0 小序
本文的写作起因是导师要求我给打算参加相关竞赛的师弟们做一次讲座和汇报。我梳理了一个ppt提纲,并经过整理,因此有了这篇文章。
我打算从数学建模论文写作格式和写作技巧入手,接着介绍数学建模常用的数学模型,最后提出一点自己的建议。
首先,首先先来介绍下数学建模比赛是什么,有哪些数学建模比赛。
1 数学建模比赛一览和简单介绍
1.1 数学建模比赛的介绍
提到数学竞赛,也许你的脑海里浮现的是这样的画面:鸦雀无声的教室里,考生奋笔疾书,争分夺秒,监考老师在走道里巡视,步步惊心。
但数学建模竞赛不是这样,那数学建模竞赛是什么?
数学建模是指对现实世界的某一特定对象,为了特定的目的,做出一些重要的简化和假设,运用适当的数学工具得到一个数学结构,用它来解释特定的现象的实现性态,预测对象的未来状况,提供处理对象的优化决策和控制,设计满足某种需要的产品等。
————肖华勇·《大学生数学建模竞赛指南》
简单来说,数学建模是一个研究给出现象中的数学规律的比赛。一般体现在以下几个方面。第一,发生了什么?第二,为什么会发生这样的情况?第三,未来会如何发展?第四,目前该如何决策?这便是数学建模比赛中书写论文的几个出发点,也是科学研究的出发点。
接下来,将介绍常见的数学建模比赛。
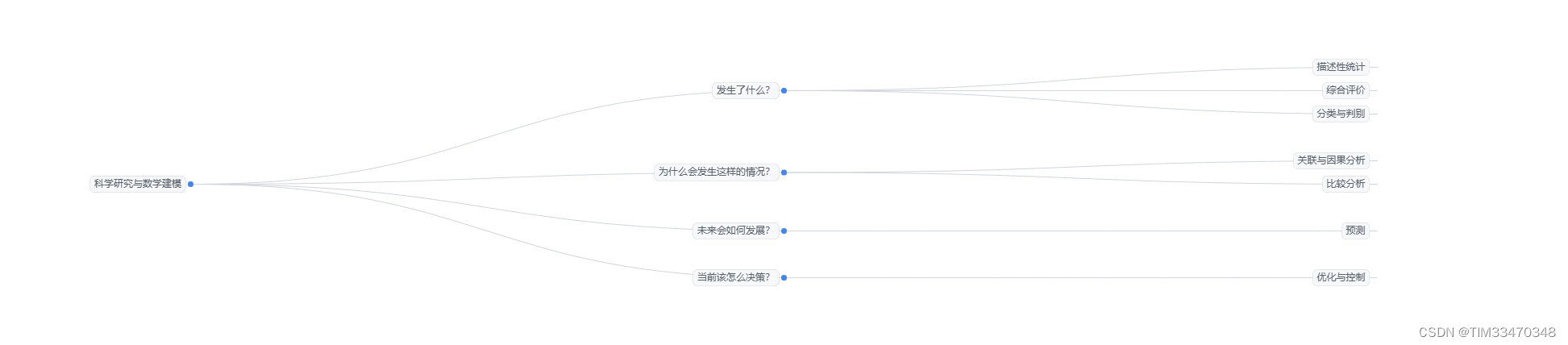
在1-1图中,本文在脑图的末端已经提到了几个常用的数学方法,本文将在后面进行更细致的介绍。
1.2 数学建模比赛一览
图1-2是网上流传的数学建模比赛含金量一览表,它将比赛划分成四类:

A类是目前数学建模的顶级赛事,是含金量最高的数学建模比赛。
B类是含金量较高的比赛,有些比赛奖金不菲,其中“妈妈杯”是指mathorcup比赛在选手中的口耳相传的俗称。
C类含金量次之,是一些地区赛和一些稍有含金量的比赛。例如五一杯和华中杯还有东三省数学建模联赛是老牌的地区赛。
D类是水赛,含金量最低。
其中,我们学校启航网认可的比赛有国赛、美赛、东三省数学建模联赛和mathorcup大数据,综测加分。新手小白在参加顶赛之前,建议找一些含金量次之的比赛先练练手,一是提高比赛的熟悉度,二是可以磨合队友。
以上就是本章的全部,接下来介绍数学建模中论文结构。
2 数学建模论文写作结构
本文将从国赛和美赛两方面,介绍数学建模论文的结构和写作时需要注意的点。我们先从国赛入手。
2.1 国赛论文写作结构
国赛论文写作分为以下几个部分:
- 摘要
- 1 问题重述
- 2 问题分析
- 3 模型假设
- 4 符号说明
- 5 模型建立
- 6 模型求解
- 7 结论
- 8 模型评价/模型推广
- 参考文献
- 附录

2.2 美赛论文写作结构
美赛的结构和国赛的结构差不多,因为国赛当初就是借鉴美赛而举办的。美赛的论文结构如下:
- Summary 摘要
- 1 Introduction 问题重述
- 2 Symbol Descriptions 符号说明
- 3 Model Hypothesis 模型假设
- 4 Our Solutions 模型建立与求解
- 5 Model Extensions 模型推广
- 6 The strengths and weakness of the model 模型的不足
- 7 Conclusions 结论
- References 参考文献
- Appendix 附录
2.3 各个部分的写作方法
2.3.1 摘要
摘要是一篇论文的整体风貌,对于获奖至关重要。字数一般在400-800字,不建议超过一页纸。内容包括:参赛队对题意的理解、模型类型、建模思路、求用的求解方法及求解思路、算法特点、灵敏度分析、模型检验、主要数值结果和结论。摘要下一行还需要选取3-5个关键词,体现研究内容、算法。
总之,摘要可以分为三大部分:
- 背景介绍:2-4行即可。
- 主体部分:一个问题一个问题的阐述,每个问题一个自然段,按照用了什么样的数学方法、解决了怎样的问题、得到了怎样的结果与结论的格式来写。
- 结尾:阐述模型的优缺点即可。
2.3.2 问题重述
不建议抄题。用自己的语言重新描述问题。可以适当加入自己查到的背景资料及前人研究现状。只能阐述问题,不能掺杂主观见解。
按照以下三部分描述即可:
- 问题背景
- 文献综述(前人的工作)
- 本文的工作
2.3.3 问题分析/Our Solutions的开头
介绍三个内容:
- 为什么要这样做?(原因)
- 为什么要用这个方法?(上述原因与数学模型间的联系)
- 为社么要用这些变量?(选择变量的原因,一般通过“关联,因果,比较”得到)
美赛没有问题分析这个小标题,一般在Our Solutions的开头描述。
2.3.4 模型假设
对问题进行分析后,发现有些因素或条件还无法进行考虑或估算;或是针对问题的主要因素。舍弃次要因素的影响,采用假设的方式,使问题简化。
一些假设是基本假设,几乎每篇论文都会有。一些假设在建立模型过程中提出,随时记下,最后总结在一起。力求简洁明确。
这部分可以单独写也可以在模型建立时根据所需要情况再进行描述。
2.3.5 符号说明
列一个表格,说明本文的符号的含义即可。以简要文字表述各字母意义,其中各个主要符号的大小写、英语和阿拉伯语,要与正文中符号一致,通常采用三线表,切忌重复或及其近似。
2.3.6 模型建立与求解
美赛要先写问题分析,国赛的话需要单独列一个一级标题些问题分析,这里就不用再写了。
传统的数学建模问题一般分为连续性和离散型两类问题。连续型问题一边又分为微分方程、统计类、大数据类三种。我对连续型问题较为熟悉,故以此为例,描述连续型问题的“模型建立与求解”这一节该怎么写。
首先要数据预处理:也就是介绍数据来源(有些题题目不提供数据),如何整理(规范化)数据(即修改数据格式),如何清洗?(也就是处理异常值、缺失值)
接着,选取指标。需要运用相关性分析,非参数统计检验等
然后,建立模型。根据不同的目的:预测、相关性分析、分类、判别和评价等建立相应的模型。
下一步,模型检验,通过统计检验,例如t检验、r检验、f检验等
下一步,模型求解,进行预测、评价、相关性分析、分类判别等操作。
最后,得到结论,进行结论分析。进行完结论分析后,分析结果形成的原因,并提出建议和对策。
以上就是连续类问题“模型建立与求解”过程的书写步骤。下一节介绍常用的数学建模方法。
3 常用的数学建模方法
在第一节中,本文交代了数学建模是一个研究给出现象中的数学规律的比赛。一般体现在以下四个方面。
- 发生了什么? 可以通过描述性统计,综合评价分析,分类与判别解决。
- 为什么会发生这样的情况?可以通过关联与因果分析、比较分析解决。
- 未来会如何发展?通过预测解决
- 目前该如何决策?通过优化与控制来解决。
这里,上文的4点末尾给出了对应的解决方案,这里本文将介绍常见的对应的解决方案。
3.1 综合评价
综合评价将多维指标降为一维,从而确定排序、分类判别和最优方案的结果。
分类:模糊综合评价法
排序:主成分分析法
最优方案:层次分析法、优劣解距离法(Topsis评价法)、灰色关联分析
3.2 分类与判别
- 聚类
- 贝叶斯判别
- 费舍尔判别
- 各种神经网络
- 支持向量机
3.3 关联、因果与比较
- Person皮尔逊相关、Sperman斯皮尔曼相关(相关性)
- 标准化回归(1对多)
- 偏最小二乘回归(多对多)
- 主成分分析、岭回归(变量内部关系)
- 格兰杰因果检验(因果检验)
3.4 预测-单序列
- 时间序列arima
- 灰色预测,适用于小样本
- 马尔可夫预测
- 神经网络
3.5 预测-非单序列
- 向量自回归VaR
- 线性回归
- logistic回归
- Probit回归
3.6 优化与控制
- 线性规划
- 0-1规划
- 整数规划
- 网络优化
- 排队论