论文概述
这篇论文的主题是研究如何在有向图中找到密度最高的子图,这个问题被称为有向最密子图(Directed Densest Subgraph, DDS)问题。该问题在许多应用中非常重要,如社交网络分析、社区发现、假粉丝检测等。论文提出了一种基于**凸规划(Convex Programming)**的方法来有效解决DDS问题,并设计了精确和近似算法,这些算法能够在大规模数据集上实现显着的性能提升。

问题定义
DDS问题的目标是在一个给定的有向图中找到一个子图,使其密度在所有子图中是最高的。具体来说,密度是指从一组顶点集 SSS 到另一组顶点集 TTT 的边的数量与这两组顶点数量的乘积的平方根之比。这个密度的计算涉及顶点和边的数量之间的非线性关係,这使得问题的求解具有挑战性。
现有方法的挑战
目前已有的DDS解决方案主要分为两类:基于最大流的精确算法和基于启发式或近似技术的近似算法。然而,这些方法在处理大规模数据集时面临着不同的挑战:
- 精确算法:这些算法通常需要大量的计算资源,特别是在处理包含大量顶点和边的图时,其计算时间非常长,无法满足实际应用的需求。
- 近似算法:儘管这些算法在效率上有所提升,但它们通常缺乏灵活性,无法提供可调的近似保证,这意味着在某些情况下,结果的质量可能难以控制。
作者的思路
1. 问题的重新表述
第一步是将DDS问题转化为一个可以用凸规划技术处理的形式。具体而言,作者提出了一个基于线性规划(Linear Programming, LP)的公式来重述DDS问题。这种转化允许使用已知的优化技术来求解该问题。
2. 使用对偶理论的创新
在转化为线性规划后,作者利用对偶理论来提高算法的效率。通过解对偶问题,作者能够推断原问题的解,这样做的好处是对偶问题通常比原问题更容易解,并且可以揭示一些有用的结构特性。

3. 分治策略的应用
为了应对大规模图数据,作者採用了分治策略。通过将问题拆分为更小的子问题来减少计算量,然后逐步解决这些子问题,最终合併结果以得到全局解。

算法设计
1. 精确算法(CP-Exact)
作者设计了CP-Exact精确算法。该算法利用分治策略和对偶理论来高效地求解线性规划问题。它首先通过分治策略减少需要解的线性规划问题的数量,然后使用Frank-Wolfe算法(一种迭代优化技术)来解对偶问题,最终得到精确的DDS解。
2. 近似算法(CP-Approx)
除了精确算法,作者还设计了CP-Approx近似算法。这个算法通过利用对偶问题中的**鸿沟(duality gap)**进行近似估算,从而在保证一定精度的前提下,大幅减少计算时间。CP-Approx特别适合处理超大规模的图数据,能在更短的时间内找到接近最佳解的近似解。
理论分析
作者详细分析了这些算法的时间複杂度和近似保证。CP-Exact算法在理论上比现有的精确算法更高效,特别是在处理大规模图时,而CP-Approx算法则提供了灵活的近似保证,允许用户在计算精度和效率之间进行调整。
实验结果
作者在八个不同类型的大规模图数据集上对其算法进行了实验测试。结果显示,CP-Exact算法在精确性和计算速度上大幅优于现有算法,尤其是在处理包含数十亿条边的图时展示了卓越的性能。CP-Approx算法在近似效果上也比现有算法快了多达五个数量级。
近似算法:

这张图片包含了两个图表,用于比较不同近似算法的效率和实际近似比率。
**上图(Figure 5)**展示了不同近似算法在多个数据集上的运行时间,以毫秒(ms)为单位。三种算法分别为: CP-Approx(橙色) Core-Approx(白色) VW-Approx(蓝色) 图中可以看出,CP-Approx算法在大多数数据集上运行时间最短,而VW-Approx算法在某些数据集上运行时间较长,甚至在部分数据集上显示出无穷大(Inf.)的结果。
**下图(Figure 6)**展示了这些算法的实际近似比率,近似比率越接近1,表示算法结果越接近真实值。三种算法的近似比率在不同数据集上的表现各有不同,总体来说CP-Approx和VW-Approx的近似比率相对稳定,而Core-Approx在某些数据集上表现出较大的波动(例如在OF数据集上)。
精确算法:

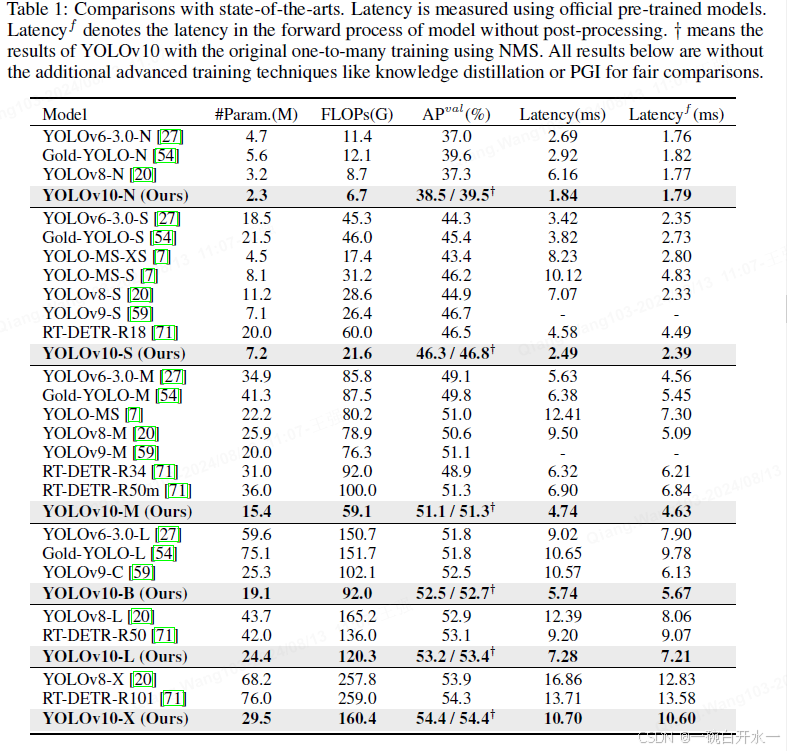
这张图片包含两个表格,展示了CP-Exact算法在不同数据集上的统计数据和运行时间比较。
-
表3(Table 3)展示了CP-Exact算法在不同数据集上的统计数据,包括:
- Datasets:数据集的名称。
- #c:表示进行计算时的c值的数量。
- Avg #iterations:平均迭代次数。
- Avg #edges:平均边数。
- Product:计算得到的结果,通常表示为某种规模的度量(例如边数的乘积)。
从表中可以看出,CP-Exact在不同数据集上的迭代次数和边数差异很大,尤其是在SK数据集上,平均边数达到407×10^7,显示了该算法处理大规模数据时的能力。
-
表4(Table 4)展示了CP-Exact和CP-Exact-ab算法的运行时间比较,包括:
- Dataset:数据集的名称。
- CP-Exact:CP-Exact算法的运行时间,以秒为单位。
- CP-Exact-ab:CP-Exact-ab算法的运行时间,以秒为单位。
- Speedup:表示CP-Exact-ab相比CP-Exact的加速比率。
表中显示,CP-Exact-ab在大多数数据集上都实现了显着的加速效果,例如在BA数据集上,加速比达到了472.71倍。然而,在某些数据集上,如SK数据集,可能无法计算或无法提供比较数据(NA)。
结论
这篇论文通过将DDS问题转化为线性规划问题,并利用对偶理论和分治策略,成功设计了高效的精确和近似算法,这些算法在大规模图数据的分析中展现出了强大的实用性和卓越的性能,为DDS问题的解决提供了重要的贡献。未来的研究可以考虑将这些方法应用于其他类型的图结构,如动态图或异质图,进一步扩展算法的适用范围。此外,还可以探索将这些技术整合到分佈式计算平台中,以处理更大规模的数据集。同时,研究如何进一步优化算法的性能,特别是在近似保证和计算效率之间找到更好的平衡,也是未来值得探索的重要方向。
论文地址:https://dl.acm.org/doi/abs/10.1145/3514221.3517837








![[240812] X-CMD 发布 v0.4.5:更新 gtb、cd、chat、hashdir 模块功能](https://i-blog.csdnimg.cn/direct/85ffa4e961ab46c497584dd0f5099658.png#pic_center)