一、基本概念
前面学习的哨兵模式,提高了系统的可用性。但是真正用来存储数据的还是 master 和 slave 节点,所有的数据都需要存储在单个 master 和 slave 节点中。如果数据量很大,接近超出了 master / slave 所在机器的物理内存,就可能出现严重问题了。
虽然硬件价格在不断降低,一些中大厂的服务器内存已经可以达到 TB 级别了,但是 1TB 在当前这个 “大数据” 时代,俨然不算什么,但有的时候我们确实需要更大的内存空间来保存更多的数据。
如何获取更大的空间?
加机器即可,所谓 “大数据” 的核心其实就是一台机器搞不定了,用多台机器来搞。
Redis 的集群就是在上述的思路之下,引入多组 Master / Slave,每⼀组 Master / Slave 存储数据全集的一部分,从而构成一个更大的整体,称为 Redis 集群(Cluster)。
- 广义的 “集群”:只要是多个机器构成了分布式系统,都可以称为是一个 “集群”。前面学习的主从结构、哨兵模式,也可以称为是 “广义的集群”。
- 狭义的 “集群”:Redis 提供的集群模式,在这个集群模式之下,主要是解决存储空间不足的问题(扩展存储空间)。
假定整个数据全集是 1 TB,引入三组 Master / Slave 来存储,那么每⼀组机器只需要存储整个数据全集的 1/3 即可。

- Master1 和 Slave11 和 Slave12 保存的是同样的数据,占总数据的 1/3。
- Master2 和 Slave21 和 Slave22 保存的是同样的数据,占总数据的 1/3。
- Master3 和 Slave31 和 Slave32 保存的是同样的数据,占总数据的 1/3。
这三组机器存储的数据都是不同的。每个 Slave 都是对应 Master 的备份(当 Master 挂了,对应的 Slave 会补位成 Master)。每个红框部分都可以称为是一个分片(Sharding)。如果全量数据进一步增加,只要再增加更多的分片即可解决。
数据量多了,使用硬盘来保存不行吗?
硬盘只是存储空间大了,但是访问速度是比内存慢很多的。但实际上,还是存在很多的应用场景,既希望存储较多的数据,又希望有非常高的读写速度,比如搜索引擎。
二、数据分片算法
Redis cluster 的核心思路是用多组机器来存数据的每个部分。
给定一个数据(一个具体的 key),那么这个数据应该存储在哪个分片上? 读取的时候又应该去哪个分片读取呢?
围绕这个问题,业界有三种比较主流的实现方式:
1、哈希求余
借鉴了哈希表的基本思想。借助 hash 函数,把一个 key 映射到整数,再针对数组的长度进行求余,就可以得到一个数组下标。
设有 N 个分片,使用 [0, N-1] 这样序号进行编号。针对某个给定的 key,先计算 hash 值,再把得到的结果 % N,得到的结果即为分片编号。例如:N 为 3,给定的 key 为 "hello",对 "hello" 计算 hash 值(比如使用 md5 算法:针对一个字符串,将里面的内容进行一系列的数学变化,转换为整数。特点:md5 计算结果是定长的,其计算结果是分散的,计算结果是不可逆的),得到的结果为:bc4b2a76b9719d91,再把这个结果 % 3(hash(key) % N => 0),结果为 0,那么就把 hello 这个 key 放到 0 号分片上。
当然,实际工作中涉及到的系统,计算 hash 的方式不一定是 md5,但是思想是一致的。
![]()
后续如果要取某个 key 的记录, 也是针对 key 计算 hash , 再对 N 求余, 就可以找到对应的分片编号了。
- 优点:简单高效,数据分配均匀。
- 缺点:一旦需要进行扩容,N 发生了改变,那么原有的映射规则被破坏,就需要让节点之间的数据相互传输,重新排列,以满足新的映射规则。此时需要搬运的数据量是比较多的,开销较大。
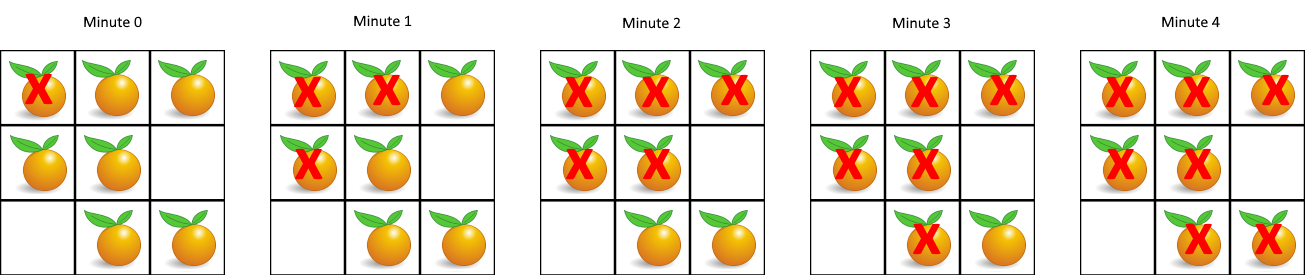
N 为 3 的时候,[100, 120] 这 21 个 hash 值的分布(此处假定计算出的 hash 值是一个简单的整数,方便肉眼观察)
当引入一个新的分片,N 从 3 => 4 时,大量的 key 都需要重新映射(某个 key % 3 和 % 4 的结果不一样,就映射到不同机器上了)。

如上图可以看到,整个扩容一共 21 个 key,只有 3 个 key 没有经过搬运,其他的 key 都是搬运过的。
2、一致性哈希算法
交替出现导致搬运成本高,为了降低上述的搬运开销,能够更高效扩容,业界提出了 “一致性哈希算法”。
key 映射到分片序号的过程不再是简单求余了,而是改成以下过程:
(1)把 0 -> 2^32-1 这个数据空间映射到一个圆环上,数据按照顺时针方向增长。

(2)假设当前存在三个分片,就把分片放到圆环的某个位置上

(3)假定有一个 key,计算得到 hash 值 H,那么这个 key 映射到哪个分片呢?
规则很简单,就是从 H 所在位置顺时针往下找,找到的第一个分片,即为该 key 所从属的分片。

这就相当于,N 个分片的位置把整个圆环分成了 N 个管辖区间。Key 的 hash 值落在某个区间内,就归对应区间管理。

上述一致性哈希算法的过程类似于去高铁站取票。现在的高铁站都可以直接刷身份证了,但是以前的时候需要网上先购票,然后再去高铁站的取票机上把票取出来。
想象一下下列场景:

假设一个人每次来高铁站,都会停车在同一个位置(不同的人停车位置不同)。每个人下车之后,都往右手方向走,遇到第一个取票机就进行取票。
在这个情况下,如果扩容一个分片,如何处理呢?
原有分片在环上的位置不动,只要在环上新安排一个分片位置即可。 此时,只需要把 0 号分片上的部分数据搬运给 3 号分片即可,而 1 号分片和 2 号分片管理的区间都是不变的。
此时,只需要把 0 号分片上的部分数据搬运给 3 号分片即可,而 1 号分片和 2 号分片管理的区间都是不变的。
- 优点:大大降低了扩容时数据搬运的规模,提高了扩容操作的效率。
- 缺点:数据分配不均匀(有的多有的少,数据倾斜)。
3、哈希槽分区算法(Redis 使用)
为了解决上述问题(搬运成本高和数据分配不均匀),Redis cluster 引入了哈希槽(hash slots)算法。
hash_slot = crc16(key) % 16384其中 crc16 也是一种 hash 算法。
16384 其实是 16 * 1024,也就是 2^14(16k),相当于是把整个哈希值映射到 16384 个槽位上,也就是 [0, 16383]。然后再把这些槽位比较均匀的分配给每个分片,每个分片的节点都需要记录自己持有哪些分片。
假设当前有三个分片,一种可能的分配方式:
- 0 号分片:[0, 5461],共 5462 个槽位。
- 1 号分片:[5462, 10923],共 5462 个槽位。
- 2 号分片:[10924, 16383],共 5460 个槽位。
这里的分片规则是很灵活的,虽然每个分片持有的槽位也不一定连续,但此时这三个分片上的数据是比较均匀了。每个分片的节点使用位图来表示自己持有哪些槽位。对于 16384 个槽位来说,需要 2048 个字节(2KB)大小的内存空间表示。
如果需要进行扩容,比如新增一个 3 号分片,就可以针对原有的槽位进行重新分配。比如可以把之前每个分片持有的槽位各拿出一点,分给新分片。
一种可能的分配方式:
- 0 号分片:[0, 4095],共 4096 个槽位。
- 1 号分片:[5462, 9557],共 4096 个槽位。
- 2 号分片:[10924, 15019],共 4096 个槽位。
- 3 号分片:[4096, 5461] + [9558, 10923] + [15019, 16383],共 4096 个槽位。
在上述过程中,只有被移动的槽位所对应的数据才需要搬运。
在实际使用 Redis 集群分片的时候,不需要手动指定哪些槽位分配给某个分片,只需要告诉某个分片应该持有多少个槽位即可,Redis 会自动完成后续的槽位分配,以及对应的 key 搬运的工作。
Redis 集群是最多有 16384 个分片吗?
并非如此,如果一个分片只有一个槽位,key 是要先映射到槽位,再映射到分片的,这对于集群的数据均匀其实是难以保证的。实际上 Redis 的作者建议集群分片数不应该超过 1000。而且,16000 这么大规模的集群,本身的可用性也是一个大问题。一个系统越复杂,出现故障的概率是越高的。
为什么是 16384 个槽位?
Redis 作者答案:
why redis-cluster use 16384 slots? · Issue #2576 · redis/redis (github.com)
翻译:
- 节点之间通过心跳包通信。心跳包中包含了该节点持有哪些 slots,这个是使用位图这样的数据结构表示的,表示 16384(16k)个 slots,需要的位图大小是 2KB。如果给定的 slots 数更多了,比如 65536 个了,那么此时就需要消耗更多的空间,8 KB 位图表示了。8 KB 对于内存来说不算什么,但是在频繁的网络心跳包中,还是一个不小的开销的。
- 另一方面,Redis 集群一般不建议超过 1000 个分片,所以 16k 对于最大 1000 个分⽚来说是足够用的, 同时也会使对应的槽位配置位图体积不至于很大。
三、集群搭建(基于 Docker)
接下来基于 docker,搭建一个集群,每个节点都是一个容器。
拓扑结构如下:

注意 :此处我们先创建出 11 个 redis 节点,其中前 9 个用来演示集群的搭建,后两个用来演示集群扩容。
(1)第一步(创建目录和配置)
创建 redis-cluster 目录,内部创建两个文件:


注意:防止后面出现端口冲突的情况,所以需要提前把之前的 redis 容器给停止掉。
在 Linux 上,以 .sh 后缀结尾的文件称为 “shell 脚本”。使用 Linux 的时候,是通过一些命令来进行操作的,使用命令操作,就非常适合把命令给写到一个文件中,批量化进行。同时还能加入条件、循环、函数等机制,因此便可以基于这些来完成更复杂的工作。
需要创建 11 个 redis 节点,这些 redis 的配置文件内容大同小异,此时就可以使用脚本来批量生成(也可以不使用脚本,手动一个个修改,这样做比较麻烦)。
generate.sh 内容如下:
for port in $(seq 1 9); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.10${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done# 注意 cluster-announce-ip 的值有变化
for port in $(seq 10 11); \
do \
mkdir -p redis${port}/
touch redis${port}/redis.conf
cat << EOF > redis${port}/redis.conf
port 6379
bind 0.0.0.0
protected-mode no
appendonly yes
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
cluster-announce-ip 172.30.0.1${port}
cluster-announce-port 6379
cluster-announce-bus-port 16379
EOF
done
- shell 中 { } 用来表示变量,而不是代码块。
- \ 是续行符,把下一行的内容和当前行合并成一行。在 shell 默认情况下,要求把所有的代码都写到一行里,使用续行符来换行。
- shell 中拼接字符串是直接写到一起,而不需要使用 +。
执行命令:
![]()
生成目录如下:
redis-cluster/
├── docker-compose.yml
├── generate.sh
├── redis1
│ └── redis.conf
├── redis10
│ └── redis.conf
├── redis11
│ └── redis.conf
├── redis2
│ └── redis.conf
├── redis3
│ └── redis.conf
├── redis4
│ └── redis.conf
├── redis5
│ └── redis.conf
├── redis6
│ └── redis.conf
├── redis7
│ └── redis.conf
├── redis8
│ └── redis.conf
└── redis9└── redis.conf
其中 redis.conf 每个都不同,以 redis1 为例:
区别在于每个配置中配置的 cluster-announce-ip 是不同的,其他部分都相同。
![]()
后续会给每个节点分配不同的 ip 地址。配置说明:
- cluster-enabled yes 开启集群。
- cluster-config-file nodes.conf 集群节点生成的配置。
- cluster-node-timeout 5000 节点失联的超时时间。
- cluster-announce-ip 172.30.0.101 节点自身 ip。
- cluster-announce-port 6379 节点自身的业务端口。
- cluster-announce-bus-port 16379 节点自身的总线端口,集群管理的信息交互是通过这个端口进行的。
(2)第二步(编写 docker-compose.yml)
- 为了后续创建静态 ip,此处要先手动创建 networks,并分配网段为:172.30.0.0/24。
- 配置每个节点。注意配置文件映射,端口映射,以及容器的 ip 地址,设定成固定 ip 方便后续的观察和操作。
此处的端口映射不配置也可以,配置的目的是为了可以通过宿主机 ip + 映射的端口进行访问,通过容器自身 ip:6379 的方式也可以访问。
version: '3.7'
networks:mynet:ipam:config:- subnet: 172.30.0.0/24services:redis1:image: 'redis:5.0.9'container_name: redis1restart: alwaysvolumes:- ./redis1/:/etc/redis/ports:- 6371:6379- 16371:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.101redis2:image: 'redis:5.0.9'container_name: redis2restart: alwaysvolumes:- ./redis2/:/etc/redis/ports:- 6372:6379- 16372:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.102redis3:image: 'redis:5.0.9'container_name: redis3restart: alwaysvolumes:- ./redis3/:/etc/redis/ports:- 6373:6379- 16373:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.103redis4:image: 'redis:5.0.9'container_name: redis4restart: alwaysvolumes:- ./redis4/:/etc/redis/ports:- 6374:6379- 16374:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.104redis5:image: 'redis:5.0.9'container_name: redis5restart: alwaysvolumes:- ./redis5/:/etc/redis/ports:- 6375:6379- 16375:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.105redis6:image: 'redis:5.0.9'container_name: redis6restart: alwaysvolumes:- ./redis6/:/etc/redis/ports:- 6376:6379- 16376:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.106redis7:image: 'redis:5.0.9'container_name: redis7restart: alwaysvolumes:- ./redis7/:/etc/redis/ports:- 6377:6379- 16377:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.107redis8:image: 'redis:5.0.9'container_name: redis8restart: alwaysvolumes:- ./redis8/:/etc/redis/ports:- 6378:6379- 16378:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.108redis9:image: 'redis:5.0.9'container_name: redis9restart: alwaysvolumes:- ./redis9/:/etc/redis/ports:- 6379:6379- 16379:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.109redis10:image: 'redis:5.0.9'container_name: redis10restart: alwaysvolumes:- ./redis10/:/etc/redis/ports:- 6380:6379- 16380:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.110redis11:image: 'redis:5.0.9'container_name: redis11restart: alwaysvolumes:- ./redis11/:/etc/redis/ports:- 6381:6379- 16381:16379command:redis-server /etc/redis/redis.confnetworks:mynet:ipv4_address: 172.30.0.111
(3)第三步(启动容器)
在启动之前一定要把之前已经运行的 redis 容器给停掉,否则就可能因为端口冲突等原因导致现在的启动失败。



(4)第四步(构建集群)
A. 启动⼀个 docker 客⼾端.
此处是把前 9 个主机构建成集群,3 主 6 从(随机分配),后 2 个主机暂时不用。
redis-cli --cluster create 172.30.0.101:6379 172.30.0.102:6379 172.30.0.103:6379 172.30.0.104:6379 172.30.0.105:6379 172.30.0.106:6379 172.30.0.107:6379 172.30.0.108:6379 172.30.0.109:6379 --cluster-replicas 2![]()
- --cluster create 表示建立集群,后面填写每个节点的 ip 和地址。
- --cluster-replicas 2 表示每个主节点需要两个从节点备份。
执行之后,容器之间会进行加入集群操作。
日志中会描述哪些是主节点,哪些从节点跟随哪个主节点。

见到下方的 OK 说明集群建立完成。
此时,使用客户端连上集群中的任何一个节点,都相当于连上了整个集群。
- 客户端后面要加上 -c 选项,否则如果 key 没有落到当前节点上,是不能操作的,-c 会自动把请求重定向到对应节点。
- 使用 cluster nodes 可以查看到整个集群的情况。


四、主节点宕机
1、演示效果
如果集群中的从节点挂了,是没有什么影响的。但如果挂了的节点是主节点,此时就会产生影响力,因为主节点才能处理写操作,从节点是不能写的。
手动停止一个 master 节点,观察效果。
比如上述拓扑结构中,可以看到 redis1 redis2 redis3 是主节点,随便挑一个停掉。
![]()
连上 redis2,观察效果:

可以看到:101 已经提示 fail,且原本是 slave 的 105 成了新的 master。
此时如果重新启动 redis1:
![]()
再次观察结果,可以看到 101 启动了,仍然是 slave。

可以使用 cluster failover 进行集群恢复,也就是把 101 重新设定成 master(登录到 101 上执行)。
2、处理流程
(1)故障判定
集群中的所有节点都会周期性的使用心跳包进行通信。
- 节点 A 给节点 B 发送 ping 包,B 就会给 A 返回⼀个 pong 包。ping 和 pong 除了 message type 属性之外,其他部分都是一样的。这里包含了集群的配置信息(该节点的 id,该节点从属于哪个分片,是主节点还是从节点,从属于谁,持有哪些 slots 的位图...)。
- 每个节点,每秒钟都会给一些随机的节点发起 ping 包,而不是全发一遍。这样设定是为了避免在节点很多的时候,心跳包也非常多(比如有 9 个节点,如果全发,就是 9 * 8 有 72 组心跳了,而且这是按照 N^2 这样的级别增长的)。
- 当节点 A 给节点 B 发起 ping 包,B 不能如期回应的时候,此时 A 就会尝试重置和 B 的 tcp 连接,看能否连接成功。如果仍然连接失败,A 就会把 B 设为 PFAIL 状态(相当于主观下线)。
- A 判定 B 为 PFAIL 之后,会通过 redis 内置的 Gossip 协议和其他节点进行沟通,向其他节点确认 B 的状态(每个节点都会维护一个自己的 “下线列表”,由于视角不同,每个节点的下线列表也不一定相同)。
- 此时 A 发现其他很多节点也认为 B 为 PFAIL,并且数目超过总集群个数的一半,那么 A 就会把 B 标记成 FAIL(相当于客观下线),并且把这个消息同步给其他节点(其他节点收到之后,也会把 B 标记成 FAIL)。
至此,B 就彻底被判定为故障节点了。
某个或者某些节点宕机,有的时候会引起整个集群都宕机(称为 fail 状态)。
- 某个分片,所有的主节点和从节点都挂了。(该分片就无法提供数据服务了)
- 某个分片,主节点挂了,但是没有从节点。(该分片就无法提供数据服务了)
- 超过半数的 master 节点都挂了。(情况严重)
核心原则是保证每个 slots 都能正常⼯工作(存取数据)。
(2)故障迁移
上述例子中,B 故障且 A 把 B FAIL 的消息告知集群中的其他节点。
- 如果 B 是从节点,那么不需要进行故障迁移。
- 如果 B 是主节点,那么就会由 B 的从节点(比如 C 和 D) 触发故障迁移了。
所谓故障迁移,就是指把从节点提拔成主节点,继续给整个 redis 集群提供支持。
具体流程如下:
- 从节点判定自己是否具有参选资格。如果从节点和主节点已经太久没通信(此时认为从节点的数据和主节点差异太大了),时间超过阈值就失去竞选资格。
- 具有资格的节点,比如 C 和 D 就会先休眠⼀定时间,休眠时间 = 500ms 基础时间 + [0, 500ms] 随机时间 + 排名 * 1000ms。offset 的值越大,则排名越靠前(越小)。
- 比如 C 的休眠时间到了,C 就会给其他所有集群中的节点,进行拉票操作,但是只有主节点才有投票资格。
- 主节点就会把自己的票投给 C(每个主节点只有 1 票)。当 C 收到的票数超过主节点数目的一半,C 就会晋升成主节点(C 自己负责执行 slaveof no one,并且让 D 执行 slaveof C)。
- 同时,C 还会把自己成为主节点的消息,同步给其他集群的节点,大家也都会更新自己保存的集群结构信息。
上述选举的过程称为 Raft 算法,是一种在分布式系统中广泛使用的算法。在随机休眠时间的加持下,基本上就是谁先唤醒,谁就能竞选成功。
五、集群扩容
集群扩容操作(风险高、成本大)是一个在开发中比较常遇到的场景。随着业务的发展,现有集群很可能无法容纳日益增长的数据,此时给集群中加入更多新的机器,就可以使存储的空间更大了。
所谓分布式的本质,就是使用更多的机器来引入更多的硬件资源。
1、第一步(把新的主节点加入到集群)
前面已经把 redis1 - redis9 重新构成了 3 主、6 从的集群。
接下来把 redis10 和 redis11 也加入集群(此处把 redis10 作为主机,redis11 作为从机):
![]()
add-node 后的第⼀组地址是新节点的地址,第⼆组地址是集群中的任意节点地址。
(1)执行结果

此时的集群状态如下,可以看到 172.30.0.110 这个节点已经成为了集群中的主节点。

2、第二步(重新分配 slots)
![]()
reshard 后的地址是集群中的任意节点地址。
注意:小心单词拼写错误,是 reshard(重新切分),不是 reshared(重新分享),不要多写个 e。
执行之后会进入交互式操作,redis 会提示用户输入以下内容:
- 多少个 slots 要进行 reshard?(此处我填写 4096)
- 哪个节点来接收这些 slots?(此处我填写 172.30.0.110 这个节点的集群节点 id)
- 这些 slots 从哪些节点搬运过来?(此处我填写 all,表示从其他所有的节点都进行搬运)
执行结果如下:

确定之后会初步打印出搬运计划,让用户确认。之后就会进行集群的 key 搬运工作,这个过程(重量级)涉及到数据搬运,可能需要消耗一定的时间。
如果在搬运 slots / key 的过程中,此时客户端能否访问我们的 redis 集群呢?
在搬运 key 的过程中,大部分的 key 是不用搬运的,针对这些未搬运的 key,此时是可以正常访问的。但是针对这些正在搬运的 key,进行访问就可能会出现短暂的访问错误的情况(key 的位置出现了变化)。随着搬运的完成,这样的错误自然就恢复了。
很明显,如果想要追求更高的可用性,让扩容对于用户的影响更小,那么就需要搞一组新的机器,重新搭建集群,并且把数据导入过来,使用新集群代替旧集群。(成本高)
3、第三步(给新的主节点添加从节点)
光有主节点了,此时扩容的目标已经初步达成,但是为了保证集群可用性,还需要给这个新的主节点添加从节点,保证该主节点宕机之后有从节点能够顶上。
redis-cli --cluster add-node 172.30.0.111:6379 172.30.0.101:6379 --cluster-slave --cluster-master-id [172.30.1.110 节点的 nodeId]![]()
执行完毕后,从节点就已经被添加完成了。

六、集群缩容(了解)
扩容是比较常见的,但是缩容其实非常少间,此处简单了解缩容的操作步骤即可。
下面演示把 110 和 111 这两个节点删除。
1、第一步(删除从节点)
此处删除的节点 nodeId 是 111 节点的 id:
# redis-cli --cluster del-node [集群中任⼀节点ip:port] [要删除的从机节点 nodeId]
redis-cli --cluster del-node 172.30.0.101:6379
03f4a97806a0d3de2299cc16e6a3559f0c832bc1>>> Removing node 03f4a97806a0d3de2299cc16e6a3559f0c832bc1 from cluster
172.30.0.101:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.2、第二步(重新分配 slots)
redis-cli --cluster reshard 172.30.0.101:6379执行后仍然进入交互式操作。
注意:此时要删除的主节点,包含 4096 个 slots。我们把 110 这个注解上的这 4096 个 slots 分成三份(1365 + 1365 + 1366),分别分给其他三个主节点。这样可以使 reshard 之后的集群各个分片 slots 数目仍然均匀。
- 第一次重分配:分配给 101 1365 个 slots。
接收 slots 的 nodeId 填写 101 的 nodeId,Source Node 填写 110 的 nodeId。
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? 3397c6364b43dd8a8d49057ad37be57760d3a81f
Please enter all the source node IDs.Type 'all' to use all the nodes as source nodes for the hash slots.Type 'done' once you entered all the source nodes IDs.
Source node #1: 7c343b7e3f82f2e601ac6b9eba9f846b3065c600
Source node #2: done- 第二次重分配:分配给 102 1365 个 slots。
接收 slots 的 nodeId 填写 102 的 nodeId,Source Node 填写 110 的 nodeId。
How many slots do you want to move (from 1 to 16384)? 1365
What is the receiving node ID? 98736357a53c85aaebb31fa5ad286ab36b862426
Please enter all the source node IDs.Type 'all' to use all the nodes as source nodes for the hash slots.Type 'done' once you entered all the source nodes IDs.
Source node #1: 7c343b7e3f82f2e601ac6b9eba9f846b3065c600
Source node #2: done- 第三次重分配:分配给 103 1366 个 slots。
接收 slots 的 nodeId 填写 103 的 nodeId,Source Node 填写 110 的 nodeId。
How many slots do you want to move (from 1 to 16384)? 1366
What is the receiving node ID? 26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c
Please enter all the source node IDs.Type 'all' to use all the nodes as source nodes for the hash slots.Type 'done' once you entered all the source nodes IDs.
Source node #1: 7c343b7e3f82f2e601ac6b9eba9f846b3065c600
Source node #2: done此时查看集群状态,可以看到 110 节点已经不再持有 slots 了:
127.0.0.1:6379> CLUSTER NODES
26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c 172.30.0.103:6379@16379 master - 0
1683187990000 13 connected 6826 10923-16383
ee283a923b77fda2e370ff4463cbb22047f261f7 172.30.0.108:6379@16379 slave
98736357a53c85aaebb31fa5ad286ab36b862426 0 1683187991544 12 connected
98736357a53c85aaebb31fa5ad286ab36b862426 172.30.0.102:6379@16379 master - 0
1683187991544 12 connected 5461-6825 6827-10922
b951da5c3573eec5db2926e022302188a8b686a6 172.30.0.107:6379@16379 slave
98736357a53c85aaebb31fa5ad286ab36b862426 0 1683187991645 12 connected
df193127f99c59999e14518ff7235faeb7b7e8e7 172.30.0.104:6379@16379 slave
26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c 0 1683187990000 13 connected
7c343b7e3f82f2e601ac6b9eba9f846b3065c600 172.30.0.110:6379@16379 master - 0
1683187991000 10 connected
3d148089278f9022a62a5936022e9c086fb7a062 172.30.0.105:6379@16379 slave
3397c6364b43dd8a8d49057ad37be57760d3a81f 0 1683187990540 11 connected
6de544df01337d4bbdb2f4f69f4c408314761392 172.30.0.109:6379@16379 myself,slave
26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c 0 1683187990000 9 connected
3397c6364b43dd8a8d49057ad37be57760d3a81f 172.30.0.101:6379@16379 master - 0
1683187990640 11 connected 0-5460
3b47ebc9868bbda018d8a5b926256861bb800cdc 172.30.0.106:6379@16379 slave
26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c 0 1683187991544 13 connected- 第三步:删除主节点。
把 110 节点从集群中删除:
# redis-cli --cluster del-node [集群中任⼀节点ip:port] [要删除的从机节点 nodeId]
redis-cli --cluster del-node 172.30.0.101:6379
7c343b7e3f82f2e601ac6b9eba9f846b3065c600>>> Removing node 7c343b7e3f82f2e601ac6b9eba9f846b3065c600 from cluster
172.30.0.101:6379
>>> Sending CLUSTER FORGET messages to the cluster...
>>> SHUTDOWN the node.再次查看集群节点信息,110 节点已经不在集群中了:
127.0.0.1:6379> CLUSTER nodes
26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c 172.30.0.103:6379@16379 master - 0
1683188151590 13 connected 6826 10923-16383
ee283a923b77fda2e370ff4463cbb22047f261f7 172.30.0.108:6379@16379 slave
98736357a53c85aaebb31fa5ad286ab36b862426 0 1683188152000 12 connected
98736357a53c85aaebb31fa5ad286ab36b862426 172.30.0.102:6379@16379 master - 0
1683188151000 12 connected 5461-6825 6827-10922
b951da5c3573eec5db2926e022302188a8b686a6 172.30.0.107:6379@16379 slave
98736357a53c85aaebb31fa5ad286ab36b862426 0 1683188153195 12 connected
df193127f99c59999e14518ff7235faeb7b7e8e7 172.30.0.104:6379@16379 slave
26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c 0 1683188151187 13 connected
3d148089278f9022a62a5936022e9c086fb7a062 172.30.0.105:6379@16379 slave
3397c6364b43dd8a8d49057ad37be57760d3a81f 0 1683188152191 11 connected
6de544df01337d4bbdb2f4f69f4c408314761392 172.30.0.109:6379@16379 myself,slave
26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c 0 1683188152000 9 connected
3397c6364b43dd8a8d49057ad37be57760d3a81f 172.30.0.101:6379@16379 master - 0
1683188152593 11 connected 0-5460
3b47ebc9868bbda018d8a5b926256861bb800cdc 172.30.0.106:6379@16379 slave
26e98f947b99b3a2a5da5a7c3ed3875ae9cf366c 0 1683188152694 13 connected七、代码连接集群(了解)
搭建集群之后,主要仍然是要通过代码来访问集群的,这一点 C++ 和 Java 的 redis 的库都对集群做了较好的支持。