大语言模型是当前最受关注的研究热点,基于其生成和理解能力,对现有领域在提升性能和效果上做更多尝试。分享一篇发表于2024年ICSE会议的论文Fuzz4All,它组合多个大语言模型以非常轻量且黑盒的方式,实现了一种跨语言和软件的通用模糊测试。
论文摘要
模拟测试在发现各种软件系统中的错误和漏洞方面取得了巨大成功,尤其是针对以编程语言或形式语言作为输入的被测系统(System Under Test,SUTs),例如编译器、运行时引擎、约束求解器和动态链接库等。现有的多种模糊测试工具通常只运行在特定语言上,无法直接应用于其他语言甚至同一语言的其他版本,且在进行模糊测试时也仅能发现特定功能的错误。
本文介绍了一种名为 Fuzz4All 的模糊测试工具,可以针对不同的语言及其特性进行通用的模糊测试。Fuzz4All 的核心思想是利用大语言模型作为输入生成和变异的引擎,使得其能够为任何相关语言提供多样化且真实的输入。为实现这一目标,论文提出了一种自动提示词技术,以及大语言模型驱动的模糊测试循环,可以迭代地更新提示词以创建新的输入。
作者在9个系统上测试了 Fuzz4All,其中包括了6种不同的语言(C、C++、Go、SMT2、Java 和 Python)作为输入,实验结果表明论文提出的通用模糊测试工具,相比于特定语言的模糊测试工具,具有更高的覆盖率。在广泛使用的系统中发现了98个错误,例如 GCC、Clang、Z3、CVC5、OpenJDK 和 Qiskit 量子计算平台,其中64个为以前未知的错误。
1 背景介绍
传统的模糊测试工具被分为基于生成的和基于变异的,其中基于生成的模糊测试工具旨在根据预定义的语法合成完整的代码片段,基于变异的模糊测试工具在高质量的种子输入上执行多种变异操作。当前的模糊测试工具都面临如下几个限制和挑战:
- 挑战1:与目标系统和语言的紧耦合。传统的模糊测试工具,一般针对特定语言的代码或者特殊系统而开发,无法直接跨语言或跨系统使用。
- 挑战2:缺少对系统更新的支持。实际系统或软件经常会进行更新迭代,而传统的模糊测试工具一般更适用于指定版本的系统和语言。
- 挑战3:有限的输入生成能力。不论是基于生成的还是基于变异的模糊测试工具,其产生的输入很难覆盖到更大的输入空间。
本文提出的Fuzz4All利用大语言模型作为输入生成和变异的引擎,利用模型预训练提供的大量知识,来帮助模糊测试过程产生覆盖更广的输入。主要贡献包括:
- 通用化模糊测试,可同时支持多种不同的语言和系统进行模糊测试。
- 提示词自动生成,通过蒸馏用户提供的内容自动产生合适的提示词。
- 模型驱动的循环,通过设计算法持续且循环生成新的模糊测试用例。
- 实际使用的效果,交叉在6种语言和9个软件上验证了这套系统能力。
2 Fuzz4All 方法
Fuzz4All 首先输入任意的,描述执行模糊测试任务的【用户输入】,例如被测系统的文档、示例代码、或使用手册。这类用户输入通常十分的冗长,且仅部分相关,因此需要通过蒸馏提纯以获取更加精确的信息,再基于精确的信息来构造多样化的程序输入,循环执行模糊测试。图1展示了该方法的基本流程。

在 Autoprompting 阶段,使用蒸馏大模型随机选取多个不同的候选提示词,每个候选的提示词通过生成大模型输出代码片段,Fuzz4All根据这些代码片段的质量选取最合适的提示词。
在 Fuzzing Loop 阶段,Fuzz4All持续地随机选取从生成大模型输出的代码片段,从中获得一个作为示例,应用生成策略如新产生、变异、语义等价再指导生成大模型输出新的代码片段,循环往复地利用产生的代码片段进行模糊测试,检查被测系统触发的崩溃。
Fuzz4All 使用 GPT-4 作为蒸馏大模型,StarCoder 作为生成大模型。
2.1 自动化提示词
用户输入可能包含关于被测系统的技术文档、示例代码、使用手册等,大模型可以直接使用这些内容来产生蒸馏提纯后的输入提示词,用于后续的模糊测试。

上述算法描述了 Fuzz4All 自动化生成提示词的过程,首先使用贪心策略生成一个候选提示词,再通过设置较高的温度来随机采样选取多个候选提示词, M D \mathcal{M}_\mathcal{D} MD 即蒸馏大模型。
下一步,Fuzz4All 在所有候选提示词中,计算得分来选取表现最好的作为模糊测试的输入提示词,论文中将候选集合的大小设置为30一批次。得分函数计算由该候选提示词产生的多个代码片段,在被测系统中成功验证的比率,比率越高则该候选提示词的得分越高, M G \mathcal{M}_\mathcal{G} MG 即生成大模型。
2.2 模糊测试循环
给定输入提示词,模糊测试循环可以利用生成大模型,迭代地产生程序输入。为了实现多样化,同时喂给大模型代码示例和生成指令,结合输入提示词以获取不同的程序输入。

上述算法描述了 Fuzz4All 执行模糊测试的过程,算法随机选取一个由输入提示词在生成大模型中产生的程序输入作为代码示例,再随机选取一个指令策略,结合输入提示词和代码示例一起喂给生成大模型,产生新的程序输入。
该过程循环直到满足时间条件,生成大模型每轮产生的代码片段都会随机采样给到下一轮作为输入,以尽可能地多样化模型输出。模糊测试产生的程序崩溃信息会被收集下来,最终返回进行分析。

上图列出了三种指令策略的对应内容和喂给大模型产生的代码片段示例,这些变异和新生成的代码片段将输入给被测系统进行模糊测试,在算法中使用 O r a c l e \mathrm{Oracle} Oracle 抽象表示检查被测系统的行为,从而发现漏洞(论文中使用段错误和内部断言错误来检查被测系统的崩溃)。
3 实验设计和效果
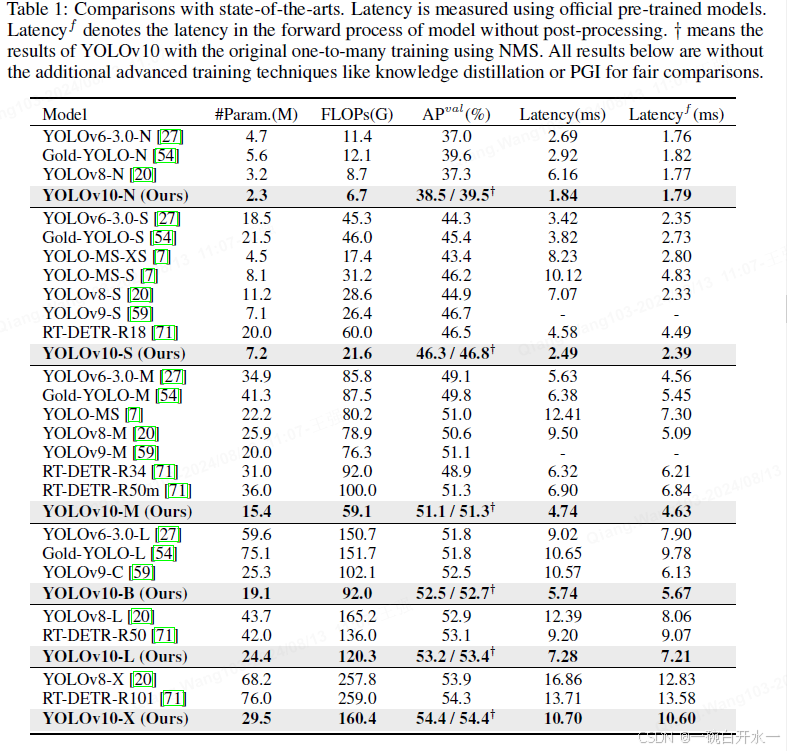
整体上看,思路是很简单的,大语言模型和模糊测试基本都是黑盒,进行巧妙的组合衔接,以期达到想要的效果。其中,最重要的部分就是实验,模糊测试的一个普遍目标函数是提高覆盖率,越高的覆盖率就越有几率碰撞出程序漏洞。Fuzz4All 选取了 6 种编程语言,对应 9 编译器作为被测系统,并分别使用了针对该被测系统的传统模糊测试工具做基线比较实验,如下表所示。

那么,实验需要评估以下几个研究问题:
- Fuzz4All 与现有的模糊测试工具相比如何?
- Fuzz4All 在有针对性的模糊测试效果如何?
- Fuzz4All 不同组件对它的效果有多大贡献?
- Fuzz4All 发现了哪些真实世界的软件漏洞?
3.1 与现有模糊测试工具比较
评价一个模糊测试工具,一个普遍的指标即代码或者分支覆盖率,覆盖率越高则探索的程序状态空间越多,发现更深层次漏洞的可能性也越大。

论文给出了对不同目标语言在对应基线工具上的实验对比,如上图所示。# programs 表示产生的独立代码片段,即模糊测试输入,的数量,% valid 表示在这些输入中通过被测系统验证的比例,Coverage 表示由模糊测试工具检查出的代码命中数量。
可以看到,Fuzz4All 产生了较少的代码片段,且这些代码片段通过被测系统的验证比率较低,获得了更高的覆盖率。
3.2 特定模糊测试目标的效果
评估对某个语言特性进行模糊测试的效果,以C语言为例,论文分别列举了typedef,union和goto三个关键字。结果给出了在不同关键字作为用户输入指定时,模糊测试的代码覆盖数量,以及对其他关键字相应的命中率。

举个例子,当针对typedef关键字作为测试目标时,产生的代码片段集合中,命中typedef关键字有83.11%,对应的命中union关键字有10.80%,而命中goto关键字只有0.22%。
通过命中率,也可以看出关键字之间typedef和union具有一定相关性,而goto与前两个关键字基本无关。关于其他语言的实验效果和观察细节可以翻阅原论文。
3.3 消融实验研究
Fuzz4All 主要靠自动化提示词和模糊测试循环两个关键组件构成,还是以C语言为例,比较系统自身在不同组件配合情况下,对被测系统的代码覆盖数量和通过被测系统验证的有效率。

其中,控制变量的含义如下。在自动化提示词中,no input表示不提供任何初始提示词,即不应用该模块;raw prompt表示直接使用用户提供的输入作为提示词,即蒸馏大模型未生效;autoprompt表示利用自动化提示词组件生成初始提示词。
在模糊测试循环中,w/o example表示禁用算法2中第6行example的采样操作,即每次都使用相同的初始化提示词;w/ example表示禁用算法2中第7行instruction的采样操作,即每次都使用产生新代码这种指令;FUZZ4ALL表示应用所有策略。
可以看到,每个组件都对Fuzz4All有一定的贡献,尤其是蒸馏大模型的筛选和初始化提示词的更新。目标是要达到更多的在被测系统中的代码覆盖数量,以及更低的模糊测试输入中的验证有效率。更多实验细节请翻阅原始论文。
3.4 真实漏洞发现
作者列出了所设计的通用模糊测试工具发现的错误实例,依旧以C语言为例,下图分别展示了GCC和Clang两款编译器软件的错误,一个是内部编译错误,另一个是段错误。

可以看到,这些代码的写法都比较隐晦,但也符合语法。具体这种漏洞能造成多大的影响以及如何利用,那就得依靠资深的渗透测试工程师的智慧了。
学习笔记
模糊测试的本质其实是在探索输入空间,尤其是非常规的输入能极大提高模糊测试的效果,大模型的泛化能力甚至是幻觉对于模糊测试而言都有很正向的意义。目前这部分的工作还处于较为粗糙的阶段,还有很多领域和技巧有待发掘,个人觉得是个很好的研究方向。最后,附上文献引用和DOI链接:
Xia C S, Paltenghi M, Le Tian J, et al. Fuzz4all: Universal fuzzing with large language models[C]//Proceedings of the IEEE/ACM 46th International Conference on Software Engineering. 2024: 1-13.
https://doi.org/10.1145/3597503.3639121

![[240812] X-CMD 发布 v0.4.5:更新 gtb、cd、chat、hashdir 模块功能](https://i-blog.csdnimg.cn/direct/85ffa4e961ab46c497584dd0f5099658.png#pic_center)