目录
1. 前言
2. 基本概念
2.1. Word2Vec
2.2. Attention is all you need
2.3. Self-attention
2.3.1. 概述self-attention
2.3.2. 训练细节
2.4. Multi-head Attention
2.4.1. 多头理论细节
2.4.2. 多头代码实现
2.5. 总结
3. 讨论观点
3.1. 观点1:
3.2. 观点2:
3.3. 观点3
3.4. 观点4:
3.5. 观点5:
3.6. 观点6:
3.7. 个人观点
4. 总结
1. 前言
这篇文章是华为云共创的一个任务,当看到主题的时候也是很感兴趣,整个的讨论在知乎,原链接:https://www.zhihu.com/question/341222779,看这个讨论量就知道这个主题是有很多人在关注,这里我根据自己对这件事的理解以及对一些帖子的理解整理下,希望能完整的说明这件事情。
2. 基本概念
为了能让大部分都知道在说什么,这里有一些前置概念先解释下,以便大家都在同一个知识背景下,在后续的文章中尽可能得避免公式的表述。
2.1. Word2Vec
Word2Vec的主要作用是生成词向量,而词向量与语言模型有着密切的关系。Word2Vec的特点是能够将单词转化为向量来表示,这样词与词之间就可以定量的去度量他们之间的关系,挖掘词之间的联系。
Word2Vec模型在自然语言处理中有着广泛的应用,包括词语相似度计算、文本分类、词性标注、命名实体识别、机器翻译、文本生成等。其主要目的是将所有词语投影到K维的向量空间,每个词语都可以用一个K维向量表示。Word2Vec 的最重要的目的是将语言化为机器能理解的方式,可以简单理解为一个字的身份证号码。
Word2Vec 模型通过训练神经网络,为每个单词构建一个密集且连续的向量。这些向量被称为 词嵌入(word embeddings),它们捕捉大量关于单词的语义和句法信息。每个单词在多维空间中被表示为一个向量,向量中的每个维度代表词义的不同方面,具体每个维度代表什么并不是人为定义的,而是通过模型学习得到 的。通过 Word2Vec 得到的词向量 拥有相似上下文的词在空间中的位置,能够捕捉单词之间的语义关系。
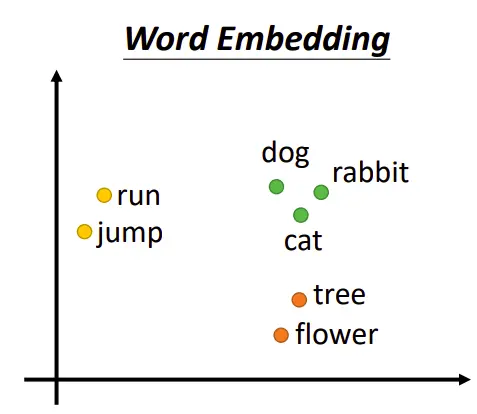
注:GPT-3 的embedding维数是12288
2.2. Attention is all you need
Attention(注意力)机制核心逻辑就是「从关注全部到关注重点」。
Attention机制是模仿人类注意力而提出的一种解决问题的办法,简单地说就是从大量信息中快速筛选出高价值信息。主要用于解决LSTM/RNN模型输入序列较长的时候很难获得最终合理的向量表示问题,做法是保留LSTM的中间结果,用新的模型对其进行学习,并将其与输出进行关联,从而达到信息筛选的目的。
2.3. Self-attention
2.3.1. 概述self-attention
我们需要一个智能系统来学习单词之间的重要关系,就像人类理解句子中的单词一样。在下图中,你我都知道“The”指的是“animal”,因此应该与这个词有很强的联系。如图中的颜色编码所示,该系统知道“animal”、“cross”、“street”和“the”之间存在某种联系,因为它们都与句子的主语“animal”有关。这是通过Self-Attention来实现的。

Self-Attention 的核心是 用文本中的其它词来增强目标词的语义表示,从而更好的利用上下文的信息。self-attention 实际只是 attention 中的一种特殊情况。
2.3.2. 训练细节
训练过程中模型,模型优化的主要是生成查询向量(Q)、键向量(K)和值向量(V)的权重矩阵 Wq、Wκ 和 Wv,而不是具体的 Q、K、V 向量本身。具体来说:
• 输入序列矩阵 X(大小为 n x d)
• 权重矩阵 Wq(大小为 d x dk)
• 权重矩阵 Wk(大小为 d x dk)
• 权重矩阵 Wv(大小为 d x dv)
注:d为单个单词的词向量
生成 Q、K、V 矩阵
通过以下线性变换生成 Q、K、V 矩阵:
• Q=XWq
• K=XWk
• V=XWv
Self-attention可以接收一整个序列的输入,序列中有多少个输入,它就可以得到多少个输出。

要训练出的参数就是 W
2.4. Multi-head Attention
2.4.1. 多头理论细节
上面的self-attention中,每个输入向量乘上Q,K,V矩阵之后分别得到新的矩阵,可以叫做单头自注意力机制。
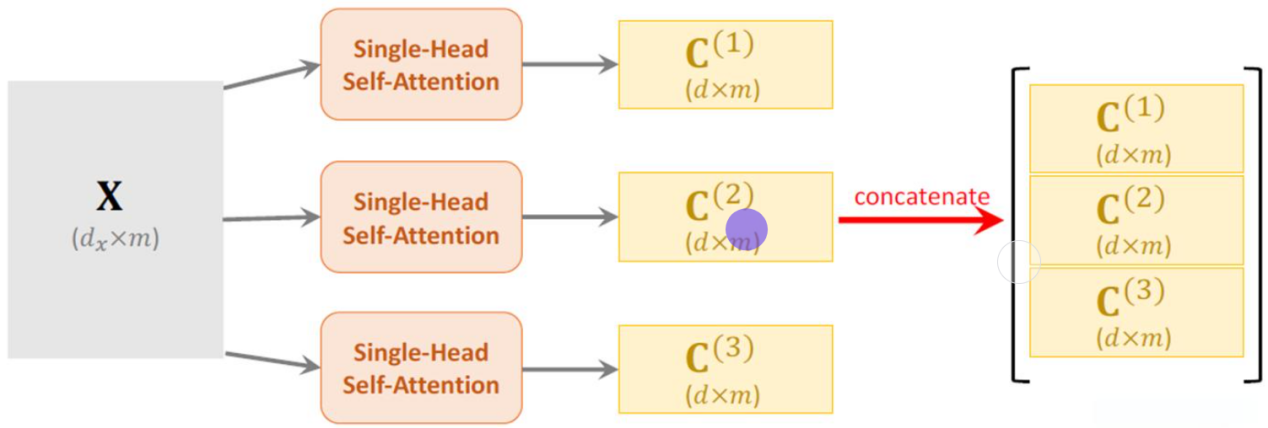
数学表述如下:

将新矩阵拆分成多个小的矩阵就叫做多头注意力矩阵,在隐状态维度的方向将其切分成多个头。在《Attention Is All You Need》这篇原论文原文中解释了多头的作用:将隐状态向量分成多个头,形成多个子语义空间,可以让模型去关注不同维度语义空间的信息(或者说让模型去关注不同方面的信息)。
就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。
2.4.2. 多头代码实现
作者:猛猿
链接:https://www.zhihu.com/question/341222779/answer/2304884017
import numpy as np
import torch
from torch import Tensor
from typing import Optional, Any, Union, Callable
import torch.nn as nn
import torch.nn.functional as F
import math, copy, time
class MultiHeadedAttention(nn.Module):def __init__(self, num_heads: int, d_model: int, dropout: float=0.1):super(MultiHeadedAttention, self).__init__()assert d_model % num_heads == 0, "d_model must be divisible by num_heads"# Assume v_dim always equals k_dimself.k_dim = d_model // num_headsself.num_heads = num_headsself.proj_weights = clones(nn.Linear(d_model, d_model), 4) # W^Q, W^K, W^V, W^Oself.attention_score = Noneself.dropout = nn.Dropout(p=dropout)def forward(self, query:Tensor, key: Tensor, value: Tensor, mask:Optional[Tensor]=None):"""Args:query: shape (batch_size, seq_len, d_model)key: shape (batch_size, seq_len, d_model)value: shape (batch_size, seq_len, d_model)mask: shape (batch_size, seq_len, seq_len). Since we assume all data use a same mask, sohere the shape also equals to (1, seq_len, seq_len)Return:out: shape (batch_size, seq_len, d_model). The output of a multihead attention layer"""if mask is not None:mask = mask.unsqueeze(1)batch_size = query.size(0)# 1) Apply W^Q, W^K, W^V to generate new query, key, valuequery, key, value \= [proj_weight(x).view(batch_size, -1, self.num_heads, self.k_dim).transpose(1, 2)for proj_weight, x in zip(self.proj_weights, [query, key, value])] # -1 equals to seq_len# 2) Calculate attention score and the outout, self.attention_score = attention(query, key, value, mask=mask, dropout=self.dropout)# 3) "Concat" outputout = out.transpose(1, 2).contiguous() \.view(batch_size, -1, self.num_heads * self.k_dim)# 4) Apply W^O to get the final outputout = self.proj_weights[-1](out)return out
def clones(module, N):"Produce N identical layers."return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
def attention(query: Tensor, key: Tensor, value: Tensor, mask: Optional[Tensor] = None, dropout: float = 0.1):"""Define how to calculate attention scoreArgs:query: shape (batch_size, num_heads, seq_len, k_dim)key: shape(batch_size, num_heads, seq_len, k_dim)value: shape(batch_size, num_heads, seq_len, v_dim)mask: shape (batch_size, num_heads, seq_len, seq_len). Since our assumption, here the shape is(1, 1, seq_len, seq_len)Return:out: shape (batch_size, v_dim). Output of an attention head.attention_score: shape (seq_len, seq_len)."""k_dim = query.size(-1)# shape (seq_len ,seq_len),row: token,col: that token's attention scorescores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(k_dim)if mask is not None:scores = scores.masked_fill(mask == 0, -1e10)attention_score = F.softmax(scores, dim = -1)if dropout is not None:attention_score = dropout(attention_score)out = torch.matmul(attention_score, value)return out, attention_score # shape: (seq_len, v_dim), (seq_len, seq_lem)
if __name__ == '__main__':d_model = 8seq_len = 3batch_size = 6num_heads = 2# mask = Nonemask = torch.tril(torch.ones((seq_len, seq_len)), diagonal = 0).unsqueeze(0)input = torch.rand(batch_size, seq_len, d_model)multi_attn = MultiHeadedAttention(num_heads = num_heads, d_model = d_model, dropout = 0.1)out = multi_attn(query = input, key = input, value = input, mask = mask)print(out.shape)2.5. 总结
一句话概括上面几个概念:
Attention就是关注数据的重点,提升权重
Self-Attention 就是关注自身句子中的重点,理解一些多义词。
Multi-head Attention 是将隐状态纬度进行切分处理后进行合并。
3. 讨论观点
整个帖子下面现在有90个回答,下面挑几个赞同比较多的观点,有一些只讲原理没有观点的也不关注了。
地址:https://www.zhihu.com/question/341222779
3.1. 观点1:
作者:香侬科技
链接:https://www.zhihu.com/question/341222779/answer/814111138
Multi-Head 其实不是必须的,去掉一些头效果依然有不错的效果(而且效果下降可能是因为参数量下降),这是因为在头足够的情况下,这些头已经能够有关注位置信息、关注语法信息、关注罕见词 的能力了,再多一些头,无非是一种enhance或noise而已。
3.2. 观点2:
作者:取个好名字真难
链接:https://www.zhihu.com/question/341222779/answer/3476103514
GPT-3 的embedding维数是12288。线性代数告诉我们,当空间维数非常非常大时,向量都非常分散——整个空间太大了,很难得到两个非常靠近的向量。
而attention机制当中,q and k之间的接近性是通过点积得到的。在超高维空间中做点积来获得向量之间的接近性,意义非常小。这样的话,我们就很难得到有意义的attention权重。
分成多个head以后,每个head的embedding维数降低。比如,GPT-3是96头, 这样每个头只有128维。这样利用向量点积计算向量之间的接近性就有效多了。
注:从理论上分析是有意义的,有效果的
3.3. 观点3
作者:qjf42
链接:https://www.zhihu.com/question/341222779/answer/2784844381
这还真不能想当然,今年很多paper讨论multi-head的作用。multi-head对encoder-decoder attention提升不小,但对self-attention目前看提高很有限。NMT任务上heads大于4就没什么提高了。
多个头可以增加并行度和灵活性,但多头也会冗余
1. 多个头有用,但不是所有的头都有用。
一些研究和实验都提到,部分头是冗余的,去掉对效果影响不大(根据不同任务)。类似于特征抽取,不可能每一层都正好可以抽出H个特征,总有重要性排序。
2. 不是所有的头都有很宽的感受野 ,有些只关注附近或特殊位置,所以看上去很像,但并不多余。
3.4. 观点4:
作者:MECH
链接:https://www.zhihu.com/question/341222779/answer/3054459222
在此,笔者可以得到一些对multi-head-attention的结论:
• 对于大部分query,每个头都学习了某种固定的pattern模式,而且12个头中大部分pattern是差不多的,但是总有少数的pattern才能捕捉到语法/句法/词法信息。
• 越靠近底层的attention,其pattern种类越丰富,关注到的点越多,越到顶层的attention,各个head的pattern趋同。
• head数越少,pattern会更倾向于token关注自己本身(或者其他的比较单一的模式,比如都关注CLS)。
• 多头的核心思想应该就是ensemble,如随机森林一样,将特征切分,每个head就像是一个弱分类器,让最后得到的embedding关注多方面信息,不要过拟合到某一种pattern上。
• 已有论文之处head数目不是越多越好,bert-base上实验的结果为8、16最好,太多太少都会变差。
• multi-head-attention中大部分头没有捕捉到语法/句法信息,但是笔者这里没办法做出断言说它们是没有用的,具体还是要看下游任务对其的适配程度。个人倾向于大部分pattern只是不符合人类的语法,在不同的下游任务中应该还是有用武之地的。
3.5. 观点5:
作者:神经美学-茂森
链接:https://www.zhihu.com/question/341222779/answer/3429969267
Multi-head Attention在Transformer中的应用,就像一支高效的团队,每个成员(头)都有自己的专长和关注点,共同合作完成任务。这种机制增强了模型的表达能力,提高了计算效率,并有助于捕捉输入数据的多样性和长距离依赖关系。通过多头注意力的方式,Transformer模型 在各类NLP任务中取得了显著的性能提升。
3.6. 观点6:
作者:Woo Tzins
链接:https://www.zhihu.com/question/341222779/answer/3480120996
第一,Multi-head atten是Transformer这篇paper的重点idea;
第二,google团队当时提出这个方法的时候,是为了能够在多个TPU上并行运算(也可以在GPU上并行),解决RNN在处理长序列时的效率和性能限制,以及无法并行的缺点。
第三,通过关注输入序列的不同位置和不同方面的信息,Multi-head Attention 可以提供更丰富的语义表示,有助于模型更好地捕捉输入序列之间的依赖关系和语义关联。
3.7. 个人观点
上面的大部分的作者都是摆出数据和理论,大部分的结果都是多头机制有用,但是需要控制头的数量,多了和少了都没什么效果。
个人观点是多头机制将隐参数空间进行了拆分,提升了并行度,提高了训练效率,但是将无意义的向量拆分有可能会丧失整个语义的理解,所以需要限量,这中间的平衡需要实验,不可以根据别人的经验。
4. 总结
多头机制是为了能够在多个TPU上并行运算(也可以在GPU上并行),解决RNN在处理长序列时的效率和性能限制,以及无法并行的缺点。
整篇文章从基本的概念到观点的分享,希望能给读者正确的概念,建议去链接下看所有的帖子,有更全面的理解,更建议读者在工作中实践,得出自己的结论。
Attention is All you need !!



















