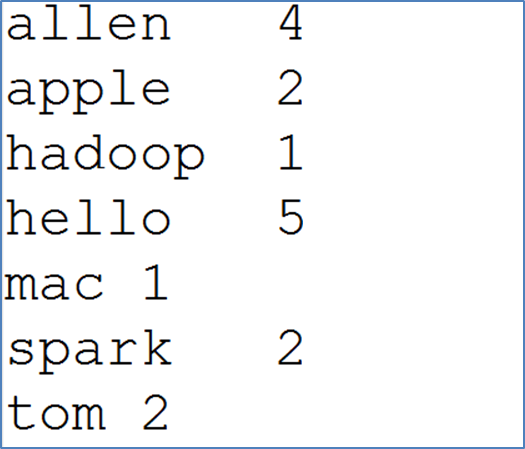
单词出现的总次数
1、WordCount概述
WordCount算是大数据计算领域经典的入门案例,相当于Hello World。
虽然WordCount业务极其简单,但是希望能够通过案例感受背后MapReduce的执行流程和默认的行为机制,这 才是关键。

2、WordCount编程实现思路
map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是<单词,1>。shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的kv对。
lreduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是 单词的总次数。

3、WordCount程序提交
上传课程资料中的文本文件1.txt到HDFS文件系统的/input目录下,如果没有这个目录,使用shell创建
hadoop fs -mkdir /input
hadoop fs -put 1.txt /input
准备好之后,执行官方 MapReduce 实例,对上述 文 件进 行 单词 次 数统计 第一个参数 :wordcount 表示执行 单 词统 计 任务;
第二个参数:指定输入文件的路径;
第三个参数:指定输出结果的路径(该路径不能已存在);
h
[root@node1 mapreduce]# pwd
/export/server/hadoop-3.3.0/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount
/input /output
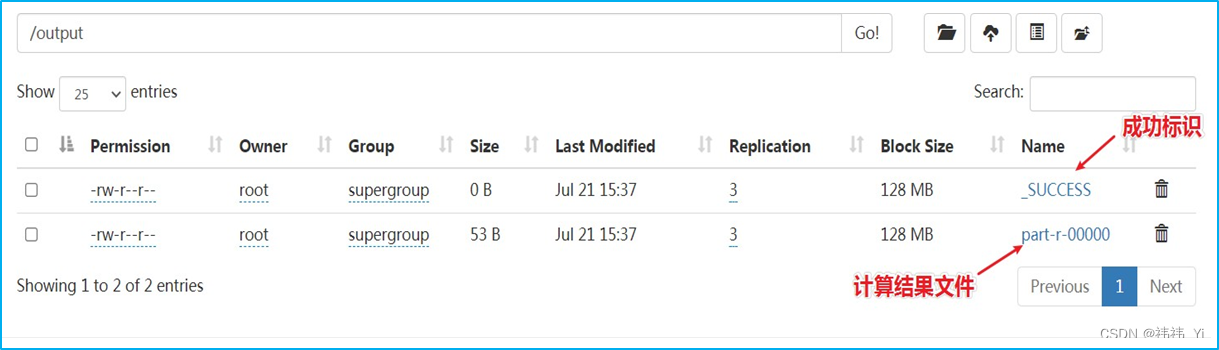
4、WordCount执行结果
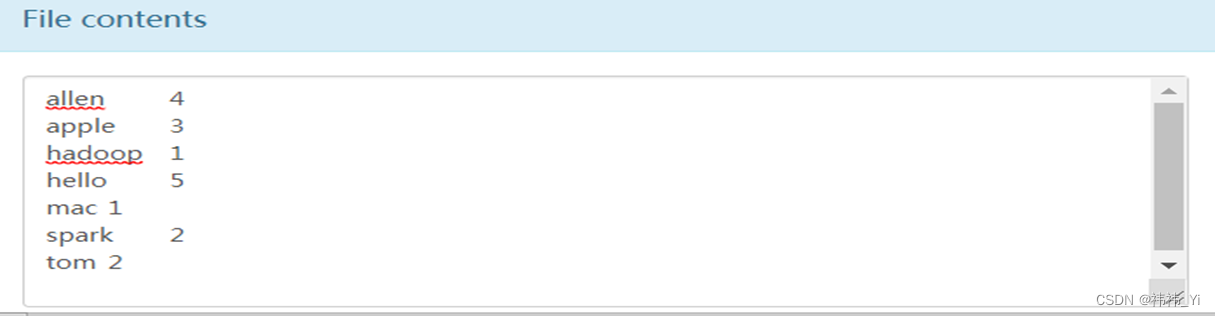

![[云炬python3玩转机器学习] 5-7,8 多元线性回归正规解及其实现](https://img-blog.csdnimg.cn/941dfb450a524488a8da6f8a78d05b50.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA56eR5aSn5LqR54Ks,size_20,color_FFFFFF,t_70,g_se,x_16)