最近有同学在面试遇到了一道非常有深度的面试题:
如何让单机下Netty支持百万长连接?
当时在群里问小北,我发现我也没有系统化的梳理过这个问题,所以一时也没有回答的特别好。
痛定思痛的我赶紧去各种搜集资料,系统化的整理了下这道面试题该怎么回答,能让面试官眼前一亮,直呼内行。
首先我们需要先确认一点:
单机下能不能让我们的网络应用支持百万连接?
答案是:可以是可以,但是需要我们做很多工作。
插播一条:真的免费,如果你近期准备面试跳槽,建议在cxykk.com在线刷题,涵盖 1万+ 道 Java 面试题,几乎覆盖了所有主流技术面试题、简历模板、算法刷题
一、操作系统层面的优化
首先就是要突破操作系统的限制
在Linux平台上,无论是编写客户端程序还是服务端程序,当处理高并发TCP连接时,最大的并发数量通常受到系统对单个用户进程可同时打开文件数量的限制。
这是因为系统为每个TCP连接创建一个socket句柄,而每个socket句柄也是一个文件句柄。
查看和修改文件句柄限制
你可以使用 ulimit 命令查看系统允许当前用户进程打开的文件句柄数限制:
$ ulimit -n
1024 这表示当前用户的每个进程最多允许同时打开1024个句柄。
然而,考虑到标准输入、标准输出、标准错误、服务器监听socket、进程间通信的Unix域socket等文件,实际可用于客户端socket连接的文件数大约为1014个左右。
因此,默认情况下,基于Linux的通信程序最多允许1014个TCP并发连接。
修改单个进程的最大文件数限制
要支持更多的TCP并发连接,可以修改当前用户进程可同时打开的文件数量。最简单的办法是使用 ulimit 命令:
$ ulimit -n 1000000
如果系统回显 “Operation not permitted” 之类的错误,说明上述修改失败。
这是因为指定的数值超过了Linux系统对该用户打开文件数的软限制或硬限制。
因此,需要修改系统对用户的软限制和硬限制。
修改软限制和硬限制
-
软限制 (soft limit):指在系统能够承受的范围内进一步限制一个进程同时打开的文件数。
-
硬限制 (hard limit):根据系统硬件资源(主要是内存)计算出的系统最多可同时打开的文件数量。
第一步:修改 /etc/security/limits.conf 文件
在文件中添加如下行:
* soft nofile 1000000
* hard nofile 1000000
表示修改所有用户的限制;soft 表示警告限制,hard 表示真正限制,nofile 表示最大打开文件数。软限制值应小于或等于硬限制值。保存文件。
第二步:修改 /etc/pam.d/login 文件
在文件中添加如下行:
session required /lib/security/pam_limits.so
这行配置告诉Linux在用户登录后,调用 pam_limits.so 模块来设置系统对该用户的资源数量限制(包括最大文件数限制)。
pam_limits.so 模块从 /etc/security/limits.conf 文件中读取配置来设置这些限制值。保存文件。
第三步:查看和修改系统级最大打开文件数限制
使用如下命令查看系统级的最大打开文件数限制:
$ cat /proc/sys/fs/file-max
12158 这表明该Linux系统最多允许同时打开(所有用户的文件数总和)12158个文件,这是系统级硬限制。
用户级的文件数限制不应超过这个值。
若需修改此限制,编辑 /etc/sysctl.conf 文件:
vi /etc/sysctl.conf
在末尾添加:
fs.file_max = 1000000
使其立即生效:
sysctl -p
插播一条:真的免费,如果你近期准备面试跳槽,建议在cxykk.com在线刷题,涵盖 1万+ 道 Java 面试题,几乎覆盖了所有主流技术面试题、简历模板、算法刷题
Netty调优指南
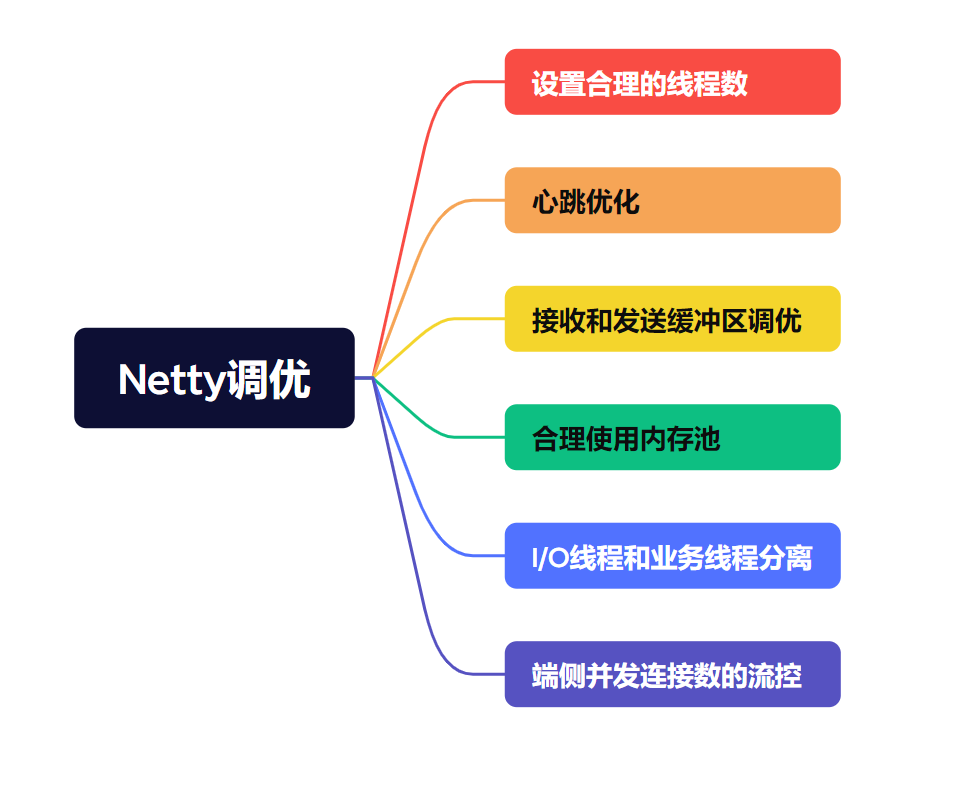
设置合理的线程数
对于线程池的调优,主要集中在用于接收海量设备TCP连接、TLS握手的Acceptor线程池(Netty中称为boss NioEventLoopGroup)和用于处理网络数据读写、心跳发送的I/O工作线程池(Netty中称为work NioEventLoopGroup)。
服务端监听端口和线程模型优化
对于Netty服务端,通常只需启动一个监听端口用于设备接入。如果服务端实例较少,甚至是单机或双机冷备部署,当大量设备在短时间内接入时,需要对服务端的监听方式和线程模型进行优化,以满足短时间内(例如30秒)百万级的设备接入需求。
服务端可以监听多个端口,利用主从Reactor线程模型进行接入优化,前端通过SLB做4层或7层负载均衡。
主从Reactor线程模型的特点如下:
1、服务端用于接收客户端连接的不再是一个单独的NIO线程,而是一个独立的NIO线程池。
2、Acceptor接收到客户端TCP连接请求并处理后(可能包含接入认证等),将新创建的SocketChannel注册到I/O线程池(subReactor线程池)的某个I/O线程,由其负责SocketChannel的读写和编解码工作。
3、Acceptor线程池仅用于客户端的登录、握手和安全认证等。一旦链路建立成功,就将链路注册到后端subReactor线程池的I/O线程,由I/O线程负责后续的I/O操作。
对于I/O工作线程池的优化,可以先采用系统默认值(即CPU内核数×2)进行性能测试。
在性能测试过程中采集I/O线程的CPU占用情况,观察是否存在瓶颈。如果连续采集几次线程堆栈,发现线程堆栈停留在SelectorImpl.lockAndDoSelect,则说明I/O线程比较空闲,无需对工作线程数做调整。如果发现I/O线程的热点停留在读或写操作,或ChannelHandler的执行处,则可以适当增加NioEventLoop线程的数量来提升网络的读写性能。
心跳优化
针对海量设备接入的服务端,心跳优化策略如下:
1、能够及时检测失效的连接,并将其剔除,防止无效连接句柄积压,导致OOM等问题。
2、设置合理的心跳周期,防止心跳定时任务积压,造成频繁的老年代GC,导致应用暂停。
3、使用Netty提供的链路空闲检测机制,不要自己创建定时任务线程池,避免加重系统负担和增加潜在的并发安全问题。
当设备突然掉电、连接被防火墙挡住、长时间GC或通信线程发生非预期异常时,会导致链路不可用且不易被及时发现。
特别是在凌晨业务低谷期间,如果异常发生,当早晨业务高峰期到来时,由于链路不可用会导致瞬间大批量业务失败或超时,严重影响系统可靠性。
从技术层面看,要解决链路的可靠性问题,必须周期性地对链路进行有效性检测。目前最流行和通用的做法是心跳检测。心跳检测机制分为三个层面:
1、TCP层的心跳检测:即TCP的Keep-Alive机制,作用于整个TCP协议栈。
2、协议层的心跳检测:主要存在于长连接协议中,例如MQTT。
3、应用层的心跳检测:由各业务产品通过约定方式定时发送心跳消息实现。
心跳检测的目的是确认当前链路是否可用,对方是否活着并且能够正常接收和发送消息。作为高可靠的NIO框架,Netty也提供了心跳检测机制。一般的心跳检测策略如下:
- 连续N次心跳检测都没有收到对方的Pong应答消息或Ping请求消息,则认为链路已经发生逻辑失效,这被称为心跳超时。
- 在读取和发送心跳消息时如果直接发生了I/O异常,说明链路已经失效,这被称为心跳失败。
无论发生心跳超时还是心跳失败,都需要关闭链路,由客户端发起重连操作,保证链路恢复正常。Netty提供了三种链路空闲检测机制,利用该机制可以轻松实现心跳检测:
1、读空闲:链路持续时间T内没有读取到任何消息。
2、写空闲:链路持续时间T内没有发送任何消息。
3、读写空闲:链路持续时间T内没有接收或发送任何消息。
对于百万级的服务器,一般不建议设置很长的心跳周期和超时时长。
接收和发送缓冲区调优
在一些场景下,端侧设备会周期性地上报数据和发送心跳,单个链路的消息收发量并不大。针对这种场景,可以通过调小TCP的接收和发送缓冲区来降低单个TCP连接的资源占用率。当然,对于不同的应用场景,收发缓冲区的最优值可能不同,需要根据实际场景结合性能测试数据进行调优。
合理使用内存池
随着JVM虚拟机和JIT即时编译技术的发展,对象的分配和回收已是非常轻量级的工作。然而,对于缓冲区Buffer情况却稍有不同,特别是堆外直接内存的分配和回收,是一个耗时的操作。为了尽量重用缓冲区,Netty提供了基于内存池的缓冲区重用机制。
在百万级连接情况下,需要为每个接入的设备至少分配一个接收和发送ByteBuf缓冲区对象。采用传统的非池模式,每次消息读写都需要创建和释放ByteBuf对象。如果有100万个连接,每秒上报一次数据或心跳,就会有100万次/秒的ByteBuf对象申请和释放,即便服务端的内存可以满足要求,GC压力也会非常大。
最有效的解决方法是使用内存池。每个NioEventLoop线程处理N个链路,在线程内部链路的处理是串行的。假如A链路首先被处理,它会创建接收缓冲区等对象,待解码完成后将构造的POJO对象封装成任务投递到后台线程池中执行,然后接收缓冲区被释放。每条消息的接收和处理都会重复接收缓冲区的创建和释放。如果使用内存池,当A链路接收到新数据报时,从NioEventLoop的内存池中申请空闲的ByteBuf,解码后调用release将ByteBuf释放到内存池中,供后续的B链路使用。
Netty内存池从实现上可以分为两类:堆外直接内存和堆内存。由于ByteBuf主要用于网络I/O读写,因此采用堆外直接内存会减少一次从用户堆内存到内核态的字节数组拷贝,所以性能更高。由于DirectByteBuf的创建成本较高,因此如果使用DirectByteBuf,需要配合内存池使用,否则性价比可能还不如HeapByteBuf。
Netty默认的I/O读写操作采用内存池的堆外直接内存模式。如果需要额外使用ByteBuf,建议也采用内存池方式;如果不涉及网络I/O操作(只是纯粹的内存操作),可以使用堆内存池,这样内存创建效率更高。
I/O线程和业务线程分离
如果服务端不做复杂的业务逻辑操作,仅是简单的内存操作和消息转发,可以通过调大NioEventLoop工作线程池的方式,直接在I/O线程中执行业务ChannelHandler,从而减少一次线程上下文切换,性能反而更高。如果有复杂的业务逻辑操作,建议I/O线程和业务线程分离。由于I/O线程之间不存在锁竞争,可以创建一个大的NioEventLoopGroup线程组,所有Channel共享同一个线程池。
对于后端的业务线程池,建议创建多个小的业务线程池,线程池可以与I/O线程绑定,这样既减少了锁竞争,又提升了后端的处理性能。
端侧并发连接数的流控
无论服务端性能优化到何种程度,都需要考虑流控功能。当资源成为瓶颈或遇到大量设备接入时,需要通过流控对系统进行保护。流控策略有很多种,针对端侧连接数的流控是其中之一。
在Netty中,可以方便地实现流控功能:新增一个FlowControlChannelHandler,并添加到ChannelPipeline靠前的位置,覆盖channelActive()方法。创建TCP链路后,执行流控逻辑,如果达到流控阈值,则拒绝该连接,调用ChannelHandlerContext的close()方法关闭连接。
插播一条:真的免费,如果你近期准备面试跳槽,建议在cxykk.com在线刷题,涵盖 1万+ 道 Java 面试题,几乎覆盖了所有主流技术面试题、简历模板、算法刷题
JVM层面相关性能优化
当客户端的并发连接数达到数十万甚至数百万时,系统的一个较小抖动就会导致严重后果。
例如,服务端的GC(垃圾回收)可能导致应用暂停(STW),持续几秒钟,这会导致海量客户端设备掉线或消息积压。一旦系统恢复,海量设备接入或数据发送很可能瞬间将服务端冲垮。
GC参数优化
JVM层面的调优主要涉及GC参数优化。如果GC参数设置不当,会导致频繁GC,甚至OOM异常,影响服务端的稳定运行。
确定GC优化目标
GC(垃圾收集)有三个主要指标:
1、吞吐量:评价GC能力的重要指标。在不考虑GC引起的停顿时间或内存消耗时,吞吐量是GC能支撑应用程序达到的最高性能指标。
2、延迟:GC能力的重要指标之一,是由于GC引起的停顿时间。优化目标是缩短延迟时间或完全消除停顿(STW),避免应用程序在运行过程中发生抖动。
3、内存占用:GC正常时占用的内存量。
JVM GC调优的三个基本原则:
1、Minor GC回收原则:
每次新生代GC回收尽可能多的内存,减少应用程序发生Full GC的频率。
2、GC内存最大化原则:
垃圾收集器使用的内存越大,垃圾收集效率越高,应用程序运行越流畅。但是过大的内存一次Full GC耗时较长,需要精细化调优以避免Full GC。
3、三选二原则:
吞吐量、延迟和内存占用不能兼得,无法同时达到最优。需要根据业务场景选择优先级。对于大多数应用,吞吐量优先,其次是延迟。对于时延敏感型业务,需要调整次序。
确定服务端内存占用
在优化GC之前,需要确定应用程序的内存占用大小,以便设置合适的内存,提升GC效率。内存占用与活跃数据有关,活跃数据是指应用程序稳定运行时长时间存活的Java对象。
活跃数据的计算方式:通过GC日志采集GC数据,获取应用程序稳定时老年代占用的Java堆大小,以及永久代(元数据区)占用的Java堆大小,两者之和即为活跃数据的内存占用大小。
GC优化过程
1、GC数据的采集和研读:通过GC日志采集数据,分析GC情况。
2、设置合适的JVM堆大小:根据应用程序的内存占用,设置合适的JVM堆大小。
3、选择合适的垃圾回收器和回收策略:根据应用场景选择合适的垃圾回收器和回收策略。
最后说一句(求关注,求赞,别白嫖我)
最近无意间获得一份阿里大佬写的刷题笔记,一下子打通了我的任督二脉,进大厂原来没那么难。
这是大佬写的, 7701页的BAT大佬写的刷题笔记,让我offer拿到手软
本文,已收录于,我的技术网站 cxykk.com:程序员编程资料站,有大厂完整面经,工作技术,架构师成长之路,等经验分享
求一键三连:点赞、分享、收藏
点赞对我真的非常重要!在线求赞,加个关注我会非常感激!
真的免费,如果你近期准备面试跳槽,建议在cxykk.com在线刷题,涵盖 1万+ 道 Java 面试题,几乎覆盖了所有主流技术面试题、简历模板、算法刷题