今天要给大家介绍的Python框架叫做ibis,没错,跟著名连锁酒店宜必思同名,其作者是创造了pandas、Arrow等著名框架的Wes McKinney。

ibis的核心理念是用同一套数据框操作API,统一操纵各种主流的数据运算框架,使得用户可以更轻松更一致的构建自己的数据分析处理过程,而不是囿于不同框架之间千差万别的用法,下面我们就来一起学习其基础用法😉~

2 ibis基础用法介绍
2.1 ibis的安装
为了方便演示,我们这里使用conda或mamba创建新的虚拟环境,来安装试用ibis,以mamba为例,在终端中执行下列命令,完成演示用虚拟环境的创建及激活,并安装ibis最基础的相关模块+示例数据集模块:

验证是否安装成功:

可以看到,我们完成了对ibis的安装,当前版本为9.0.0:
2.2 ibis主要功能
2.2.1 构建具有便携性的分析逻辑
ibis本身不直接执行分析计算,当我们针对目标数据编写好对应计算逻辑的ibis代码后,实际执行时其底层会将计算逻辑自动转换到当前的计算后端中。目前ibis支持「超过20种」计算后端,均为当前「单机分析」、「分布式分析」领域的主流框架:
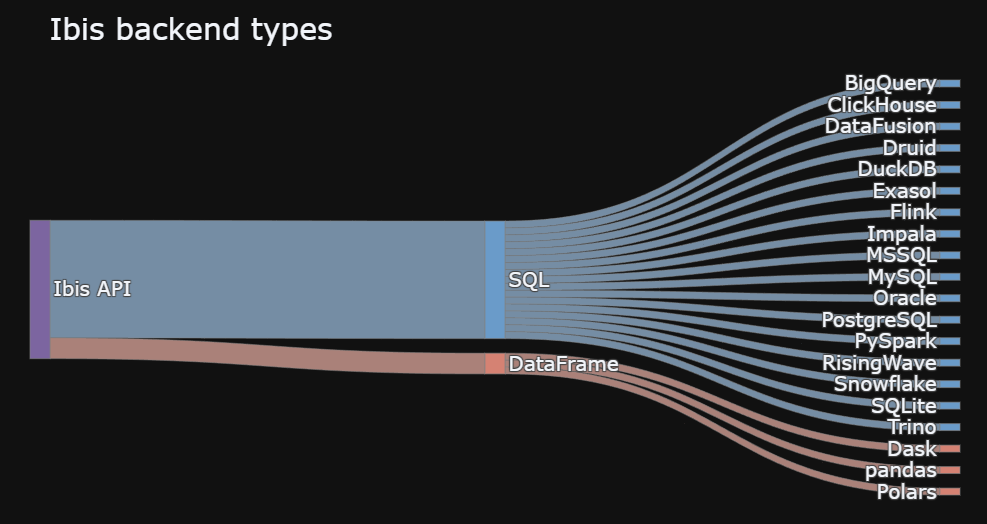
这使得基于ibis构建的数据分析工作流,可以在不修改代码的情况下,轻松扩展应用于任意的计算后端。
譬如,ibis默认使用DuckDB作为后端进行单机分析运算,你可以在本机上使用部分数据构建并验证业务分析逻辑后,再套用相同的代码,切换计算后端到诸如ClickHouse上执行分布式运算,这一特性也是ibis「便携性」的体现。
举个简单的例子,首先我们基于pandas生成具有一千万行记录的示例数据并导出为parquet格式:

接下来我们先使用默认的DuckDB后端,在ibis中执行一些示例运算,注意其运算耗时:
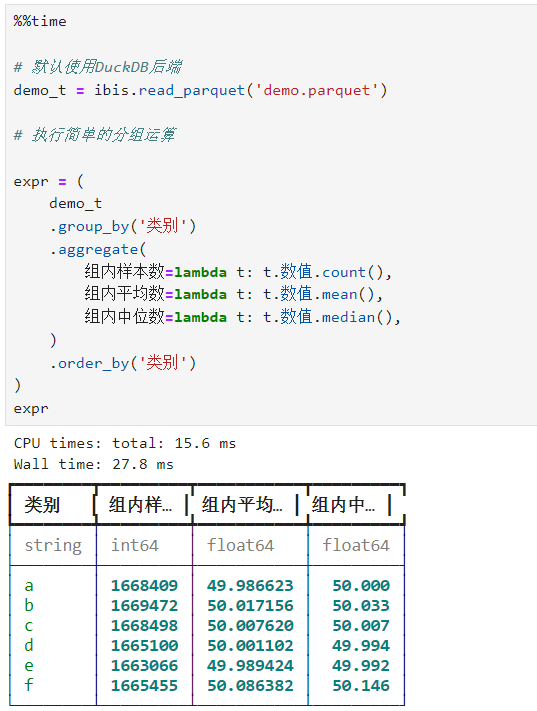
接着,我们切换计算后端为pandas,执行完全一样的计算代码,可以看到计算耗时陡增,毕竟pandas处理上千万行数据性能要远逊于DuckDB,这个例子体现出ibis强大的代码便携性:

2.2.2 充分搭配Python与SQL
ibis中另一个非常强大的功能,是其可以充分结合Python代码和SQL代码来开展分析工作,譬如,你可以将ibis分析代码直接转换为SQL语句:
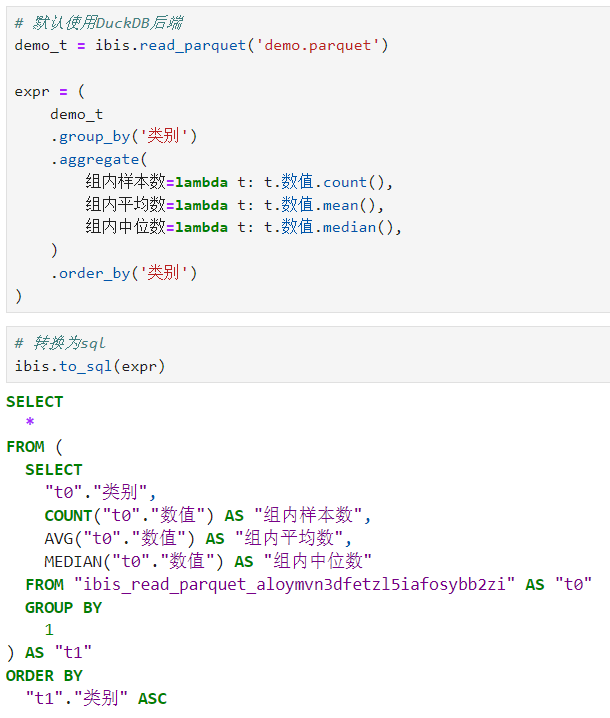
也可以直接执行SQL语句开展分析:
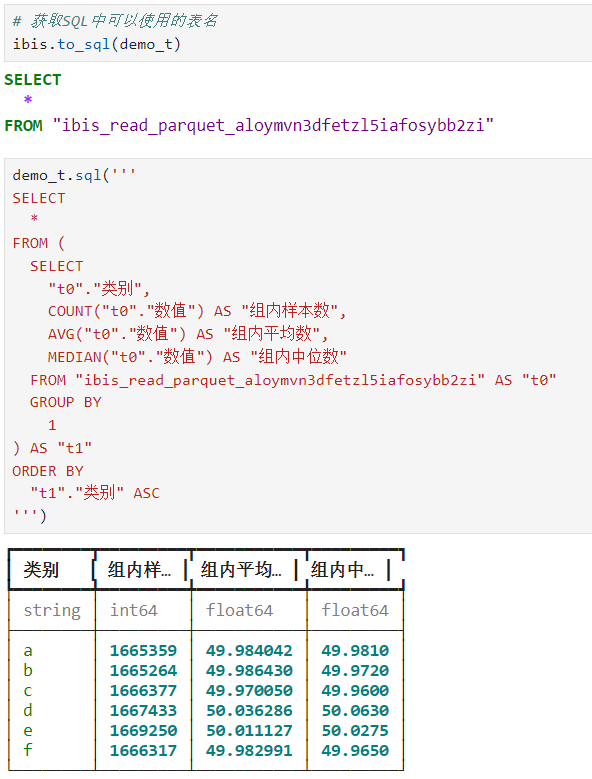
这使得ibis可以充分联结各类最先进的计算后端,帮助分析师轻松维护业务分析逻辑。
无论你原先在使用pandas、SQL还是R进行数据分析,ibis官网文档中都提供了非常友好的使用指南,确保你可以无痛的迁移使用ibis:
ibis正处于高速迭代发展阶段,其代码仓库几乎每天都在进行新的提交活动,欢迎进行⭐支持:https://github.com/ibis-project/ibis
更多相关内容,请移步其官网学习更多:https://ibis-project.org/



















