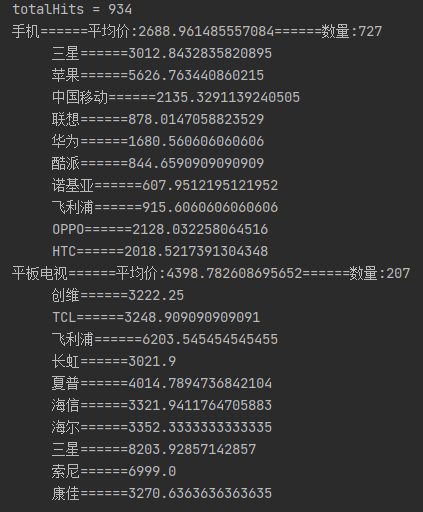
深层循环网络
就是更深了,因为之前的网络都只有一层隐藏层,弄多一点

我们将多层循环神经网络堆叠在一起,通过对几个简单层的组合,产生了一个灵活的机制。上图展示了一个具有 L L L个隐藏层的深度循环神经网络,每个隐状态都连续地传递到当前层的下一个时间步和下一层的当前步。
1.函数依赖关系
假设在时间步 t t t有一个小批量的输入数据 X t ∈ R n × d X_t\in \R^{n\times d} Xt∈Rn×d(样本数:n,每个样本中的输入数:d),同时,将第 l l l个隐藏层( l = 1 , ⋯ , L l=1,\cdots,L l=1,⋯,L)的隐状态设为KaTeX parse error: Expected group as argument to '\H' at position 3: \H_̲t^{(l)}\in \R^{…(隐藏单元数:h),输出层变量设为 O t ∈ R n × q O_t\in \R^{n\times q} Ot∈Rn×q(输出数: q q q),设置 H t ( 0 ) = X t H^{(0)}_t = X_t Ht(0)=Xt,第 l l l个隐藏层的隐状态使用激活函数 ϕ t \phi_t ϕt,则:
H t ( l ) = ϕ ( H t ( l − 1 ) W x h ( l ) + H t − 1 ( l ) W h h ( l ) + b h ( l ) ) H_t^{(l)}=\phi(H_t^{(l-1)}W_{xh}^{(l)}+H_{t-1}^{(l)}W_{hh}^{(l)}+b_h^{(l)}) Ht(l)=ϕ(Ht(l−1)Wxh(l)+Ht−1(l)Whh(l)+bh(l))
其中权重 W x h ∈ R h × q , W h h ( l ) ∈ R h × h W_{xh}\in \R^{h\times q},W_{hh}^{(l)}\in R^{h\times h} Wxh∈Rh×q,Whh(l)∈Rh×h和偏置 b h ∈ R 1 × h b_h\in \R ^{1\times h} bh∈R1×h都是第l个隐藏层的模型参数。
最后,输出层的计算仅基于第 l l l个隐藏层的最终的隐状态:
O t = H t ( L ) W h q + b q O_t = H_t^{(L)} W_{hq} +b_q Ot=Ht(L)Whq+bq
其中,权重 W h q ∈ R h × q W_{hq}\in \R ^{h\times q} Whq∈Rh×q和偏置 b q ∈ R 1 × q b_q \in \R ^{1\times q} bq∈R1×q都是输出层的模型参数
使用多个隐藏层来获得更多的非线性性。
2.代码实现
import torch
from torch import nn
from d2l import torch as d2lbatch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
device = d2l.try_gpu()
# num_layers 的值来设定隐藏层数
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)num_epochs, lr = 500, 2
d2l.train_ch8(model, train_iter, vocab, lr*1.0, num_epochs, device)




![[安洵杯 2019]easy_serialize_php](https://img-blog.csdnimg.cn/img_convert/2c30f87c6d81f25b70e3a3640a8ed52e.png)