本文章首发于公众号攻城狮客栈,有需要的朋友可文末扫描二维码。
相信大家都使用过迅雷、电驴、百度云网盘等一类的工具,所有这些支持上传或下载的工具都有一个功能,那就是断点续传,也就是在你网络不佳传输断开时,传输会暂停,在网络恢复后,可以继续传输,从而避免数据的重复上传,以减少网络流量,提高效率。那么,你有仔细想过这其中的实现原理嘛?
PS:这两天没更,一是研究了下这个东西,二是偷懒去嗨了
我们之前利用rpc框架thrift做了一个远程通信的项目,具体是实现通过服务器对分布在各地的设备进行统一管理和控制,设备利用4G模块上网,因此,网络状况是影响稳定性的一个重要因素。由于之前客户端向服务器请求的文件较小,这种现象不是很明显,当客户说有需要传输1G左右大小的文件时,我们的系统就不得不做一个类似续传的功能了。
断点续传的原理
断点续传是由服务器给客户端一个已经上传的位置标记position,然后客户端再将文件指针移动到相应的position,通过输入流将文件剩余部分读出来传输给服务器
断点下载是由客户端告诉服务器已经下载的大小,然后服务器会将指针移动到相应的position,继续读出,把文件返回给客户端。 当然为了下载的更快一下,也可以多线程下载,那么基本实现就是给每个线程分配固定的字节的文件,分别去读
下面,我们以断点下载为例来进行详细说明。
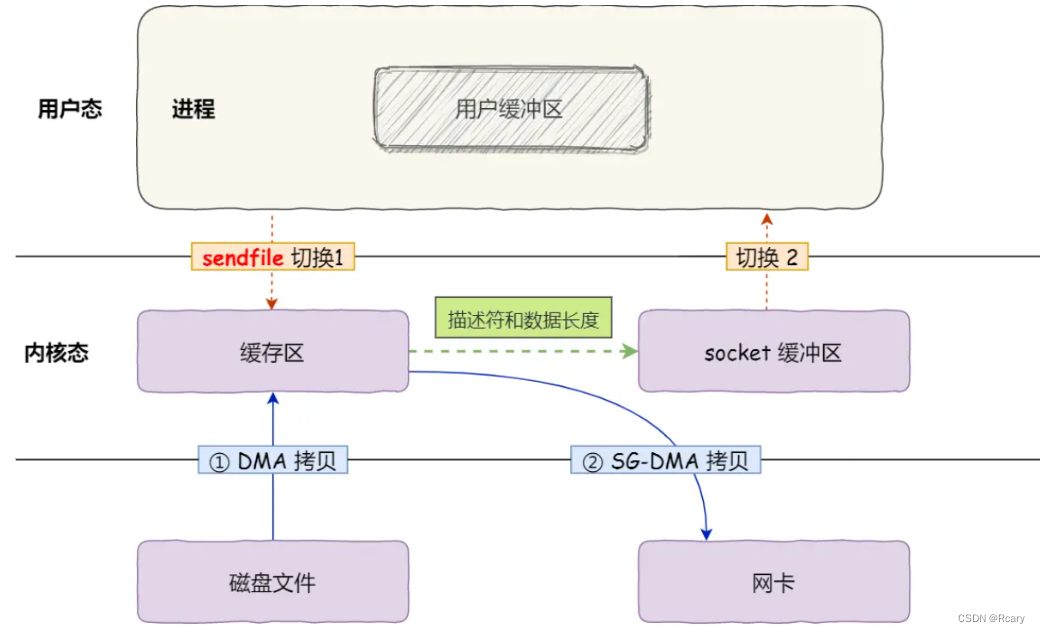
通过上图我们看出,下载过程中,其实是客户端主动带着位置信息向服务端进行请求,主要分为以下几步:
-
准备:客户端获取需要下载的文件的相关信息
-
下载:携带特定请求大小信息进行下载请求
-
存储:对于小文件,可以直接进行存储,对于超大文件,由于内存限制,可以考虑采用存储多个小文件最后合并的方式,具体看业务需求即可。
-
续传:当网络或通信断开时,在程序内部记录响应的已存储大小信息,待网络正常后,继续下载即可;若是需要实现程序重启后续传,记录下载任务到相应的配置文件或数据库中即可。
有了具体的步骤之后,我们就来进行相应的编码设计吧,在编码过程中,对步骤进行相应的完善。
由于项目是利用rpc框架做成的,而且只能是客户端主动去向服务端发请求并获得响应,因此我这里通过一个客户端的C#程序来模拟了rpc通信的过程,以尽量贴合实际情况并使后期容易和项目进行集成,否则,光从设计和代码编写上来看,会觉得有许多无所谓的代码。
界面设计
我设计了一个简单的界面,来增加示例的直观程度,界面很简单,只包含简单的几项,但足以说明问题。
程序设计
代码编写上为了模拟实际情况,定义了一个server类、一个client类,server类只定义了一个获取数据的方法,用来模拟向客户端返回数据,client类包括模拟请求、开始下载以输出文件等方法。另外,在界面上通过定时器来定时刷新页面。
服务端
class Server
{string filePath;StreamReader reader;FileStream fileStream;BinaryReader binaryReader;public Server(string filePath){this.filePath = filePath;reader = new StreamReader(filePath);fileStream = new FileStream(filePath, FileMode.Open,FileAccess.Read);binaryReader = new BinaryReader(fileStream);}public byte[] ReturnFile(int start,int length){int size = fileStream.Length-1 - long.Parse(start.ToString()) >= length ? length : Convert.ToInt32(fileStream.Length-1 - long.Parse(start.ToString()));byte[] b = new byte[size];//FileStream fileStream = new FileStream(filePath, FileMode.Open);//BinaryReader binaryReader = new BinaryReader(fileStream);binaryReader.Read(b, 0, size);return b;}
}
客户端
我们主要来分析一下客户端。
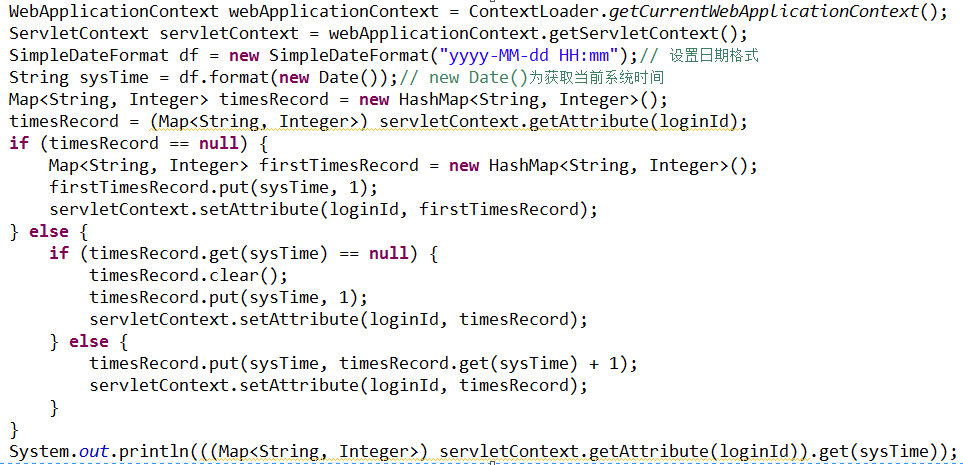
客户端在下载时,需要知晓对应的文件、文件大小信息等,而且为了续传还需要知道已下载部分的大小,另外,由于文件可能过大,所以除了定义每次请求的大小外,还需要定义每个小文件的大小,这2个配置最好是写在配置文件里,虽然我这里并没有这样做。为了避免频繁的io,我们在达到一个小文件大小时进行一次写入操作,因此,在这之前的数据都只能暂时存在内存中,因此还需要定义一个数据块的集合,如下,就是上述列出的一部分属性和字段定义。
public string FilePath { get; set; }
public string FileName { get; set; }
public int TotalSize { get; set; }
public int DownloadSize { get; set; }
public int StartPosition { get; set; } = 0;private int blockLength = 1024*1024;//1M每个块大小
private int blockCount = 10;//每个小文件的大小List<byte[]> datas = new List<byte[]>();说完了定义,我们来看一下方法,首先,是我们的下载方法,在未下载完成以及未断开时,应一直处于下载状态,下载过程中,包括数据请求,数据拼接,数据写入以及状态更新等。
public void DownloadFile()
{isPause = !isPause;while (!isComplete&&!isPause){byte[] b = GetBlock();datas.Add(b);DownloadSize += b.Length;if (DownloadSize== TotalSize){isComplete = true;}if (datas.Count == blockCount|| isComplete){w2f();}StartPosition= DownloadSize-1;if (isComplete){//isComplete = true;//w2f();//StartPosition = 0;break;}}if (isComplete){StartPosition = 0;}
}private void w2f()
{fileNum++;//byte[] bt = new byte[blockLength * datas.Count];byte[] bt = new byte[datas.Sum(o => o.Length)] ;datas.ForEach(o => bt.CopyTo(o, 0));//string name = FileName + fileNum;//File.WriteAllBytes(name, bt);//FileStream fileStream = new FileStream(name, FileMode.Append, FileAccess.Write);fileStream.Write(bt, 0, bt.Length);fileStream.Flush();datas.Clear();
}上面的w2f方法,大家可以看到,我并不是按照小文件合并的方式来实现的,但注释部分已经实现了该操作,只是有没实现合并,但原理和这里是相同的。
界面部分
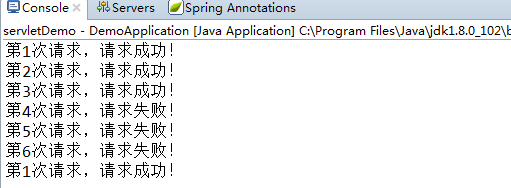
界面部分,主要是通过定时器来刷新界面,以得知当前的下载情况,可以做一个下载进度的功能。另外,可以通过暂停来模拟断开并再次点击模拟恢复的情况。
public Form1()
{InitializeComponent();btn_Pause.Enabled = false;timer = new System.Windows.Forms.Timer();timer.Tick += Timer_Tick;timer.Interval = 2000;
}private void Timer_Tick(object sender, EventArgs e)
{lb_download.Invoke(new Action(() => { lb_download.Text = client.DownloadSize.ToString()+" kb"; }));double process = client.DownloadSize / fileSize * 100;lb_download.Invoke(new Action(() => { lb_process.Text = process.ToString() + " %"; }));
}到这里的话,基本上功能就已经实现的差不多了,但仍然有需要完善的地方,比如,文件下载完成后,按道理肯定是需要做一个校验以确保文件正确性的,而且,像迅雷这种软件,在下载时,需要用到种子,其实他里边就存储有校验相关的信息,而且不只是校验整个文件,他会对每个小块都进行校验,如果不匹配就进行相应操作。具体的实现的话,其实也很简单,就是客户端拿到要下载的文件时,把相应的校验消息也拿到,等下载完成后进行匹配即可。
我这里因为使用了rpc框架,框架自身带有对异常的处理机制,因此,在整体上看,只要下载的文件大小最终是匹配的,那出现错误的概率还是很小的,另外,在实际的项目中,已自主实现了心跳以及重连的功能,因此可以在重连后调用续传的方法即可。
最后,还要说的一点是,网页版的实现原理也是这样,但是实现方式不同,http协议头里可以添加请求相关的信息,因此可通过构建http头的方式来向服务端发送请求实现类似的功能,并且,现在很多主流的前端框架都支持文件的分块上传,极大的便利了该功能的实现,有兴趣的同学可以自己研究一下。
本章源码可访问
https://github.com/IronMarmot/Samples/tree/master/BreakpointResumeDemo
更多精彩内容,请微信搜索攻城狮客栈 或扫描下方二维码
------------------------------------------------------------------------------
公众号:攻城狮客栈
CSDN:画鸡蛋的不止达芬奇

让我们一起变的更优秀。