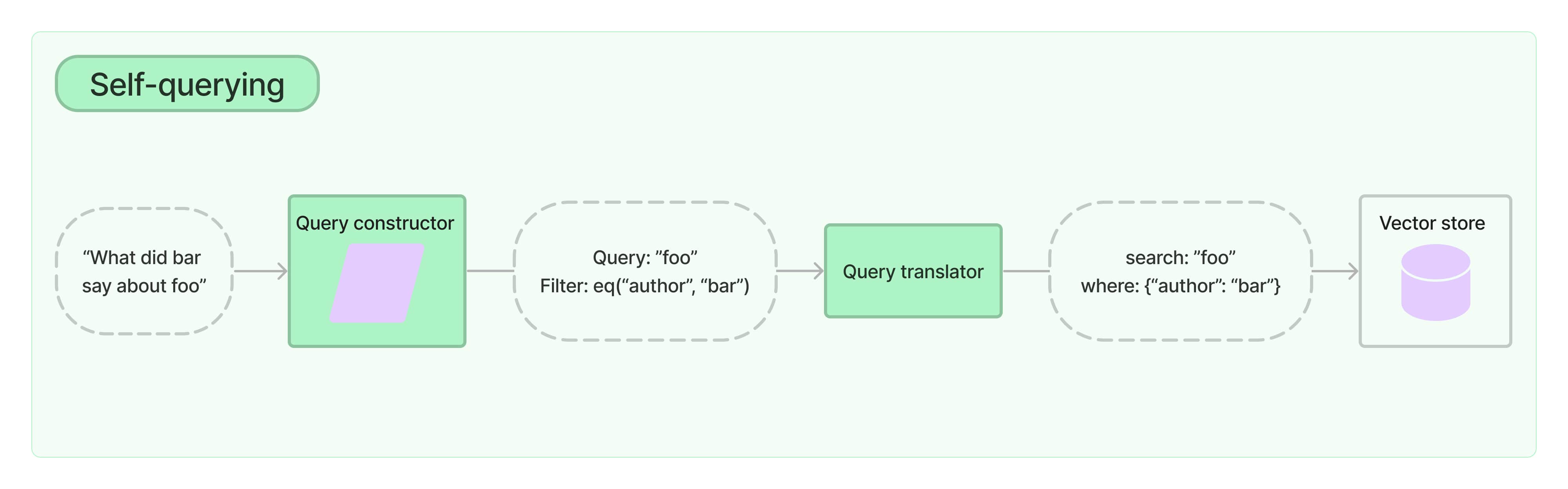
卷积函数的概念
- 卷积核从输入特征图的左上角开始,按照设定的步长(Stride)滑动。步长决定了卷积核每次滑动的像素数,这里我们假设步长
s=1。 - 在每次滑动时,卷积核与输入特征图对应位置的元素相乘,然后将这些乘积相加得到一个输出值。
torch.nn.functional
conv2d卷积函数的参数为例:

参数说明:
input:要求的输入shape为4个。(minibatch,通道,高,宽)
如果输入的input的shape不符合要求,可以通过torch.reshape来进行reshape。
stride:步数,卷积核移动的步长
padding:在图像的上下左右进行填充(填充的数一般设置为0),可以指定一个数,也可以指定一个元组。填充的目的是为了增加感受野,充分利用边缘信息,使里面的数被用到的次数均匀一些。
遇见问题1:为什么二维张量卷积后变成了四维张量呢?
解决办法:在进行规范性输入的时候,二维张量reshpe成了四维张量,所以变成了四维张量。
torch.nn
卷积层:

in_chanels:输入图片的数量,比如,输入一个图片就是in_chanel为1.
out_chanels:输出的由卷积后产物的数量,比如out_chanel=1就是卷积后的产物有一个;out_chanel=2就是卷积核会有两个,每个卷积核分别与输入进行卷积,得到两个卷积后的产物,然后两个叠加起来(三明治有两篇面包)就是一个输出。
dilation: 卷积核对应位的距离
bias:对卷积的结果是否加减一个常数。
groups:分组卷积(一半设置为1,很少使用)
padding:在图像的上下左右进行填充(填充的数一般设置为0),可以指定一个数,也可以指定一个元组。填充的目的是为了增加感受野,充分利用边缘信息,使里面的数被用到的次数均匀一些。
padding_mode:填充模式,选择0填充还是1填充。
import torch
import torchvision
from torch.utils.data import DataLoader
from torch import nn
from torch.nn import Conv2d
from torch.utils.tensorboard import SummaryWriterdataset=torchvision.datasets.CIFAR10('./dataset',train=False,transform=torchvision.transforms.ToTensor(),download=True)dataloader=DataLoader(dataset,batch_size=64)
class WWJ(nn.Module):def __init__(self):super().__init__()self.conv1 =Conv2d(in_channels=3,out_channels=6,kernel_size=3,stride=1)def forward(self,x):x=self.conv1(x)return xwang=WWJ()print(wang)# write=SummaryWriter('logs')
# step=0
for data in dataloader:imgs,targets=dataoutput=wang(imgs)# print(imgs.shape) #torch.Size([64, 3, 32, 32])# print(output.shape) #torch.Size([64, 6, 30, 30])# write.add_images("input",imgs,step)# write.add_image("output",output,step)# step=step+1







![[图解]SysML和EA建模住宅安全系统-14-黑盒系统规约](https://i-blog.csdnimg.cn/direct/af6d1e0854254aa7a8aae60e7b0eec5d.png)