贝壳找房作为领先的居住服务综合平台,一直在推进居住产业的数字化与智能化升级。该平台通过汇聚并赋能优质的服务者,旨在为中国广大家庭带来涵盖二手房买卖、新房交易、房屋租赁、家装、家居以及家庭服务等全方位、高质量且高效的居住服务体验。
在贝壳找房的指标体系中,由于大量指标需要在实施场景精确去重,因此,需要构建实时字典服务,而实时字典服务对存储要求极高,需要存储服务能支持每秒十万级以上数据量的读写、支持数据持久化和保障数据的唯一性。结合现有存储系统及需求的场景特点,贝壳在2个测试对象即HBase 和 OceanBase中选择了后者,在上线OceanBase后,贝壳获得了更高的查询性能和稳定性,更低的硬件成本和运维成本。
解决精确去重计数痛点,贝壳构建实时字典服务
在数据分析领域,精确去重计数(Count Distinct)是一种常见的需求。在贝壳找房的指标体系中,大量指标的计算都需要精确去重计数的支撑,比如带看量、委托量、DAU、MAU等等。对OLAP引擎来说,精确去重计数支持是一项基础的能力。
传统精确去重计数实现方式是基于原始数据进行计算,保留了明细,使用灵活,适用于支持明细需求,但是其在查询过程中需要多次进行数据Shuffle,在数据量大(高基数)时资源消耗大,性能难以保障。为了解决这个问题,在大数据领域普遍都会采用近似计算方法(如 HyperLogLog、Count-Min Sketch 等),这些技术可以较大程度上减少计算开销,但同时也会对计数结果引入一定的近似误差,无法支持精确去重计算。另外一种常用的方法是基于位图(Bitmap)实现精确去重计数,其思路是将明细数据的值对应到一个bit位上,元素存在则该bit值为1,不存在则为0,在精确去重计数时,只需统计Bitmap中1的个数即可。但是,基于 Bitmap 精确去重计数方法也有一定限制,即要求去重字段类型为整数型类型。如果需要支持对其他数据类型的字段采用Bitmap进行精确去重计数,就需要构建全局字典,将其他类型数据(如字符串类型)通过全局字典映射成为整数类型,即字典编码+Bitmap。
为了支持实时场景下,对非整型数据的快速精确去重计数,需要构建实时字典服务,支持在Flink任务中利用实时字典服务,将非整型数据转换为唯一整型编码,存储到下游OLAP引擎(例如StarRocks等),然后利用OLAP引擎本身支持对整型数据进行Bitmap精确去重计数特性来实现快速的精确去重计数。
简言之,实时字典服务的目的是将实时数据流中的非整型数据映射为整型数据,主要功能如下:
- 通过接收调用方传递的非整型数据(key),返回对应的整型数据(key:value)。
- 相同的key永远返回相同的value,不同的key永远返回不同的value,即要保证数据的持久化和唯一性。
因为是在实时数据流中使用,所以实时字典服务必须做到低延迟,能快速响应调用请求。
实时字典服务在整个数据处理流程中的角色如下图所示,在实时ETL过程中,调用字典服务,传入原始数据,返回原始数据对应的字典值,完成替换后写入OLAP引擎。
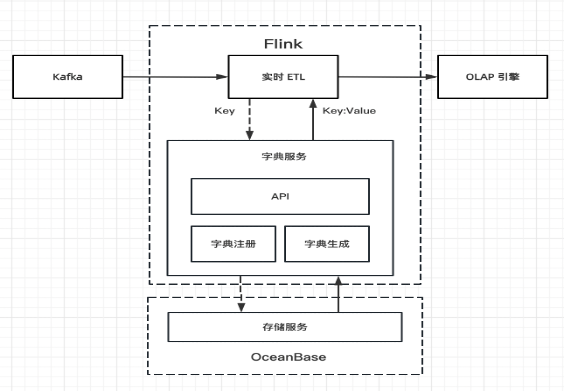
字典服务包括两层:计算层和存储层。计算层负责字典注册、数据查询和处理,与调用方和存储层进行交互。存储层提供字典数据的存储和查询服务。
1. 计算层
计算层包括字典注册和字典生成两部分。
注册字典:对于需要将字符串转换为整型数值的字段,需要进行字典注册,一个字段对应存储服务中的一个字典表。字典数据的存储和查询将以此表为基础。
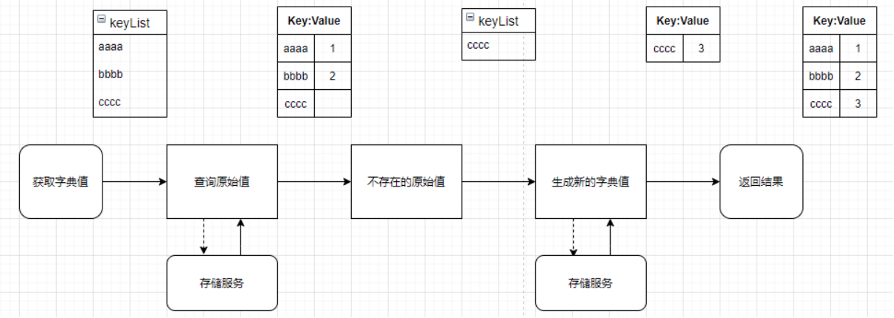
字典生成:调用方通过字典id和原始值列表获取原始值列表的字典值。查询流程如下图,包括三个步骤:1)根据原始值列表查询字典表,拿到结果数据;2)对结果中不存在的原始值,生成新的字典值;3)返回1和2的结果。
2. 存储层
存储层负责字典数据的存储和查询,是字典服务实现的基础。必须有足够高的可靠性来保证数据的不丢失、不重复,每秒处理十万级数据量以上的读写性能来保证服务调用的低延迟,所以选择合适的存储服务十分重要。
实时字典存储服务选型:保证数据不丢不重
要满足实时字典服务的存储需求,存储服务需要能支持每秒十万级以上数据量的读写、支持数据持久化和保障数据的唯一性。最重要的是数据持久化和数据唯一性,既不能丢数据,也不允许数据重复(同一个key对应多个value,多个key对应同一个value)。根据公司现有存储系统及需求的场景特点,本次选型选择了2个测试对象:HBase和OceanBase。
1.环境准备
OceanBase和HBase测试集群均采用3台Dell EMC PowerEdge R640服务器节点组成,节点配置规格为:48C/128G/1.5T Nvme SSD,所有的测试任务均运行在同一个Hadoop 实时集群。HBase版本为1.4.9,HBase集群由HBase DBA协助部署和配置,OceanBase版本为3.1.2,使用默认配置。
2.测试数据
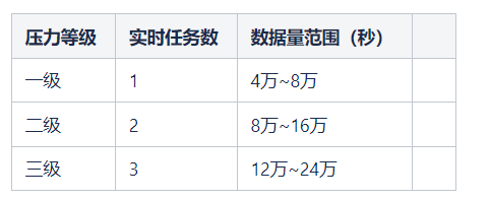
测试过程是通过spark streaming实时任务消费topic(starrocks-prometheus-metrics),借助该topic的数据量(每秒4万~8万之间),对每条数据生成uuid,最后批量调用字典服务生成字典,batchDuration设置为1秒。通过增加实时任务的个数提高数据量来加大底层存储的压力,通过观察实时任务的延迟指标来判断存储服务的吞吐能力。
压力测试分为如下三个等级,不同等级测试时间持续10分钟。
3、测试过程与结果分析
1)HBase测试
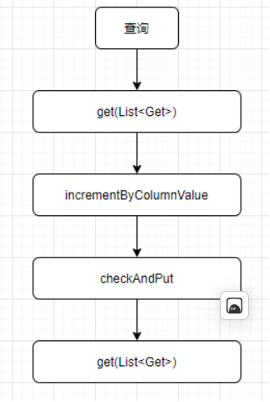
HBase本身是持久化的,可以保证数据不丢失;支持批量查询(get(List<Get>));通过唯一自增(incrementColumnValue)可以保证value不重复;通过事务写(checkAndPut)可以保证key不重复。
HBase可以独立满足字典服务的数据处理流程:
-
- 首先通过调用get(List<Get>)接口批量查询字典表。
- 对于字典表中不存在的数据,调用incrementColumnValue接口,批量生成唯一自增id,保证字典值不重复。
- 通过事务写checkAndPut将key:value数据写入字典表,写入成功表示字典值生成成功,写入失败表示原始值已存在字典值,保证相同的key不会写入两次。
- 使用上一步写入失败的数据,再一次调用get(List<Get>)接口查询字典值。
为了提高数据的读写性能,对字典表进行region预分区,将数据分散到不同的region server,本次测试使用了HBase DBA推荐的HexStringSplit分区方式,数据在不同region server分布得比较均匀。批量读写大小的设置是根据不同大小的响应时间选择的较优的一个值,其中,批量读大小:100,批量写大小:100。
批量读写测试数据如下:
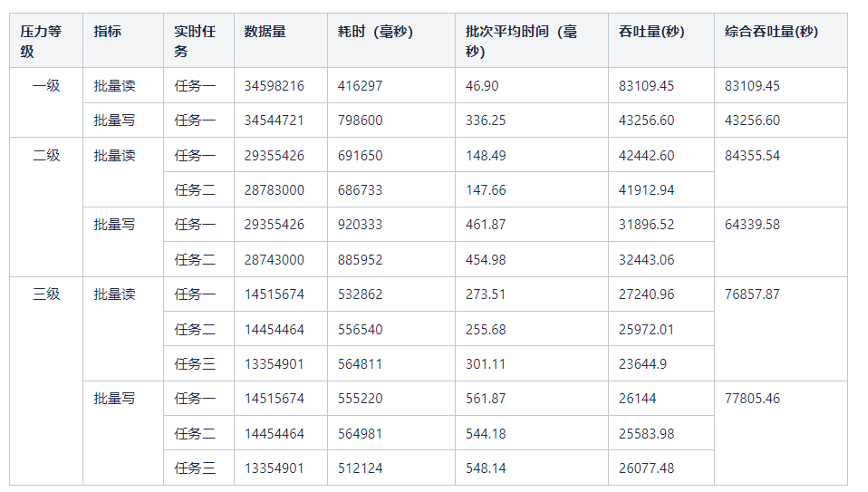
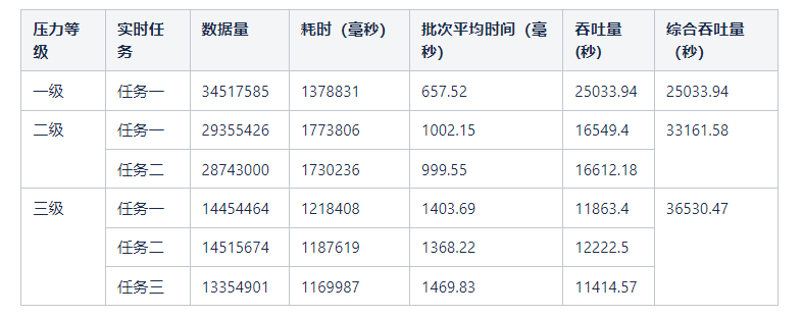
完整流程测试数据如下:
2)OceanBase测试
OceanBase以表的形式存储字典数据,把key作为主键来保证数据不重复,把value设为自增来保证数据唯一,建表语句如下:
CREATE TABLE `t_olap_realtime_cd_measure_duid_dict` (`dict_key` VARCHAR(256) NOT NULL,`dict_val` BIGINT(20) NOT NULL AUTO_INCREMENT,PRIMARY KEY (`dict_key`)
) DEFAULT CHARSET = utf8mb4 PARTITION BY KEY(dict_key) PARTITIONS 10
跟HBase相比,这种方式简化了数据处理流程,只需要写SQL即可完成:
-
- 查询已存在的字典值:select dict_key,dict_value from t_olap_realtime_cd_measure_duid_dict where dict_key in (...)
- 对于上一步结果中不存在的dict_key插入数据库:insert ingore into t_olap_realtime_cd_measure_duid_dict (dict_key) values (...)
- 对于上一步插入的数据再一次查询数据库:select dict_key,dict_value from t_olap_realtime_cd_measure_duid_dict where dict_key in (...)
使用OceanBase,不需要在代码层面关注key重复和value的唯一自增,都由数据库本身的特性来实现,不仅简化了处理流程,相比单条数据写入,批量写入也更加高效。OceanBase批读写大小分别为:批量读500,批量写:500。
批量读写测试数据如下:
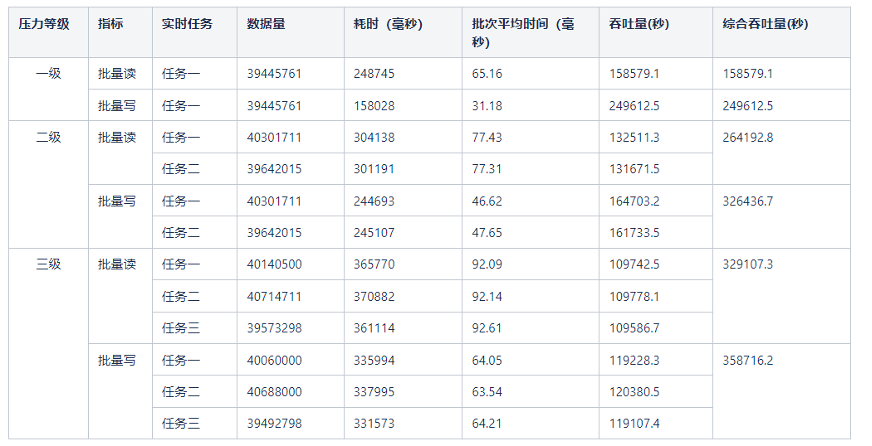
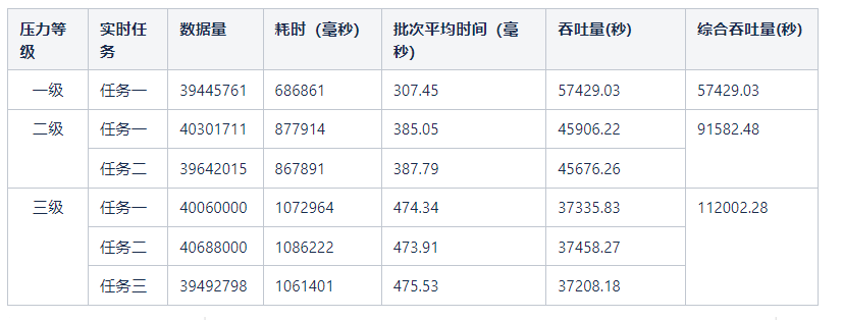
完整流程测试数据如下:
3) 测试数据分析比较
首先,对比批量读吞吐(单位:条/秒)。
| 压力 | HBase | OceanBase |
| 一级 | 83109.45 | 158579.1 |
| 二级 | 84355.54 | 264192.8 |
| 三级 | 76857.87 | 329107.3 |
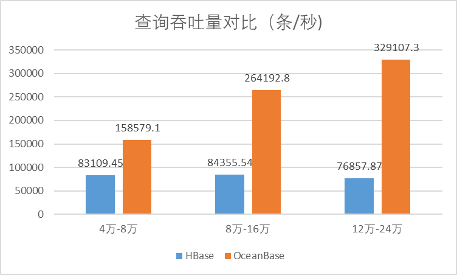
根据各存储系统的不同特点,设置了不同的批量查询大小,HBase:100,OceanBase:500。从上图可见,测试压力从一级到三级(数据量在4万到24万之间),OceanBase的查询吞吐量明显比HBase高。
其次,对比批量写吞吐(单位:条/秒)。
| 压力 | HBase | OceanBase |
| 一级 | 43256.6 | 249612.5 |
| 二级 | 64339.58 | 326436.7 |
| 三级 | 77805.46 | 358716.2 |
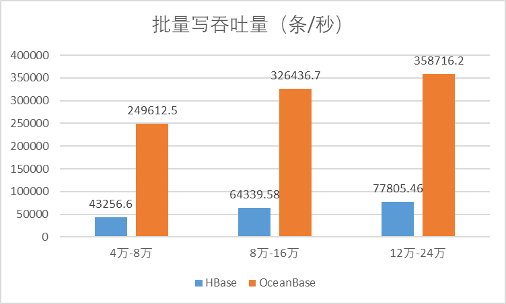
因为要保证key不重复,HBase需要使用checkAndPut方法进行单次单条数据写入,而OceanBase把key作为主键保证数据不重复,可以单次批量数据写入,每次500条,所以OceanBase的批量写吞吐量比HBase高很多。
再来对比完整流程平均时间(单位:毫秒)。
| 压力 | HBase | OceanBase |
| 一级 | 657.52 | 307.45 |
| 二级 | 1000.85 | 386.42 |
| 三级 | 1279.63 | 474.59 |
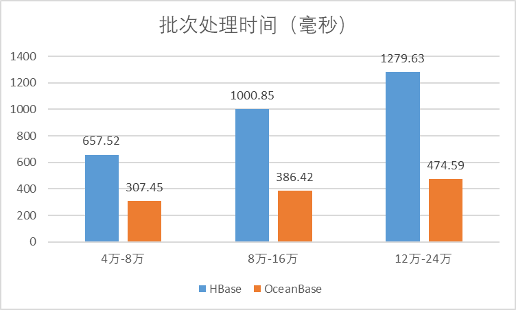
从对比数据可知:
- 在一个完整的数据处理流程时间开销上,OceanBase最低,不到其他两个的50%。
- 在一个实时任务(4万~8万数据量)的情况下,HBase、OceanBase都能在1秒内完成。
- 在两个实时任务(8万~16万数据量)的情况下,HBase的处理时间都超过了1秒。但是,因为数据量并不均匀,HBase也没有呈现出明显的延迟。
- 在三个实时任务(12万~24万数据量)的情况下,HBase的平均时间升高到了1.27秒,实时任务的延迟也越来越大。
- 随着压力不断增大,只有OceanBase能持续在0.5秒内完成数据处理流程。
最后,对比平均吞吐量(单位:条/秒)。
| 压力 | HBase | OceanBase |
| 一级 | 25033.94 | 57429.03 |
| 二级 | 33161.58 | 91582.48 |
| 三级 | 35500.47 | 112002.3 |
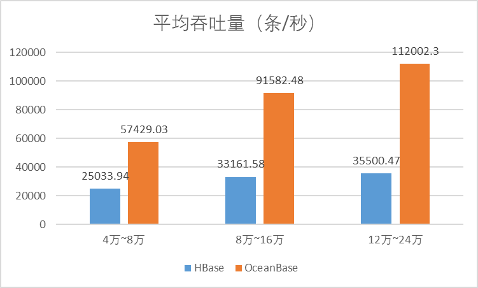
在数据吞吐量上,OceanBase是HBase的2~3倍,并且随着数据量的不断增加,优势越来越大。
不同数据量压测,OceanBase 与HBase表现对比总结
字典服务存储的数据特征是前期读多写多,随着字典数据的不断沉淀,已存在的字典越来越多,后期就是读多写少。本次测试使用的是随机生成的uuid数据,所以整个数据处理流程一直都是全读全写,对存储系统来说,比线上真实环境压力更大。
本次测试的数据量范围是在4万~8万、8万~16万、12万~24万之间波动,通过不断提高实时任务的个数给底层存储系统施加压力,通过观察实时任务的延迟情况来衡量存储系统的处理能力。
-
- 在4万~8万数据量情况下,HBase和OceanBase均能在1秒内完成数据处理,不会产生延迟。所以,在4万~8万数据量场景下,HBase和OceanBase都能满足需求。
- 在8万~16万数据量情况下,HBase在1秒左右完成数据处理,不会产生明显延迟。所以,在8万~16万场景下,HBase和OceanBase都能满足需求。
- 在12万~24万数据量情况下,HBase的处理时间是1.27秒,随着时间积累,延迟也越来越大。所以,在12万~24万场景下,只有OceanBase能满足需求。
- 在测试过程中,OceanBase是在数据量28万~56万,且加到了7个实时任务的情况下,才开始出现延迟,数据处理时间1.1秒。
另外,根据测试统计数据,在批量读、批量写、吞吐量上,OceanBase都有明显优势。HBase要保证key不重复和value自增,只能通过单条数据写入,写数据成为了整个数据流程的瓶颈。通过数据库本身的特性,使用OceanBase时不需要关注key重复和value自增的问题,通过SQL批量写入数据,从而能提供更大的写吞吐。
综上,从数据处理能力、资源使用情况和数据处理流程复杂度上,贝壳最后选择OceanBase作为实时字典服务的存储系统。在使用过程中,OceanBase实现了更高的查询性能和稳定性,更低的硬件成本和运维成本,以及更简单的部署。贝壳后续也将在更多合适的场景中推广、应用OceanBase。
OceanBase 云数据库现已支持免费试用,现在申请,体验分布式数据库带来全新体验吧 ~