语言模型与表征学习(Language Models and Representation Learning)
1 语言模型
N-Gram模型


from collections import defaultdictsentences = ['The swift fox jumps over the lazy dog.','The swift river flows under the ancient bridge.','The swift breeze cools the warm summer evening.']preprocesses_sentences = [["<s>"] + sentence.lower().replace(".","").split() + ["</s>"] for sentence in sentences]
print(preprocesses_sentences)bigram_model = defaultdict(lambda: defaultdict(lambda: 0))for sentence in preprocesses_sentences:for w1, w2 in zip(sentence[:-1], sentence[1:]):bigram_model[w1][w2] += 1
print(bigram_model)for w1 in bigram_model:total_count = float(sum(bigram_model[w1].values()))for w2 in bigram_model[w1]:bigram_model[w1][w2] /= total_count
print(bigram_model)bigram_model_probs = {w1: dict(w2) for w1, w2 in bigram_model.items()}
print(bigram_model_probs)
参考资料:
1 了解N-Gram模型
2 语言模型
神经网络语言模型(NNLM)

import torch
import torch.nn as nn
import torch.optim as optimsentences = ["i like dog", "i love coffee", "i hate milk"]word_list = " ".join(sentences).split() # 制作词汇表
print(word_list)
word_list = list(set(word_list)) # 去重
print("after set: ", word_list)
word_dict = {w: i for i, w in enumerate(word_list)} # 每个单词对应的索引
number_dict = {i: w for i, w in enumerate(word_list)} # 每个索引对应的单词
n_class = len(word_dict) # 单词总数# NNLM Parameter
n_step = 2 # 根据前两个单词预测第3个单词
n_hidden = 2 # h 隐藏层神经元的个数
m = 2 # m 词向量的维度def make_batch(sentences):input_batch = []target_batch = []for sen in sentences:word = sen.split()input = [word_dict[n] for n in word[:-1]]target = word_dict[word[-1]]input_batch.append(input)target_batch.append(target)return torch.LongTensor(input_batch), torch.LongTensor(target_batch)class NNLM(nn.Module):def __init__(self):super(NNLM, self).__init__()self.C = nn.Embedding(n_class, m)self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(torch.FloatTensor))self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(torch.FloatTensor))self.d = nn.Parameter(torch.randn(n_hidden).type(torch.FloatTensor))self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(torch.FloatTensor))self.b = nn.Parameter(torch.randn(n_class).type(torch.FloatTensor))def forward(self, X):X = self.C(X)X = X.view(-1, n_step * m) # [batch_size, n_step * n_class]tanh = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden]output = self.b + torch.mm(X, self.W) + torch.mm(tanh, self.U) # [batch_size, n_class]return outputmodel = NNLM()criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)input_batch, target_batch = make_batch(sentences)# Training
for epoch in range(5000):optimizer.zero_grad()output = model(input_batch)# output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)loss = criterion(output, target_batch) # 求lossif (epoch + 1) % 1000 == 0:print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))loss.backward()optimizer.step()# Predict
predict = model(input_batch).data.max(1, keepdim=True)[1]# Test
print([sen.split()[:2] for sen in sentences], '->', [number_dict[n.item()] for n in predict.squeeze()])
参考资料:
1 【NLP】神经网络语言模型(NNLM)
2 A Neural Probabilistic Language Model_论文阅读及代码复现pytorch版
3 语言模型
2 词表示
Word2vec
Word2vec是一种用于生成词嵌入的算法,它通过分析词在文本中的上下文来捕捉词的语义信息。利用海量的文本序列,根据上下文单词预测目标单词共现的概率,让一个构造的网络向概率最大化优化,得到的参数矩阵就是单词的向量。
Word2vec算法模型
Word2vec算法包含两种主要的模型,每种模型都以不同的方式利用上下文来学习词的向量表示:
连续词袋模型(CBOW):
- 在CBOW模型中,上下文词被用来预测它们中间的目标词。这种方法将上下文视为一个整体,不考虑词的顺序,类似于一个“词袋”。
- 给定一个目标词,CBOW模型会考虑其周围的词,并尝试基于这些上下文词来预测目标词。

Skip-gram模型:
- 与CBOW相反,Skip-gram模型使用单个词来预测它的上下文。这种模型适合于处理较大的词汇表,并且能够更精确地捕捉词与上下文之间的关系。
- Skip-gram模型的名称来源于其能力,可以“跳过”目标词并预测其周围的词,即使这些词在句子中的位置相隔较远。
两种模型都通过优化神经网络的权重来学习词的向量表示,使得词向量能够捕捉到词义和上下文的复杂关系。通过这种方式,word2vec能够为每个词生成一个连续的向量空间中的点,这些点在向量空间中的相对位置反映了词之间的语义相似性。

Word2vec加快训练速度
Word2vec的实现中,有两种主要的技术用于提高训练效率和处理大数据集:层次Softmax(Hierarchical Softmax)和负采样(Negative Sampling)。
Hierarchical Softmax(层次Softmax)
层次Softmax用于加速Softmax层的计算过程,核心思想是将条件概率估计可以转换为 l o g 2 ∣ V ∣ log_{2}|V| log2∣V∣ 个两类分类问题。在传统的Softmax中,计算所有词汇的概率分布需要对词汇表中的每个词进行操作,这在大规模词汇表中非常耗时。
- 构建二叉树:层次Softmax首先基于词汇表构建一个二叉树,每个节点代表一个词汇,叶子节点是词汇表中的词,内部节点是虚拟的词。
- 从根到叶的路径:对于每个目标词,都有一个从根节点到该词所在叶子节点的路径。
- 路径上的节点进行二分类:在这条路径上,模型只需要对每个内部节点做出是向左子树还是向右子树的二分类决策,而不是在整个词汇表上进行多分类。
- 减少计算量:这种方法显著减少了计算量,因为每次只对词汇表中的一部分进行操作,而不是全部词汇。
Negative Sampling(负采样)
负采样是另一种提高训练效率的技术,,核心思想是将条件概率转化为多个二分类问题,特别是在处理大规模数据集时。
- 选择正样本:在每次迭代中,除了目标词(正样本)之外,还会随机选择几个“噪声词”作为负样本。
- 训练二分类器:模型被训练为将正样本与负样本区分开来。这通过多次二分类问题来近似Softmax的多分类问题。
- 减少计算复杂度:与层次Softmax不同,负采样不需要构建树结构,但它通过减少每次迭代中考虑的词的数量来降低计算复杂度。
- 参数调整:负采样中的关键是负样本的数量,这需要根据具体任务和数据集进行调整。
层次Softmax和负采样都是word2vec中用于提高训练效率的技术。层次Softmax通过构建词汇的二叉树结构来减少Softmax层的计算量,而负采样通过引入负样本来近似Softmax的输出分布,两者都能在保持词向量质量的同时加快模型的训练速度。在实际应用中,根据数据集的大小和训练资源,可以选择其中一种或两种技术的组合来优化word2vec的训练过程。
word2vec的训练过程:以CBOW为例
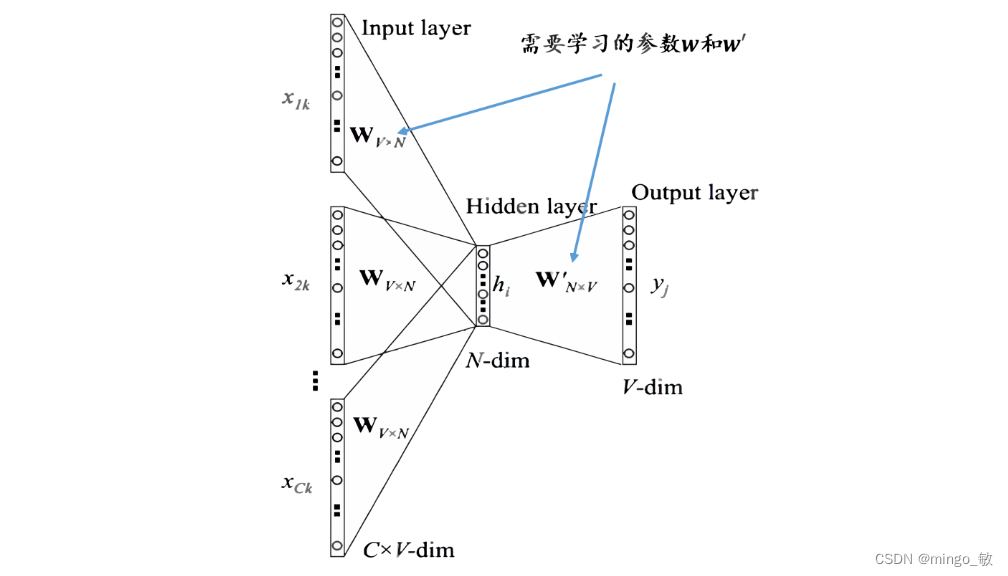
假设我们有句子 “I learn NLP everyday”,并且我们用 “I”, “learn”, “everyday” 作为上下文来预测 “NLP”。
-
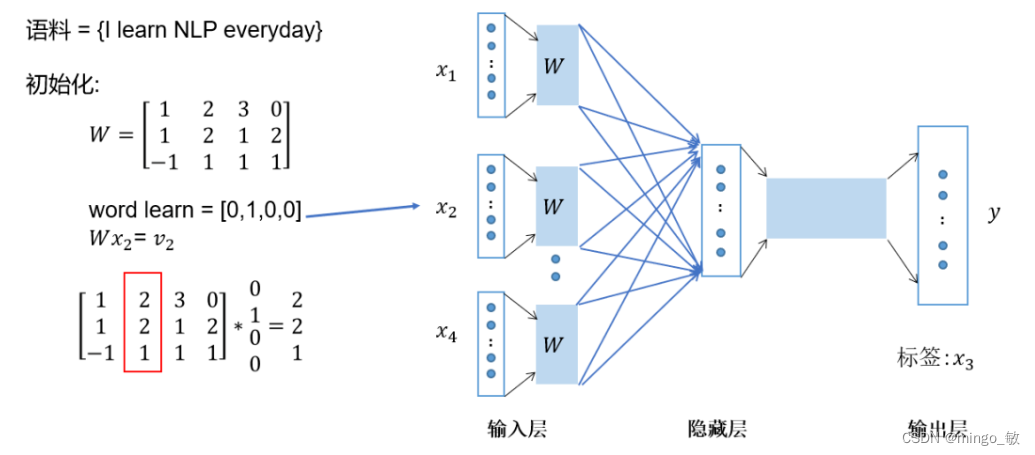
One-hot编码:将上下文词 “I”, “learn”, “everyday” 转换为one-hot向量。

-
嵌入矩阵乘法:将one-hot向量与嵌入矩阵相乘,得到上下文词的向量化表示。
-
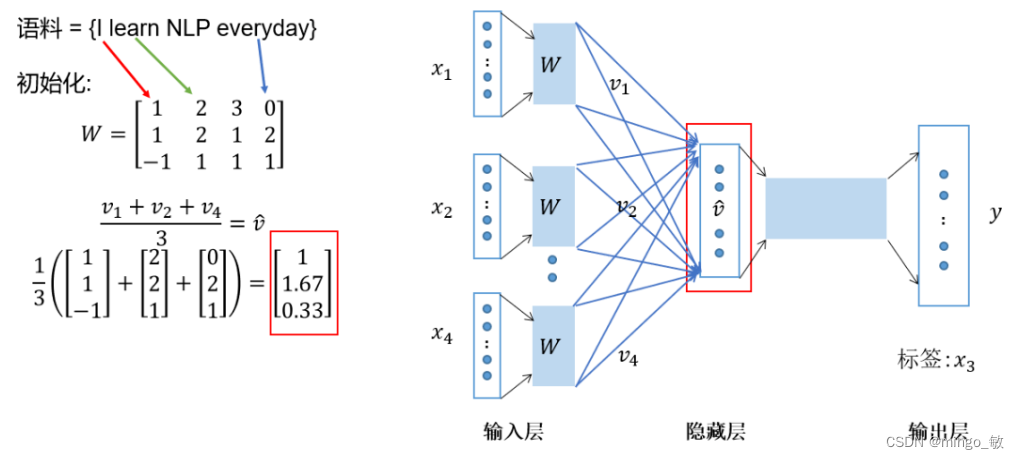
求平均:将这些向量相加后求平均,形成CBOW模型的隐藏层表示。
-
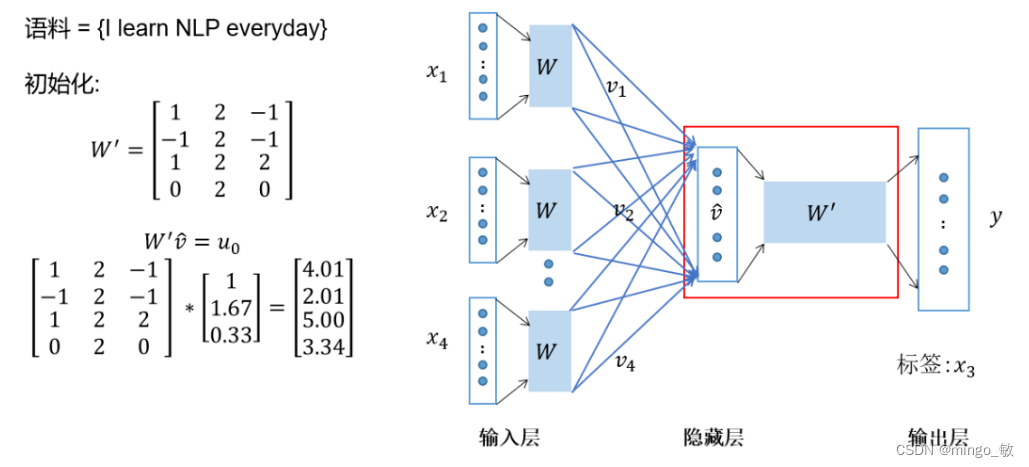
预测计算:将隐藏层表示与另一个嵌入矩阵相乘,得到预测词的原始分数。
-
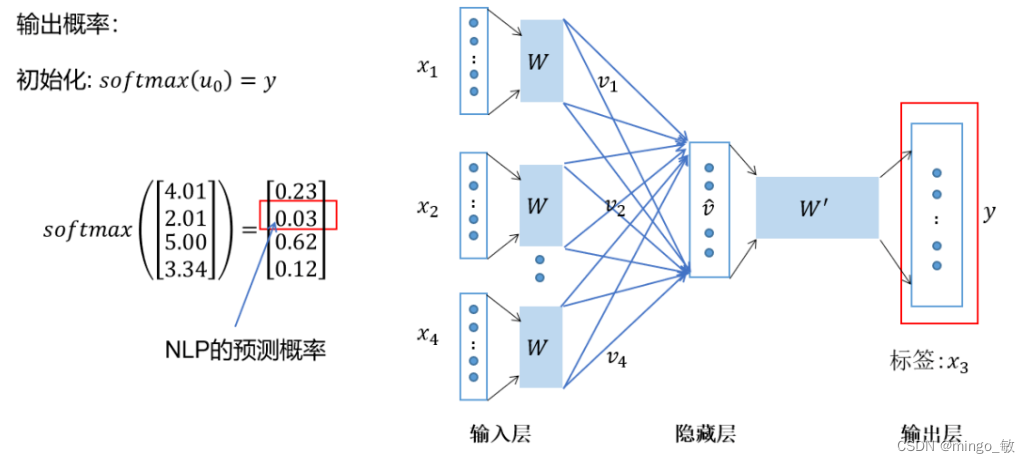
Softmax输出:通过Softmax函数将原始分数转换为概率,选择概率最高的词作为预测结果。
-
损失计算与优化:计算预测结果与实际目标词之间的损失,并使用梯度下降等优化算法来调整权重矩阵。
参考资料:
1 【NLP】图解词嵌入和Word2vec
2 深入理解word2vec
3 详解Word2Vec,从理论到实践让你从底层彻底了解Word2Vec!



![【BUG】已解决:OSError: [Errno 22] Invalid argument](https://img-blog.csdnimg.cn/direct/df413fc3bbea46f7962bc7fe31fa6a01.png)