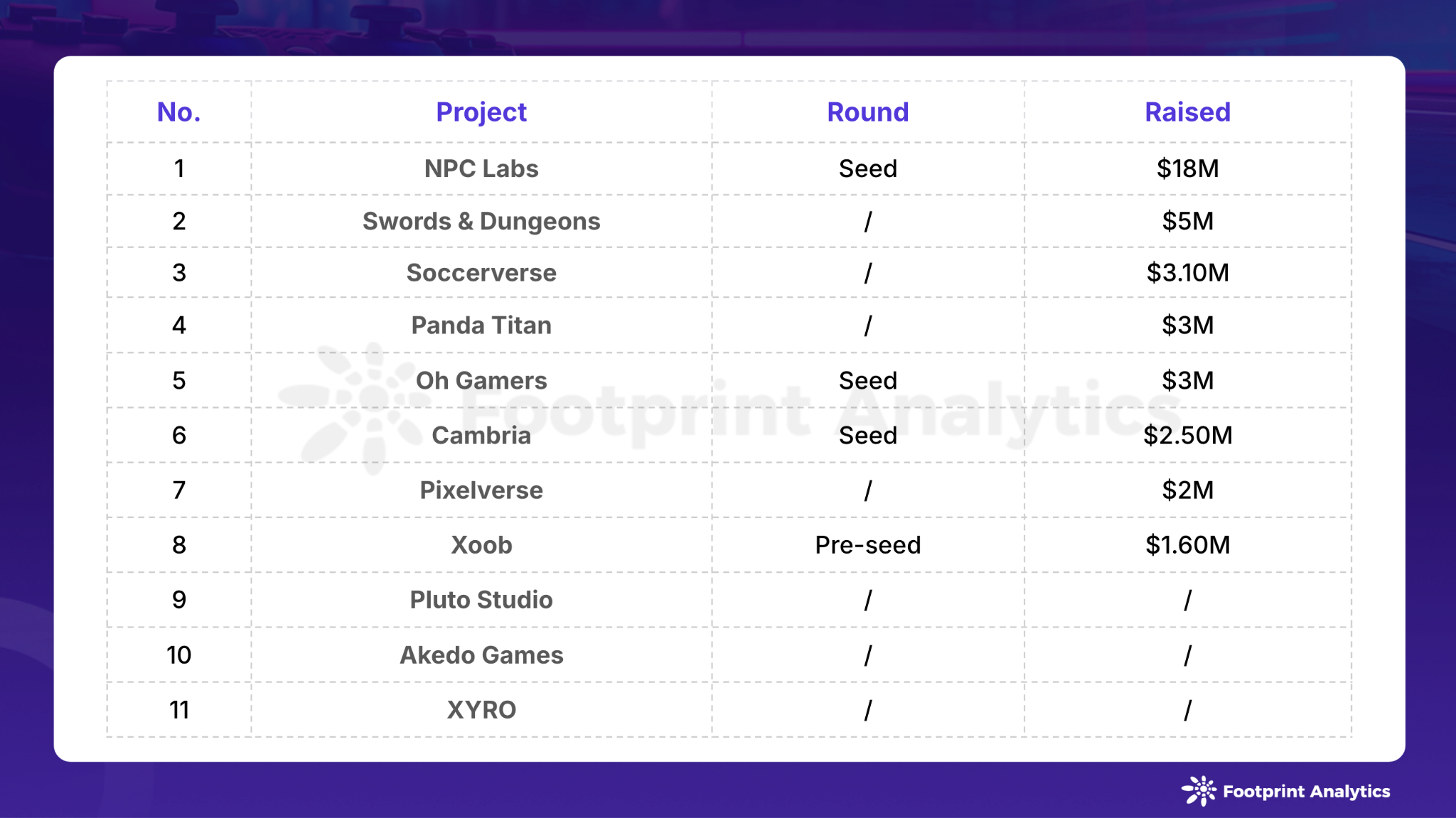
一、Bit中不同命令使用的场景

二、什么是缓存击穿,缓存穿透,缓存雪崩?
缓存击穿:是指当某一个key的缓存过期时大并发量的请求同时访问key,瞬间击穿服务器直接访问到数据库,使得数据库处于负载情况
缓存穿透:是指缓存服务器中没有缓存数据,数据库中也没用符合条件的数据,导致业务系统每次都绕过缓存服务器查询下游的数据库,缓存服务器完全失去作用
缓存击穿是只击穿服务器端访问数据库,而缓存穿透是服务器端和数据库都没有的情况
缓存雪崩:是指当大量缓存同时过期或者缓存服务宕机,所有请求都直接访问数据库,造成数据高负载,影响性能,甚至数据库宕机
对于缓存击穿可以用异步加载、互斥锁和提前预热的办法解决
对于缓存穿透的防止常用的是布隆过滤器和黑名单的方式
布隆过滤器是一种比较巧妙的概率性数据结构,它可以告诉你数据一定不存在或可能存在,相比Map、Set、List等传统的数据结构,它占用的内存少、结构更高效
对于缓存雪崩的情况可以设置不同的过期时间和集群的方法实现
三、Redis的集群方式是什么?
典型回答
Redis有三种主要的集群模式,用于在分布式环境中实现高可用性和数据复制,模式主要是:主从模式、哨兵模式和Redis Cluster模式
1. 主从模式
主从模式是Redis中最简单的集群模式,这个模式主要是为了解决单点故障的问题,所以将数据复制多个副本中,这样即使有一台服务器出现故障,其他服务器依旧可以继续提供服务。
主从模式中主要包括一个主节点和多个从节点,主节点负责处理所有读和写操作,而从节点则复制主节点的数据,并且只处理读操作,当主节点出现故障时,可以将包含数据较多的从节点升级为主节点,实现故障转移,但是这个步骤需要手动实现
主从模式的优点:简单明了,适用于读多写少的场景
缺点:不具备自动转移功能的能力,没办法容错和恢复
哨兵模式
为了解决主从模式的不能自动容错及恢复的问题,Redis引入了一种哨兵模式的集群架构。
哨兵模式是在主从模式的基础上加入了哨兵节点,哨兵节点是一种特殊的Redis节点,用于监控主节点和从节点的状态。当主节点出现故障时,哨兵节点可以自动进行故障转移,选择一个包含数据较多的从节点升级为主节点,并通知其他节点和应用程序进行更新。
优点:解决了主从模式的不能自动转移故障的问题,提供了自动化监控和故障恢复机制
缺点:虽然可以自动故障转移但是还是不支持自动的数据分区,并且随着节点数量的增加,管理和配置的复杂性会增大
Cluster模式
Redis Cluster模式是Redis中推荐的一种分布式集群解决方案,它将数据自动分片到多个节点上,每个节点负责一部分数据
优点:真正实现了分布式存储,每个节点都可以处理读写请求,具备良好的水平扩展能力,内置数据分割、故障排查、和转移能力
缺点:相比于其他模式,更加复杂,需要更多的网络资源和配置管理,客户端需要支持集群特性,跨slot的数据操作可能涉及多个节点,有一定的复杂度
四、Redis过期键的删除策略?
Redis的Key是可以设置过期时间的,Redis的key有着两种删除策略:1.惰性删除,2.定期删除
** 1. 惰性删除**:当key过期时,先放着不管,当每次从键空间中获取key时,检查取得的键是否已经过期,如果已过期的话,就删除该键,如果没有过期,就返回该键
** 2.定期删除**:每隔一段时间就对数据库进行一次扫描检查,删除里面的过期键,至于要删除多少键,检查多少数据库,要由算法决定
五、Redis的内存删除策略有哪些?
Redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
Redis提供了8种数据淘汰策略
LRU全称Least recently used, 淘汰的是最近最少被使用的数据项。(时间概念) 最近最少
LFU全称Least-frequently used,淘汰的是访问频率最低的数据项。 一直最少
- 默认策略 noeviction 不淘汰数据,写不进去返回错误
- 只针对设置过期的keys
1. volatile-lru 根据LRU算法挑选数据淘汰
2. volatile-lfu 根据LFU算法挑选数据淘汰
3. volatile-random 随机挑选数据淘汰
4. volatile-ttl 挑选越早过期的数据进行删除 - 所有keys
1. allkeys-lru 根据LRU算法挑选数据淘汰
2. allkeys-random 随机挑选数据淘汰
3. allkeys-lfu LFU算法挑选数据淘汰
六、阐述Redis的主从同步机制?
Redis的主从同步机制是一种特别重要的特性,它允许数据从一个Redis主服务器复制到一个或多个从服务器。这种机制不仅可以提高系统的读取性能,还可以用于数据备份和高可用架构的设计
主要步骤:
第1-4步属于全量,第5步属于增量
- 从服务器向主服务器发送同步命令:sync
- 主服务器接收到同步命令后,会执行bgsave命令,在后台生成一个rdb文件,并使用一个缓冲区记录从现在开始执行的所有写命令
- 当主服务器执行完bgsave命令后,主服务器会将bgsave命令生成的rdb文件发送给从服务器
- 从服务器接收到这个rdb文件,然后加载到内存;之后主服务器会把刚刚在缓存区的命令同步过来,从服务器就会执行这些命令
- 以上处理完之后,主数据库每执行一个写命令,都将写命令发送给从数据库
七、Redis和Mysql数据库数据如何保持一致性?
我们在实际项目中经常使用到Redis缓存用来缓解数据库压力,但是当更新数据库时,我们一般采用延时双删策略。目前常用的做法是查询一个接口,先查询Redis,如果不存在则查询数据库,并将结果放入到Rdis中。
7.1 常见的更新策略
- 先删缓存,再更新数据库
- 先更新数据库,再删缓存
- 普通双删
- 延时双删
7.1.1 先删缓存,再更新数据库

- 线程A删除缓存数据,此时还没有更新数据库
- 线程B 查询缓存没有数据,查询数据库还是旧数据,放入缓存
- 线程C以及其他线程使用旧缓存数据,缓存和数据库不一致
7.1.2 先更新数据库,再删除缓存
- 线程A更新数据库,此时还没有删除缓存
- 线程B以及其他线程此时还是使用的旧缓存数据,和数据库不一致
7.1.3 普通双删

- 线程A先删除缓存,再更新数据库,然后再删除一次缓存
- 线程B查询缓存时没有数据,在线程A更新数据库之前,查询到旧数据,此时系统时间切换到线程A执行删除缓存,然后又到线程B放入缓存旧数据
- 线程C针对线程A,查询到缓存没有数据,查询数据库的旧数据,然后将旧数据放入到缓存中
这些都不能满足缓存和数据一致性
7.1.4 延时双删

- 线程A先删除缓存,之后再更新数据库
- 线程B和线程C查询数据时,才发现缓存中没有数据,就去查询数据库,线程B查询到的是旧数据,线程C查询到的是新数据,之后都放入到缓存中。
- 线程A延时3-5秒(时间一般要大于SQL执行时间+线程切换时间)后,再将缓存删除。之后其他线程再次查询缓存,发现没有数据,再去查询数据库并且放入缓存都是新数据
- 极端情况下,就是如线程D,延时时间超过线程A的延时时间后,再次将旧数据放入到缓存中,这时缓存和数据库的数据还不是一致的,所以延时双删也不是一定能够保证缓存和数据保持一致的
7.2 建议的解决方案
- 当发现缓存没有数据后,在执行查询数据库前,对该key进行加锁,查询数据库并放入缓存后再解锁,这样可以避免缓存击穿问题,当某个redis数据不存在时,大量线程并发查询数据库。
- 在需要执行双删前,对该Key进行加锁,之后执行删除缓存,更新数据库,放入新数据到缓存,在解锁。保证缓存和数据一致性。
- 加锁的Key都需要设置过期时间,避免因为宕机造成死锁。