基础任务
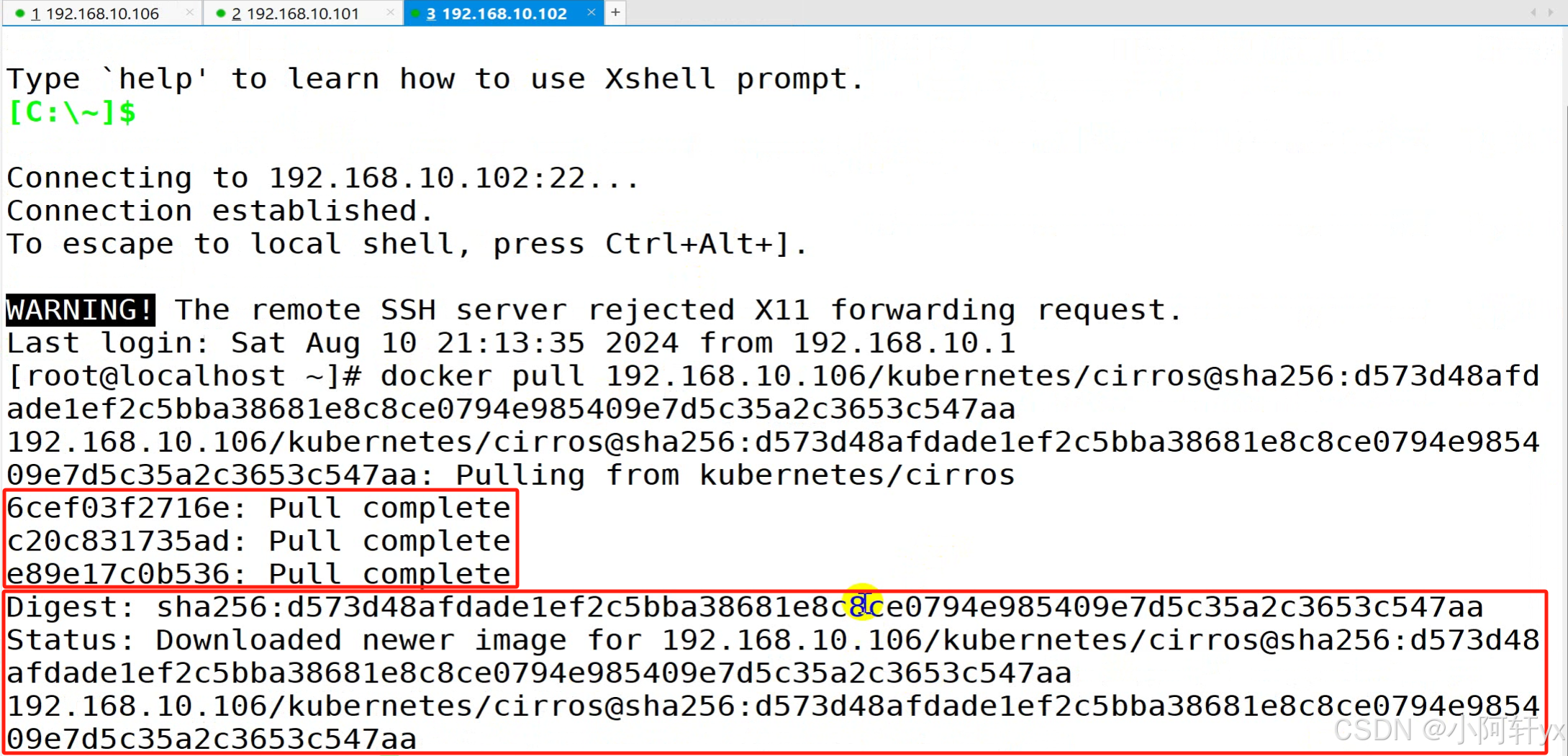
使用 Cli Demo 完成 InternLM2-Chat-1.8B 模型的部署,并生成 300 字小故事,记录复现过程并截图。

尝试很多方法无解后在网页端重新输入:

import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
'''
使用了Transformer模型和预训练的InternLM模型,用于与用户进行自然语言对话。它使用了一个名为model_name_or_path的路径来加载模型,并使用AutoTokenizer和AutoModelForCausalLM来处理输入的文本。在每次对话中,它会从模型中获取用户输入的文本,并使用stream_chat方法进行自然语言处理,并打印出处理后的响应。这段代码中,messages是一个包含两个元素的列表,第一个元素是系统提示,第二个元素是对话历史记录。在每次对话中,它会从用户输入中提取响应,并打印出响应的一部分。需要注意的是,这段代码中使用了trust_remote_code参数来确保模型可以在远程代码环境中正常工作,并且使用了device_map参数来指定模型在GPU上的设备。
'''
model_name_or_path = "/root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b"
# 从预训练的模型中加载模型,并设置信任远程代码。
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True, device_map='cuda:0')
# 从预训练的模型中加载模型,并设置信任远程代码。
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='cuda:0')
# 将模型设置为在评估模式下运行。
model = model.eval()system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""messages = [(system_prompt, '')]print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")while True:# input_text:用户输入的文本。# messages:对话历史记录。input_text = input("\nUser >>> ")input_text = input_text.replace(' ', '')if input_text == "exit":breaklength = 0# 使用模型进行自然语言处理,并获取用户输入的响应。for response, _ in model.stream_chat(tokenizer, input_text, messages):# 处理后的响应。if response is not None:# length:响应中包含的字符数。# flush=True:在打印响应时,将响应输出到控制台,而不是清空输出缓冲区。print(response[length:], flush=True, end="")length = len(response)

加入了一些注释:
# isort: skip_file
import copy
import warnings
from dataclasses import asdict, dataclass
from typing import Callable, List, Optionalimport streamlit as st
import torch
from torch import nn
from transformers.generation.utils import (LogitsProcessorList,StoppingCriteriaList)
from transformers.utils import loggingfrom transformers import AutoTokenizer, AutoModelForCausalLM # isort: skiplogger = logging.get_logger(__name__)@dataclass
class GenerationConfig:# this config is used for chat to provide more diversitymax_length: int = 32768top_p: float = 0.8temperature: float = 0.8do_sample: bool = Truerepetition_penalty: float = 1.005'''
- model: 使用Transformers库加载的预训练模型。
- tokenizer: 对应于模型的分词器。
- prompt: 用于生成文本的初始提示。
- generation_config: 生成配置,包括最大长度、是否采样等设置。
- logits_processor: 用于处理模型输出的logits。logits_processor 是一个在代码中使用的变量,它是一个列表,
包含了多个 LogitsProcessor 对象。这些对象用于处理模型输出的 logits,以便在文本生成过程中进行特定的调整,
比如缩放、截断或者应用其他转换。在代码中,logits_processor 被用来控制如何从模型的输出中提取概率分布,进而决定下一个生成token的概率。
- stopping_criteria: 用于确定何时停止生成的标准。
- prefix_allowed_tokens_fn: 定义了哪些前缀标记被允许。
- additional_eos_token_id: 额外的结束符ID。
- 过程:函数首先对输入提示进行分词,并将结果转换为PyTorch张量,然后将其移动到GPU上。接下来,函数检查是否有默认的最大长度设置
,并更新generation_config以反映这一点。函数设置了生成参数,包括logits处理器和停止标准,如果没有提供的话。
然后,函数使用模型准备输入,进行前向传递以获取下一个token。接下来,函数处理分布,采样下一个token,并更新生成的ID、
模型输入和长度。函数生成响应,并在每个句子完成或超过最大长度时停止。
最后,函数返回一个生成器,允许用户迭代生成的响应。这段代码是一个交互式文本生成器的核心部分,它允许用户通过提供初始提示和配置参数来生成连贯的文本。
'''# torch.inference_mode():这是一个PyTorch函数,用于启用推理模式,这意味着在推理过程中会关闭某些功能,如梯度计算,以提高性能。
@torch.inference_mode()
def generate_interactive(model,tokenizer,prompt,generation_config: Optional[GenerationConfig] = None,logits_processor: Optional[LogitsProcessorList] = None,stopping_criteria: Optional[StoppingCriteriaList] = None,prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor],List[int]]] = None,additional_eos_token_id: Optional[int] = None,**kwargs,
):# tokenizer([prompt], padding=True, return_tensors='pt'):这是Hugging Face Transformers库中的函数,用于对输入文本进行分词,并将结果转换为PyTorch张量。inputs = tokenizer([prompt], padding=True, return_tensors='pt')input_length = len(inputs['input_ids'][0])for k, v in inputs.items():inputs[k] = v.cuda()input_ids = inputs['input_ids']_, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]if generation_config is None:# model.generation_config:这是Transformers库中的模型类的一个属性,用于获取模型的生成配置,包括最大长度、是否采样等设置generation_config = model.generation_configgeneration_config = copy.deepcopy(generation_config)model_kwargs = generation_config.update(**kwargs)bos_token_id, eos_token_id = ( # noqa: F841 # pylint: disable=W0612generation_config.bos_token_id,generation_config.eos_token_id,)if isinstance(eos_token_id, int):eos_token_id = [eos_token_id]if additional_eos_token_id is not None:eos_token_id.append(additional_eos_token_id)has_default_max_length = kwargs.get('max_length') is None and generation_config.max_length is not Noneif has_default_max_length and generation_config.max_new_tokens is None:warnings.warn(f"Using 'max_length''s default \({repr(generation_config.max_length)}) \to control the generation length. "'This behaviour is deprecated and will be removed from the \config in v5 of Transformers -- we'' recommend using `max_new_tokens` to control the maximum \length of the generation.',UserWarning,)elif generation_config.max_new_tokens is not None:generation_config.max_length = generation_config.max_new_tokens + \input_ids_seq_lengthif not has_default_max_length:logger.warn( # pylint: disable=W4902f"Both 'max_new_tokens' (={generation_config.max_new_tokens}) "f"and 'max_length'(={generation_config.max_length}) seem to ""have been set. 'max_new_tokens' will take precedence. "'Please refer to the documentation for more information. ''(https://huggingface.co/docs/transformers/main/''en/main_classes/text_generation)',UserWarning,)if input_ids_seq_length >= generation_config.max_length:input_ids_string = 'input_ids'logger.warning(f'Input length of {input_ids_string} is {input_ids_seq_length}, 'f"but 'max_length' is set to {generation_config.max_length}. "'This can lead to unexpected behavior. You should consider'" increasing 'max_new_tokens'.")# 2. Set generation parameters if not already definedlogits_processor = logits_processor if logits_processor is not None \else LogitsProcessorList()stopping_criteria = stopping_criteria if stopping_criteria is not None \else StoppingCriteriaList()# 是Transformers库中的一个私有函数(以单下划线开头),用于获取模型的自定义logits处理器。logits_processor = model._get_logits_processor(generation_config=generation_config,input_ids_seq_length=input_ids_seq_length,encoder_input_ids=input_ids,prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,logits_processor=logits_processor,)# 用于获取模型的自定义停止标准。stopping_criteria = model._get_stopping_criteria(generation_config=generation_config,stopping_criteria=stopping_criteria)# 是Transformers库中的一个私有函数(以单下划线开头),用于获取模型的自定义logits扭曲器。logits_warper 是用于在文本生成时对模型输出的logits进行预处理和调整的工具,它帮助模型生成更加合理和连贯的文本。# 用于获取模型的自定义logits扭曲器(logits_warper)的作用是在文本生成过程中对模型输出的logits进行进一步的调整,以便影响生成文本的内容。在自然语言处理任务中,模型的原始输出通常是一个未归一化的概率分布,这个分布可能包含非常大的数值,这会导致在生成文本时出现不稳定的行为。为了使生成过程更加可控和稳定,logits_warper 可以对logits应用一些变换,比如将它们映射到一个更小的范围内,或者应用非线性函数来改变它们的形状。# 在代码中,logits_warper 是通过调用模型的一个私有方法 _get_logits_warper 来获取的。这个方法会根据当前的生成配置(generation_config)和输入序列的长度(input_ids_seq_length)来创建一个适当的扭曲器对象。然后,这个扭曲器对象会在生成过程中被用来处理模型的输出logits,确保生成的文本既符合语法规则,又具有一定的多样性。logits_warper = model._get_logits_warper(generation_config)unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)scores = Nonewhile True:model_inputs = model.prepare_inputs_for_generation(input_ids, **model_kwargs)# forward pass to get next tokenoutputs = model(**model_inputs,return_dict=True,output_attentions=False,output_hidden_states=False,)next_token_logits = outputs.logits[:, -1, :]# pre-process distributionnext_token_scores = logits_processor(input_ids, next_token_logits)next_token_scores = logits_warper(input_ids, next_token_scores)# sampleprobs = nn.functional.softmax(next_token_scores, dim=-1)if generation_config.do_sample:# 用于从输入概率分布中采样指定数量的样本。next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)else:next_tokens = torch.argmax(probs, dim=-1)# update generated ids, model inputs, and length for next stepinput_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)model_kwargs = model._update_model_kwargs_for_generation(outputs, model_kwargs, is_encoder_decoder=False)unfinished_sequences = unfinished_sequences.mul((min(next_tokens != i for i in eos_token_id)).long())output_token_ids = input_ids[0].cpu().tolist()output_token_ids = output_token_ids[input_length:]for each_eos_token_id in eos_token_id:if output_token_ids[-1] == each_eos_token_id:output_token_ids = output_token_ids[:-1]# 这是Hugging Face Transformers库中的函数,用于将分词后的ID序列解码为文本字符串。response = tokenizer.decode(output_token_ids)yield response# stop when each sentence is finished# or if we exceed the maximum lengthif unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):breakdef on_btn_click():del st.session_state.messages@st.cache_resource
def load_model():model = (AutoModelForCausalLM.from_pretrained('/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b',trust_remote_code=True).to(torch.bfloat16).cuda())tokenizer = AutoTokenizer.from_pretrained('/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b',trust_remote_code=True)return model, tokenizerdef prepare_generation_config():with st.sidebar:max_length = st.slider('Max Length',min_value=8,max_value=32768,value=32768)'''在自然语言处理任务中,Top P参数是指在排序模型中,选择前P个预测结果作为最终预测结果。在训练模型时,通常使用Top P参数来控制模型在训练过程中的选择。具体来说,Top P参数用于控制模型在训练过程中选择哪些预测结果作为最终预测结果。如果Top P参数设置得比较小,则模型会更多地选择预测结果,以提高模型的准确性;如果Top P参数设置得比较大,则模型会更多地选择预测结果,以避免过拟合。例如,在文本分类任务中,Top P参数通常用于选择前P个预测结果作为最终分类结果。'''top_p = st.slider('Top P', 0.0, 1.0, 0.8, step=0.01)temperature = st.slider('Temperature', 0.0, 1.0, 0.7, step=0.01)st.button('Clear Chat History', on_click=on_btn_click)generation_config = GenerationConfig(max_length=max_length,top_p=top_p,temperature=temperature)return generation_configuser_prompt = '<|im_start|>user\n{user}<|im_end|>\n'
robot_prompt = '<|im_start|>assistant\n{robot}<|im_end|>\n'
cur_query_prompt = '<|im_start|>user\n{user}<|im_end|>\n\<|im_start|>assistant\n'def combine_history(prompt):messages = st.session_state.messagesmeta_instruction = ('You are InternLM (书生·浦语), a helpful, honest, ''and harmless AI assistant developed by Shanghai ''AI Laboratory (上海人工智能实验室).')total_prompt = f'<s><|im_start|>system\n{meta_instruction}<|im_end|>\n'for message in messages:cur_content = message['content']if message['role'] == 'user':cur_prompt = user_prompt.format(user=cur_content)elif message['role'] == 'robot':cur_prompt = robot_prompt.format(robot=cur_content)else:raise RuntimeErrortotal_prompt += cur_prompttotal_prompt = total_prompt + cur_query_prompt.format(user=prompt)return total_promptdef main():# torch.cuda.empty_cache()print('load model begin.')model, tokenizer = load_model()print('load model end.')st.title('InternLM2-Chat-1.8B')generation_config = prepare_generation_config()# Initialize chat history# 通过遍历st.session_state.messages列表,并使用st.chat_message()函数显示历史消息,包括消息的角色和头像,以及消息内容。if 'messages' not in st.session_state:st.session_state.messages = []# Display chat messages from history on app rerunfor message in st.session_state.messages:with st.chat_message(message['role'], avatar=message.get('avatar')):st.markdown(message['content'])# Accept user inputif prompt := st.chat_input('What is up?'):# Display user message in chat message containerwith st.chat_message('user'):st.markdown(prompt)real_prompt = combine_history(prompt)# Add user message to chat historyst.session_state.messages.append({'role': 'user','content': prompt,})# st.chat_message('robot')上下文管理器显示机器人回复的占位符。with st.chat_message('robot'):message_placeholder = st.empty()for cur_response in generate_interactive(model=model,tokenizer=tokenizer,prompt=real_prompt,additional_eos_token_id=92542,**asdict(generation_config),):# Display robot response in chat message containermessage_placeholder.markdown(cur_response + '▌')message_placeholder.markdown(cur_response)# Add robot response to chat historyst.session_state.messages.append({'role': 'robot','content': cur_response, # pylint: disable=undefined-loop-variable})torch.cuda.empty_cache()if __name__ == '__main__':main()
进阶任务
使用 LMDeploy 完成 InternLM-XComposer2-VL-1.8B 的部署,并完成一次图文理解对话,记录复现过程并截图。

自己装的环境就是坑比较大,报错:
2024-08-14 17:51:41,494 - lmdeploy - INFO - Register stream callback for 0
[TM][INFO] [forward] Enqueue requests
[TM][INFO] [forward] Wait for requests to complete ...
[TM][INFO] [ProcessInferRequests] Request for 0 received.
[TM][INFO] ------------------------- step = 1370 -------------------------
[TM][INFO] [Forward] [0, 1), dc_bsz = 0, pf_bsz = 1, n_tok = 1371, max_q = 1371, max_k = 1371
Aborted (core dumped)
经过排查,换成再小的图片也不行。
参考:https://github.com/InternLM/Tutorial/blob/camp3/docs/L1/Demo/easy_readme.md
用这个环境比较好
我导出了icamp3_demo的环境配置,下次在其他Linux环境部署可以尝试导入conda env create -f environment.yml:
name: /root/share/pre_envs/icamp3_demo
channels:- pytorch- nvidia- defaults
dependencies:- _libgcc_mutex=0.1=main- _openmp_mutex=5.1=1_gnu- blas=1.0=mkl- brotli-python=1.0.9=py310h6a678d5_8- bzip2=1.0.8=h5eee18b_6- ca-certificates=2024.7.2=h06a4308_0- certifi=2024.7.4=py310h06a4308_0- charset-normalizer=3.3.2=pyhd3eb1b0_0- cuda-cudart=12.1.105=0- cuda-cupti=12.1.105=0- cuda-libraries=12.1.0=0- cuda-nvrtc=12.1.105=0- cuda-nvtx=12.1.105=0- cuda-opencl=12.5.39=0- cuda-runtime=12.1.0=0- cuda-version=12.5=3- ffmpeg=4.3=hf484d3e_0- filelock=3.13.1=py310h06a4308_0- freetype=2.12.1=h4a9f257_0- gmp=6.2.1=h295c915_3- gmpy2=2.1.2=py310heeb90bb_0- gnutls=3.6.15=he1e5248_0- idna=3.7=py310h06a4308_0- intel-openmp=2023.1.0=hdb19cb5_46306- jinja2=3.1.4=py310h06a4308_0- jpeg=9e=h5eee18b_2- lame=3.100=h7b6447c_0- lcms2=2.12=h3be6417_0- ld_impl_linux-64=2.38=h1181459_1- lerc=3.0=h295c915_0- libcublas=12.1.0.26=0- libcufft=11.0.2.4=0- libcufile=1.10.1.7=0- libcurand=10.3.6.82=0- libcusolver=11.4.4.55=0- libcusparse=12.0.2.55=0- libdeflate=1.17=h5eee18b_1- libffi=3.4.4=h6a678d5_1- libgcc-ng=11.2.0=h1234567_1- libgomp=11.2.0=h1234567_1- libiconv=1.16=h5eee18b_3- libidn2=2.3.4=h5eee18b_0- libjpeg-turbo=2.0.0=h9bf148f_0- libnpp=12.0.2.50=0- libnvjitlink=12.1.105=0- libnvjpeg=12.1.1.14=0- libpng=1.6.39=h5eee18b_0- libstdcxx-ng=11.2.0=h1234567_1- libtasn1=4.19.0=h5eee18b_0- libtiff=4.5.1=h6a678d5_0- libunistring=0.9.10=h27cfd23_0- libuuid=1.41.5=h5eee18b_0- libwebp-base=1.3.2=h5eee18b_0- llvm-openmp=14.0.6=h9e868ea_0- lz4-c=1.9.4=h6a678d5_1- markupsafe=2.1.3=py310h5eee18b_0- mkl=2023.1.0=h213fc3f_46344- mkl-service=2.4.0=py310h5eee18b_1- mkl_fft=1.3.8=py310h5eee18b_0- mkl_random=1.2.4=py310hdb19cb5_0- mpc=1.1.0=h10f8cd9_1- mpfr=4.0.2=hb69a4c5_1- mpmath=1.3.0=py310h06a4308_0- ncurses=6.4=h6a678d5_0- nettle=3.7.3=hbbd107a_1- networkx=3.3=py310h06a4308_0- numpy=1.26.4=py310h5f9d8c6_0- numpy-base=1.26.4=py310hb5e798b_0- openh264=2.1.1=h4ff587b_0- openjpeg=2.4.0=h9ca470c_2- openssl=3.0.14=h5eee18b_0- pillow=10.4.0=py310h5eee18b_0- pip=24.0=py310h06a4308_0- pysocks=1.7.1=py310h06a4308_0- python=3.10.14=h955ad1f_1- pytorch=2.1.2=py3.10_cuda12.1_cudnn8.9.2_0- pytorch-cuda=12.1=ha16c6d3_5- pytorch-mutex=1.0=cuda- pyyaml=6.0.1=py310h5eee18b_0- readline=8.2=h5eee18b_0- requests=2.32.3=py310h06a4308_0- setuptools=69.5.1=py310h06a4308_0- sqlite=3.45.3=h5eee18b_0- sympy=1.12=py310h06a4308_0- tbb=2021.8.0=hdb19cb5_0- tk=8.6.14=h39e8969_0- torchaudio=2.1.2=py310_cu121- torchtriton=2.1.0=py310- torchvision=0.16.2=py310_cu121- typing_extensions=4.11.0=py310h06a4308_0- urllib3=2.2.2=py310h06a4308_0- wheel=0.43.0=py310h06a4308_0- xz=5.4.6=h5eee18b_1- yaml=0.2.5=h7b6447c_0- zlib=1.2.13=h5eee18b_1- zstd=1.5.5=hc292b87_2- pip:- accelerate==0.33.0- addict==2.4.0- aiofiles==23.2.1- aiohttp==3.9.5- aiosignal==1.3.1- altair==5.3.0- annotated-types==0.7.0- anyio==4.4.0- async-timeout==4.0.3- attrs==23.2.0- blinker==1.8.2- cachetools==5.4.0- click==8.1.7- contourpy==1.2.1- cycler==0.12.1- datasets==2.20.0- dill==0.3.8- dnspython==2.6.1- einops==0.8.0- email-validator==2.2.0- exceptiongroup==1.2.2- fastapi==0.111.1- fastapi-cli==0.0.4- ffmpy==0.3.3- fire==0.6.0- fonttools==4.53.1- frozenlist==1.4.1- fsspec==2024.5.0- gitdb==4.0.11- gitpython==3.1.43- gradio==4.39.0- gradio-client==1.1.1- grpcio==1.65.1- h11==0.14.0- httpcore==1.0.5- httptools==0.6.1- httpx==0.27.0- huggingface-hub==0.24.3- importlib-metadata==8.2.0- importlib-resources==6.4.0- jsonschema==4.23.0- jsonschema-specifications==2023.12.1- kiwisolver==1.4.5- lmdeploy==0.5.1- markdown-it-py==3.0.0- matplotlib==3.9.1- mdurl==0.1.2- mmengine-lite==0.10.4- multidict==6.0.5- multiprocess==0.70.16- nvidia-cublas-cu12==12.5.3.2- nvidia-cuda-runtime-cu12==12.5.82- nvidia-curand-cu12==10.3.6.82- nvidia-nccl-cu12==2.22.3- orjson==3.10.6- packaging==24.1- pandas==2.2.2- peft==0.11.1- platformdirs==4.2.2- protobuf==4.25.4- psutil==6.0.0- pyarrow==17.0.0- pyarrow-hotfix==0.6- pybind11==2.13.1- pydantic==2.8.2- pydantic-core==2.20.1- pydeck==0.9.1- pydub==0.25.1- pygments==2.18.0- pynvml==11.5.3- pyparsing==3.1.2- python-dateutil==2.9.0.post0- python-dotenv==1.0.1- python-multipart==0.0.9- python-rapidjson==1.19- pytz==2024.1- referencing==0.35.1- regex==2024.7.24- rich==13.7.1- rpds-py==0.19.1- ruff==0.5.5- safetensors==0.4.3- semantic-version==2.10.0- sentencepiece==0.1.99- shellingham==1.5.4- shortuuid==1.0.13- six==1.16.0- smmap==5.0.1- sniffio==1.3.1- starlette==0.37.2- streamlit==1.37.0- tenacity==8.5.0- termcolor==2.4.0- tiktoken==0.7.0- timm==1.0.7- tokenizers==0.15.2- toml==0.10.2- tomli==2.0.1- tomlkit==0.12.0- toolz==0.12.1- tornado==6.4.1- tqdm==4.66.4- transformers==4.38.0- transformers-stream-generator==0.0.5- tritonclient==2.48.0- typer==0.12.3- tzdata==2024.1- uvicorn==0.30.3- uvloop==0.19.0- watchdog==4.0.1- watchfiles==0.22.0- websockets==11.0.3- xxhash==3.4.1- yapf==0.40.2- yarl==1.9.4- zipp==3.19.2
prefix: /root/share/pre_envs/icamp3_demo在 Linux 系统中,常将“主内存”称为核心(core),而核心映像(core image) 就是 “进程”(process)执行当时的内存内容。
当进程发生错误或收到“信号”(signal) 而终止执行时,系统会将核心映像写入一个文件,以作为调试之用,这就是所谓的核心转储(core dump)。
当在一个程序崩溃时,系统会在指定目录下生成一个core文件,我们就可以通过 core文件来对造成程序崩贵的原因进行调试定位。
使用 LMDeploy 完成 InternVL2-2B 的部署,并完成一次图文理解对话,记录复现过程并截图。

参考文档:https://github.com/InternLM/Tutorial/blob/camp3/docs/L1/Demo/easy_readme.md