我们写的SQL语句,会经过一个优化器 (Catalyst),转化为 RDD,交给集群执行。

而Catalyst在整个Spark 生态中的地位也是至关重要的。

SQL到RDD中间经过了一个Catalyst,它就是Spark SQL的核心,是针对Spark SQL语句执行过程中的查询优化框架,基于 Scala 函数式编程结构。
RDD的运行流程:RDD-> DAGScheduler -> TaskScheduler -> worker,任务会按照编写的代码运行,代码运行效率依赖于开发者的优化,开发者会在很大程度上影响运行效率。而SparkSQL的Dataset和SQL并不是直接生成计划交给集群执行,而是经过Catalyst 的优化器,这个优化器能够自动帮助开发者优化代码。
我们要了解Spark SQL的执行流程,那么理解 Catalyst 的工作流程是非常有必要的。
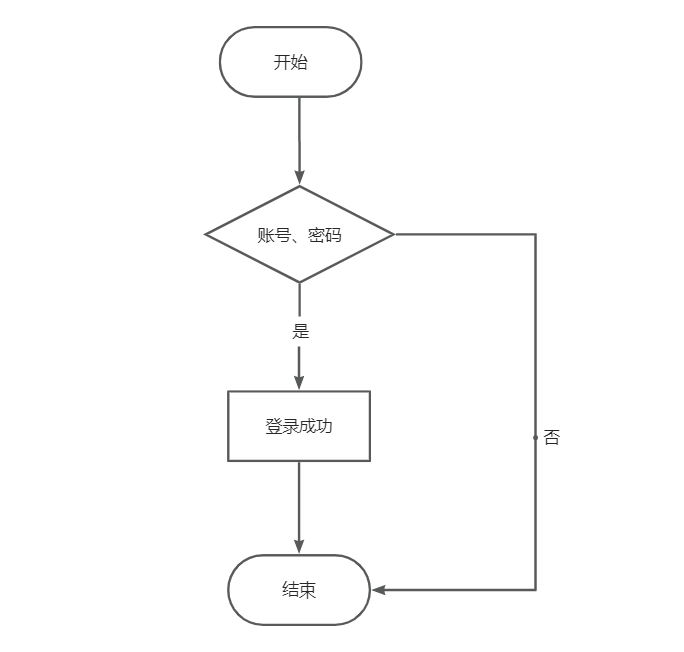
Catalyst 优化器工作流程图:

1、Parser 模块: 将SparkSql字符串解析为一个抽象语法树/AST。Parser模块目前都是使用第三方类库antlr 进行实现的。在这个过程中,会判断SQL语句是否符合规范,比如 select from where 等这些关键字是否写对。

2、Analyzer 模块: 该模块会遍历整个AST,并对AST上的每个节点进行数据类型绑定以及函数绑定,然后根据元数据信息 Catalog 对数据表中的字段进行解析。此过程就会判断SQL 语句的表名,字段名是否真的在元数据库里存在。元数据信息主要包括两部分:表的Scheme和基本函数信息。表的Scheme:包括表的基本定义(列名、数据类型)、表的数据格式(Json、Text)、表的物理位置等。基本函数: 主要指类信息。

3、Optimizer模块: 主要分为 RBO和CBO两种优化策略,其中 RBO(Rule-BasedOptimizer)是基于规则优化,CBO (Cost-Based Optimizer)是基于代价优化。常见的规则有:
i、谓词下推 Predicate Pushdown: 将过滤操作下推到join之前进行,之后再进行join 的时候,数据量显著减少,join 耗时降低。

比如:
select *
from table1 a
join table2 b
on a.id=b.id
where a.age>20 and b.cid=1
上面的语句会自动优化为如下所示:
select *
from(select * from table1 where age>20) al
join(select * from table2 where cid=1) b
on a.id=b.id
即在子查询阶段就提前将数据进行过滤,后期join的shuffle数据量就大大减少。
ii、列值裁剪 Column Pruning: 在谓词下推后,可以把表中没有用到的列裁剪掉,这一优化一方面大幅度减少了网络、内存的消耗,另一方面对于列式存储来说大大提高了扫描效率。
select a.name, a.age, b.cid
from(select * from table1 where age>20) a
join(select * from table2 where cid=1) b
on a.id=b.id
上面的语句会自动优化如下所示:
select a.name a.age, b.cid
from(select name,age,id from table1 where age>20) a
join(select id,cid from table2 where cid=1) b
on a.id=b.id
就是提前将需要的列查询出来,其他不需要的列裁剪掉。
iii、常量累加 Constant Folding: 比如计算x+(100+80)->x+180,虽然是一个很小的改动,但是意义巨大。如果没有进行优化的话,每一条结果都需要执行一次100+80的操作,然后再与结果相加。优化后就不需要再次执行100+80操作。

select 1+1 as id from table1
上面的语句会自动优化如下所示:
select 2 as id from table1
就是会提前将1+1计算成2,再赋给 id 列的每行,不用每次都计算一次1+1。
4、SparkPlanner模块: 将优化后的逻辑执行计划(OptimizedLogicalPlan)转换成physical plan (物理计划),也就是Spark 可以真正执行的计划。比如join 算子,Spark根据不同场景为该算子制定了不同的算法策略,有 BroadcastHashJoin、ShuffleHashJoin 以及 SortMergejoin 等,物理执行计划实际上就是在这些具体实现中挑选一个耗时最小的算法实现。 具体怎么挑选,下面简单说下:
SparkPlanner 对优化后的逻辑计划进行转换,是生成了多个可以执行的物理计划Physical Plan;接着CBO(基于代价优化)优化策略会根据 Cost Model 算出每个Physical Plan 的代价,并选取代价最小的 Physical Plan 作为最终的 Physical Plan。
CostModel 模块: 主要根据过去的性能统计数据,选择最佳的物理执行计划。这个过程的优化就是 CBO(基于代价优化)
备注:以上2、3、4步骤合起来,就是 Catalyst 优化器
5、执行物理计划: 最后依据最优的物理执行计划生成java字节码将SQL转化为 DAG以RDD形式进行操作。
文章为涤生大数据课程笔记