向量搜索并非轻而易举!
向量搜索,也称为向量相似性搜索或最近邻搜索,是一种常见于 RAG 应用和信息检索系统中的数据检索技术,用于查找与给定查询向量相似或密切相关的数据。业内通常会宣传该技术在处理大型数据集时非常直观且简单易用。一般来说,您只需将数据输入到 Embedding 模型中生成 Embedding 向量,然后将这些向量存储到向量数据库中即可检索到所需的结果。
许多向量数据库厂商通常会使用“简单”、“用户友好”和“易用”等词汇来描述向量数据库的能力。这些厂商还会宣传“只需几行代码就能获取显著的成果,绕过机器学习、人工智能、ETL 过程或系统调优等复杂步骤”。
这些宣传本身并无任何问题——向量搜索就像使用基本的数值库(如 NumPy)一样轻松。以下示例的 Python 代码只有十行左右,使用 KNN 算法,实现了向量搜索。对于数据规模在一千到一万个向量的小型应用而言,这种简单的方法既有效又准确。
import numpy as np# Function to calculate Euclidean distance
def euclidean_distance(a, b):return np.linalg.norm(a - b)# Function to perform KNN
def knn(data, target, k):# Calculate distances between target and all points in datadistances = [euclidean_distance(d, target) for d in data]# Combine distances with data indicesdistances = np.array(list(zip(distances, range(len(data)))))# Sort by distancesorted_distances = distances[distances[:, 0].argsort()]# Get the top k closest indicesclosest_k_indices = sorted_distances[:k, 1].astype(int)# Return the top k closest vectorsreturn data[closest_k_indices]然而,当数据集规模增长到超过一百万或一千万个向量时,这种方法将不再奏效。这是因为现实世界的应用更加复杂。构建一个可扩展的应用不仅仅要考虑编码,更需要全面考虑各种因素,包括搜索质量、可扩展性、可用性、多租户、成本、安全性等问题!
所以,让我们记住这一点:生产环境中的向量搜索往往很复杂。那么,在生产环境中搭建一个向量搜索应用的过程中是否有一些最佳实践呢?
为了帮助您应对挑战,我们将分享 3 个在 RAG 应用生产环境中有效部署向量数据库的关键技巧:
-
设计一个有效的 Schema:仔细考虑数据结构及其查询方式,创建一个可优化性能和提供可扩展性的 Schema。
-
考虑可扩展性:考虑未来的数据规模增长,并充分设计架构以适应不断增长的数据量和用户流量。
-
选择最佳索引并优化性能:根据用例选择最合适的索引方法,并持续监控和调整性能。
通过遵循这些最佳实践,您能构建一个强大且高效的向量搜索应用。欢迎在评论区分享您的经验和技巧!
设计一个有效的 Schema
Schema 定义了数据库的结构,包括表、字段、关系和数据类型。这个有组织的框架确保数据以一致和可预测的方式存储,从而简化了数据管理、查询和维护的流程。选择合适的 Schema 对于像 Milvus 这样的向量数据库尤为重要,因为 Milvus 可以处理向量和各种结构化数据类型,包括元数据和标量数据。这些数据可以增强过滤搜索并改善整体搜索结果。本节将探讨选择最有效的 Schema 时需要考虑的关键因素。
动态 Schema vs. 固定 Schema
在数据库系统中,动态 Schema 和固定 Schema 代表了两种主要的数据结构方法。动态 Schema 提供了灵活性,简化了数据插入和检索流程,无需进行大量的数据对齐或 ETL 过程。这种方法非常适合需要更改数据结构的应用。另一方面,固定 Schema 也十分重要,因为它们有着紧凑的存储格式,在性能效率和节约内存方面表现出色。
混合 Schema 的方法可以为开发高效的向量数据库应用的开发人员带来好处。这种方法结合了固定 Schema 在关键数据链路上的稳健性和动态 Schema 在适应多样化用例方面的灵活性。例如,在推荐系统中,产品名称和产品 ID 等元素的重要性可能会因应用需求而有所差异。通过采用混合 Schema,开发人员可以在确保最佳性能的同时适应不断变化的数据需求。
设置主键和 Partition key
主键和分区键是向量数据库中的两个重要概念。以 Milvus 向量数据库为例,我们将深入探讨主键和 Partition key 在向量数据库中的功能。
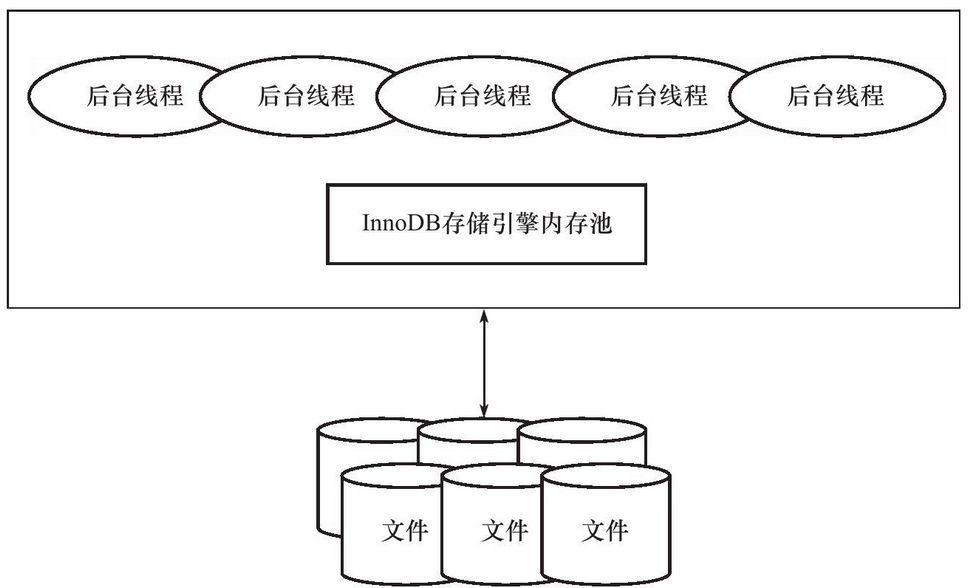
Milvus 架构将数据分为几个部分:有固定和动态字段(统称为 payload),一个必需的向量字段,以及类似于传统关系数据库中的时间戳和全局唯一标识符(UUID)等系统字段。
-
主键:在 Milvus 中,主键通常作为唯一标识符,在 RAG 用例中可能会将 chunk ID 作为主键。主键会被频繁访问,可以开启自动生成(Auto ID)。主键在快速定位和检索数据库中的特定数据方面起着重要作用。
-
Partition key:在 Milvus 中创建 Collection 时,可以指定 Partition key。这个键允许 Milvus 根据键值将数据 Entity 存储在不同的 Partition 中,有效将数据组织成可管理的 Segment。一个简单理解 Partition key 的方法是,如果有一些数据集你想要过滤,可以考虑使用 Partition key。例如,在多租情况下,数据隔离和高效分布是必要的,因此将它们存储在不同的 Partition 中可以有效实现这一点。 Partition key 对于可扩展性也很有用,因为通过哈希将数据分区成 Shard,使数据库能够更高效地管理大规模用户群和多租户。
主键和 Partition key 在维护向量数据库的结构完整性和操作效率方面至关重要,在处理大量数据集和确保数据快速访问和检索方面不可或缺。
选择 Embedding 向量类型
为 RAG 应用选择 Embedding 向量类型时,需要选择合适的 ML 模型来生成向量。向量类型主要包含以下几种:
-
稠密向量 (Dense Embedding)是向量数据库应用中用于语义相似性搜索最常见的向量类型,以其稳健性和在各种数据类型中的广泛适用性而闻名。流行的稠密向量 Embedding 模型包括 OpenAI、BGE 和 Cohere。
-
稀疏向量(Sparse Embedding)因其在搜索领域外数据(out-of-domain data)时的效率而越来越受欢迎。Splade 和 BGE M3 等模型增强了稀疏向量在异构搜索中的实用性,使其成为适合多样化、多功能应用的向量类型。
-
二进制向量(Binary Embedding)以其二进制格式(零和一)为特征,专为高效存储设计,非常适合蛋白质测序等特殊用例。像 Meta ESM-2 这样的模型通常用于生成这些 Embedding 向量,为特定的搜索需求提供有针对性的解决方案。
为确保 RAG 应用搜索结果的准确性,我们需要使用的不仅仅是稠密向量。因此,我们需要找到支持不同索引算法的解决方案,以高效地搜索不同类型的 Embedding 向量。Milvus 支持各种索引来管理稠密、稀疏、二进制,甚至是稀疏和稠密混合的 Embedding 向量,从而实现跨各种数据维度的高效搜索,并确保向量数据库应用的最佳性能。
实战教程:如何设计 Schema
现在,让我们整合刚才学习到的内容,设计一个有效的 Schema,从而提高搜索结果的准确性。
| 字段名称 | 字段数据类型 | 描述 | 示例值 |
| chunkID | Int64 | 主键。主键值全局唯一。 | 123456789 |
| userID | Int64 | Partition key。根据用户 ID (userID)将数据分区,确保搜索仅限制在同一个用户 ID 的数据分区中。 | 987654321 |
| docID | Int64 | 文档的特殊标识符,用于将同一篇文档的不同 Chunk 联系起来。 | 555666777 |
| chunkData | varchar | 文档中的一部分,包含几百个字节的文本。 | "This is a part of the document..." |
| dynamicParams | JSON | 存储文档的动态参数,例如文档名称、来源 URL 等。 | {"name": "Example Document", "source": "example.com"} |
| sparseVector | 特殊格式 | 表示稀疏向量的数据。仅在某些位置具有非零值以表示稀疏性。 | [0.1, 0, 0, 0.8, 0.4] |
| denseVector | 特殊格式 | 表示稠密向量的数据。具有固定数量的值。 | [0.2, 0.3, 0.4, 0.1] |
上述 Schema 中除了主键和向量字段之外,还存在其他的字段。这些字段在构建和使用向量数据库时起着重要作用。
基础部分:基础部分包括主键(chunkID)和 Embedding 向量(denseVector),这是数据库中每个 Entity 必备的字段。
多租支持:我们添加了一个字段 userID,用于按租户对数据进行分区。这能帮助我们实现按用户隔离和管理数据访问,增强了数据安全性。
优化搜索结果:我们添加了几个其他字段来进行优化,包括:
-
docID:该字段表示 chunk 的来源,并可以基于这个字段利用 Milvus 的分组搜索(grouping search)功能。在示例中,我们将文档切分为 chunk,并将 Embedding 向量存储在 denseVector 字段中,而在docID这个字段中,我们存储了相关的文档信息。您可以在search()操作中加入group_by_field参数,按文档 ID 对结果进行分组,从而找到相关的文档,而不是相似的段落或 chunk。 -
dynamicParams:该字段可以用于过滤,帮助您管理和检索符合需求的数据。改字段可以包含很多元数据,例如文档名称、来源 URL 等。我们将字段设置为 json 类型,并在一个字段中存储多个键值对。 -
sparseVector:该字段保存 chunk 的稀疏向量,让我们能够执行 ANN 搜索并根据相关的标量值检索结果。
上图中,我们发现还可以从单独的查询中收集结果,然后重新排序以优化搜索结果。
通过上述示例,我们设计了一个高效的 Schema,接着就可以创建一个更强大且灵活的向量数据库以满足 RAG 应用需求了。这个 Schema 能帮助我们充分利用向量搜索的优势,同时结合传统的数据管理和检索技术。
考虑扩展性
一旦 RAG 应用的 MVP 能够跑通,您就该开始为生产部署做准备了。这一过程需要我们预测未来的数据增长,并合理设计架构从而适应这些不断增加的数据量和用户流量。
为了确保应用能够有效扩展,需要注意的是,由于数据存储在一个大型的 Collection 索引中,这种方式可能导致两个主要问题——索引速度变慢和由于频繁更新数据导致的索引质量下降。这些问题最终会降低搜索质量。
Milvus 可以通过将整个数据集划分为可管理的 Segment 来应对扩展性的挑战,可以在 Segment 变得不稳定时执行延迟更新或压缩 Segment,从而保持始终出色的搜索质量。这种分段有助于负载均衡,帮助我们将查询均匀分布到所有处理 node 上。
使用 Partition 进行多租管理也有助于提高可扩展性和性能。这种方法有效地组织了数据,并通过限制适当用户的数据可见性来增强数据安全和隐私。此外,Milvus 可以高效管理单个 Collection 中多达一百亿条数据。
对于少于 10,000 个租户的多租应用,通过 Collection 管理数据可以更有效控制数据。
Partition key 可以通过动态分段数据来有效支持数百万用户的服务,从而支持无限更多的租户。
Milvus 是一个专为处理大量查询设计的分布式系统。只需添加更多节点就可以显著提升性能,为你的应用打开无限可能。对于最初不需要大量资源的小型数据集,增加内存储备(通常是当前分配的两到三倍)可以有效地将每秒查询数(QPS)翻倍。这种可扩展的框架确保了随着数据的增长,您的数据库能力也能随之增长,从而确保整个系统的高效和可靠性能。
选择、评估并优化索引
在原型阶段,将所有数据加载到内存中是常见的做法,因为这样可以加快处理速度并简化开发。然而,当你进入生产阶段并且数据量增加时,将所有数据存储在内存中变得不可行。这是因为:
-
内存相对于磁盘存储是有限且昂贵的。
-
大型数据集可能会超过可用的内存容量。
-
将所有数据加载到内存中会显著增加启动时间和资源消耗。
为了在生产中高效处理更大的数据集,你需要选择合适的索引策略。合适的索引可以优化 RAG 应用的性能,包括查询速度、存储需求和延时。
上图展示了不同索引在三个关键指标上的差异:
-
每秒查询数(QPS):用于衡量索引每秒可以处理的搜索查询数量,反映索引吞吐量和效率。
-
存储:用于表示存储索引所需的磁盘空间大小,可能会影响基础设施成本和可扩展性。
-
延时:指处理单个查询并返回结果所需的时间,反应应用的响应速度。
通过比较不同索引在这些指标上的性能差异,您可以根据用例和需求做出合适的选择。
Milvus 提供了灵活的索引选择,以满足各种存储和性能需求:
-
GPU 索引是高性能环境的首选选项,支持快速的数据处理和检索。
-
内存索引是一个中间选项,平衡了性能和容量,提供了良好的 QPS,并能够扩展到 TB 级存储,平均延时约为 10 毫秒。
-
磁盘索引可以管理数十 TB 的数据,延时约为 100 毫秒,适用于较大且对时间敏感度较低的数据集。Milvus 是唯一支持磁盘索引的开源向量数据库。
-
Swap 索引促进了 S3 或其他对象存储解决方案与内存之间的数据交换。这种方法显著降低了成本——大约降低了十倍——同时有效地管理延时。访问时间约为 100 毫秒,但对于不常访问的“冷”数据,可能会延长到几秒钟,适用于离线用例和对预算有限的应用。
在选择索引后,您可以根据索引构建时间、准确性、性能和资源消耗来评估其性能。例如,一个未优化的索引可能仅支持每秒 20 次查询。优化索引可以显著提高 QPS,可能通过每次调优迭代将 QPS 增加十倍(但这也会增加查看时间)。
为了有效选择和微调索引,您应该:
-
根据你的具体需求选择合适的索引类型。
-
调整索引参数以优化性能。
-
根据您的用例进行性能测试以确保索引按预期执行。
-
调整搜索参数以进一步提高性能。
如果您对优化过程感到不确定,可以利用像 VectorDBBench 这样的性能测试工具。这个开源工具由 Zilliz 开发,可用于评估所有主流的向量数据库,可以帮助您进行全面的实验并微调系统以获得最佳性能。
我们准备了一份快速参考指南,介绍了 GPU 索引中每个索引的性能。
总结
在这份全面的指南中,我们介绍了向量数据库以及如何优化其性能和提高其扩展性。从设计 Schema 的基础知识到管理复杂大型数据集的方式,我们涵盖了开发人员在使用向量数据库时需要了解的基本策略和最佳实践。
随着向量数据库的发展,本指南旨在帮助开发人员构建更强大、高效和可扩展的应用。无论您是经验丰富的数据库专业人士还是新手,本文都能帮助您更自信和熟练地应对复杂的向量数据库。