• Pseudo-LRU:
Pseudo-LRU是LRU的一种简化实现,它旨在减少实现LRU所需的硬件开销。
• 动态偏置(Dynamic biased replacement policy):
动态偏置是一种高级的缓存替换策略,它在处理缓存替换时,会根据访问模式动态地调整缓存中各个缓存项的替换优先级。与传统的静态替换策略(如LRU、FIFO等)不同,动态偏置替换策略会根据缓存的实际使用情况来动态地调整替换策略。例如,如果某个缓存项在近期被频繁访问,那么它的替换优先级可能会降低,以保留在缓存中更长时间。
• 循环(Round-robin):
在一个Set的Cache Lines中按照way的编号循环挑选Cache Line。
替换策略一般情况下都是在硬件电路的设计阶段就会固定下来,当然有些系列的芯片也会提供系统寄存器作为配置策略的入口,如图2-3、图2-4、图2-5所示。由于每个策略都各有利弊,而且都是硬件实现的,可编程的空间很小,这里就不展开讨论了。



2.3.2 多级cache替换策略
前文中我们已经介绍了Cache的多级架构,那么在替换策略这一点上,多级cache之间是如何表现的,例如L1-Cache发生了替换,L2级别测Cache要如何表现。
先让我们来明确两个概念:Inclusive、Exclusive.

如图2-6所示,如果主存中数据副本必须出同时在L1和L2Cache,那么这个cache就是inclusive,反之就是exclusive。这里直接引用手册中的原文加以说明:
This is an inclusive cache model, where the same data can be present in both the L1 and L2 caches. In an exclusive cache, data can be present in only one cache and an address cannot be found in both the L1 and L2 caches at the same time.
A710
这里我们具象化一个例子来说明多级Cache的替换策略,以cortex-A710为例,如图2-7所示。

这里我们直接引用手册的原文,描述一下基于A710的多级cache的替换策略:
The L1 instruction cache and L2 cache are weakly inclusive. Instruction fetches that miss in the L1 instruction cache and L2 cache allocate both caches, but the invalidation of the L2 cache does not cause back-invalidates of the L1 instruction cache. The L1 data cache and L2 cache are strictly inclusive. Any data contained in the L1 data cache is also present in the L2 cache. Victimization of L2 data can cause invalidations of the L1 data cache.
通过上面的描述,我们可以总结出,基于DynamIQ架构中L1 cache(Cortex-A710)的替换策略:
• Strictly inclusive: 所有存在L1 cache中的数据,必然也存在L2 cache中
• Weakly inclusive: 当miss的时候,数据会被同时缓存到L1和L2,但在之后,L2中的数据可能会被替换。
A720
我们再看一下Cortex-A720的情况,同样是多级Cache架构,如图2-8所示:

这里我们直接引用手册的原文,描述一下基于A710的多级cache的替换策略:
The L1 instruction cache and L2 cache are weakly inclusive. Instruction fetches that miss in the L1 instruction cache and L2 cache allocate both caches, but the invalidation of the L2 cache does not cause back-invalidates of the L1 instruction cache.
The L1 data cache and L2 cache are strictly exclusive. Any data contained in the L1 data cache is never present in the L2 cache.
与A710对比可以发现,A720的多级Cache策略中引入了新的策略strictly exclusive,也就是说随着芯片设计的不断迭代,相关的Cache策略也在迭代升级,关心的时候需要自行查阅一下手册。
• L1 Instruction Cache 和 L2 Cache 执行的还是Weakly inclusive的策略。
• L1 data cache and L2 cache 执行的是 strictly exclusive策略,在L1-Cache中数据和L2 Cache中数据是完全互斥的。
结语
其实本篇应该算是上面一篇文章的姊妹篇,写着写着发现篇幅实在是太长了,就分开了。本文我们介绍了Cache在使用过程中涉及到的一些策略相关的问题,介绍了策略执行的控制器、策略执行的单位、策略执行的场景,以及具体的策略。本文的策略更多是纵向的介绍一条线上(一个PE-Core)Cache使用中遇到的一些情况的处理原则,大部分其实都是硬件逻辑实现的,码农们了解大致的概念和原理就可以了。下一篇才是重点,我们将介绍Cache的一致性问题,也就是纵向的在PE-Cores直接、Cluster之间,共享的数据是如何通过Cache的机制保持一致性的,请大家保持关注。
Reference
[01] <DDI0487K_a_a-profile_architecture_reference_manual.pdf>
[02] <DEN0024A_v8_architecture_PG.pdf>
[03] <80-LX-MEM-yk0008_CPU-Cache-RAM-Disk关系.pdf>
[04] <80-ARM-ARCH-HK0001_一文搞懂CPU工作原理.pdf>
[05] <80-ARM-MM-Cache-wx0003_Arm64-Cache.pdf>
[06] <80-ARM-MM-HK0002_一文搞懂cpu-cache工作原理.pdf>
[07] <80-MM-yd0001_Caches-From-a-Mostly-OS-Software-Perspective.pdf>
[08] <80-MM-yd0002_Improving-Kernel-Performance-by-Unmapping-the-Page-Cache.pdf>
[09] <arm_cortex_a710_core_trm_101800_0201_07_en.pdf>
[10] <DDI0608B_a_armv9a_supplement_RETIRED.pdf>
[11] <arm_cortex_a520_core_trm_102517_0003_06_en.pdf>
[12] <arm_cortex_a720_core_trm_102530_0002_05_en.pdf>
[13] <79-LX-LK-z0002_奔跑吧Linux内核-V-2-卷1_基础架构.pdf>
[14] <80-ARM-MM-Cache-wx0001_Cache多核之间的一致性MESI.pdf>
[15] <80-ARM-MM-Cache-wx0002_深度学习armv8_armv9_cache的原理.pdf>
[16] <80-ARM-MM-Cache-ym0001_带着几个疑问-从Cache的应用场景学起.pdf>
[17] <80-ARM-MM-Cache-ym0002_Cache是如何工作的-概念以及工作过程.pdf>
[18] <80-ARM-MM-Cache-ym0003_多核多Cluster多系统之间的缓存一致性.pdf>
[19] <DDI0500J_cortex_a53_trm.pdf>
[20] <DDI0488H_cortex_a57_mpcore_trm.pdf>
[21] <cortex_a72_mpcore_trm_100095_0003_06_en.pdf>
[22] <corelink_cci550_cache_coherent_interconnect_technical_reference_manual_100282_0100_01_en.pdf>
[23] <80-ARM-DyIQ-wx0001_ARM架构系列(2)-DynamIQ技术.pdf>
[24] <ARM_DynamIQ_The_future_of_multi-core_computing.pdf>
[25] <cortex_a72_mpcore_trm_100095_0003_06_en.pdf>
[26] <arm_cortex_a710_core_trm_101800_0201_07_en.pdf>
[27] <DEN0013D_cortex_a_series_PG.pdf>
[28] <DDI0329L_l220_cc_r1p7_trm.pdf>
Glossary
SRAM - Static Random-Access Memory
DRAM - Dynamic Random Access Memory
SSD - Solid state disk
HDD - Hard Disk Drive
SOC - System on a chip
AMBA - Advanced Microcontroller Bus Architecture 高级处理器总线架构
TLB - translation lookaside buffer(地址变换高速缓存)
VIVT - Virtual Index Virtual Tag
PIPT - Physical Index Physical Tag
VIPT - Virtual Index Physical Tag
AHB - Advanced High-performance Bus 高级高性能总线
ASB - Advanced System Bus 高级系统总线
APB - Advanced Peripheral Bus 高级外围总线
AXI - Advanced eXtensible Interface 高级可拓展接口
DSU - DynamIQ Share Unit
ACE - AXI Coherency Extensions
CHI - Coherent Hub Interface 一致性集线器接口
CCI - Cache Coherent Interconnect
ADB - AMBA Domain Bridge
CMN - Coherent Mesh Network




![[Linux+git+Gitee+Jenkins]持续集成实验安装配置详细](https://i-blog.csdnimg.cn/direct/c042769fa24142b8b5dcebedba50c910.png)