1 什么是负载均衡
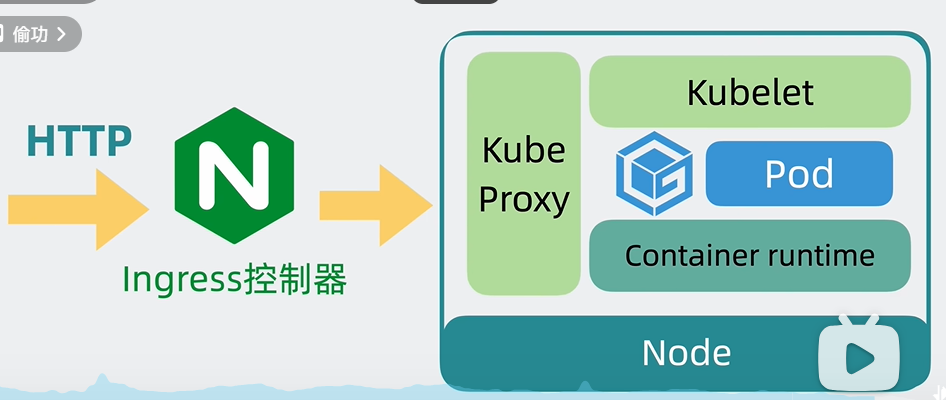
负载均衡(Load Balancing)是一种将网络请求或工作负载分散到多个服务器或计算机资源上的技术,以实现优化资源使用、提高系统吞吐量、增强数据冗余和故障容错能力、以及减少响应时间的目的。在分布式系统、云计算环境、Web服务等领域中,负载均衡是一项至关重要的技术。
负载均衡的基本原理是将进入系统的请求或数据流量按照一定的规则分配到后端的多个服务器或资源上进行处理。这些规则可以是基于请求的源IP地址、目标IP地址、端口号、协议类型、URL路径、请求内容等信息的,也可以是基于服务器当前的负载状况、响应时间、健康状况等动态信息的。
负载均衡器(Load Balancer)是实现负载均衡功能的硬件或软件设备。它可以是一个独立的物理设备,也可以是在服务器上运行的软件程序。负载均衡器负责接收来自客户端的请求,然后根据配置的负载均衡策略将请求转发给后端服务器集群中的一台或多台服务器进行处理。同时,负载均衡器还需要监控后端服务器的健康状况,确保只将请求转发给正常工作的服务器。
负载均衡可以带来以下好处:
- 提高系统吞吐量:通过并行处理请求,可以显著提高系统的处理能力,减少用户等待时间。
- 优化资源使用:根据服务器的实际负载情况动态分配请求,避免某些服务器过载而其他服务器空闲的情况。
- 增强数据冗余和故障容错能力:通过将数据分布在多个服务器上,可以提高数据的可用性和容错性,即使某些服务器出现故障,也不会影响整个系统的正常运行。
- 减少响应时间:通过减少单个服务器的负载,可以缩短请求的处理时间,提高用户体验。
常见的负载均衡算法包括轮询(Round Robin)、最少连接(Least Connections)、源地址哈希(Source Hashing)、加权轮询(Weighted Round Robin)等。这些算法各有优缺点,适用于不同的应用场景和需求。
在实际应用中,负载均衡通常与反向代理(Reverse Proxy)、内容分发网络(CDN)、微服务架构等技术结合使用,以提供更高效、可靠、可扩展的系统解决方案。
2 haproxy简介
HAProxy(High Availability Proxy)是一款由法国人Willy Tarreau开发的高性能、开源的TCP和HTTP负载均衡器。它使用C语言编写,具备高并发处理能力和丰富的功能特性,广泛应用于各种需要高负载和高可用性的Web站点和应用程序中。以下是对HAProxy的详细介绍:
2.1 基本概述
- 开发者:Willy Tarreau
- 类型:高性能的TCP和HTTP负载均衡器
- 特点:免费、快速、可靠
- 主要功能:负载均衡、健康检查、会话保持、SSL/TLS支持、HTTP重写、压缩等
2.2 主要特性
- 高性能:HAProxy采用事件驱动模型,能够处理大量并发连接,支持数以万计的并发连接,特别适合高负载的Web站点。
- 灵活性强:支持多种负载均衡算法和调度策略,如轮询、最少连接、源地址哈希等,适应不同的应用场景。
- 高可用性:通过健康检查和故障转移机制,确保服务的连续性。当后端服务器出现故障时,HAProxy会自动将其从负载均衡池中移除,并在服务器恢复后重新添加。
- 丰富的功能:支持SSL终止、HTTP重写、压缩等多种功能,提升应用的性能和安全性。
- 易于集成:HAProxy可以简单地集成到现有的架构中,同时保护Web服务器不被直接暴露在网络上。
2.3 工作原理
HAProxy的工作流程主要包括以下几个步骤:
- 客户端请求:客户端发送请求到HAProxy的前端。
- 前端处理:前端根据配置的规则(如负载均衡算法、ACL规则等)选择合适的后端。
- 后端转发:前端将请求转发到选定的后端服务器进行处理。
- 服务器响应:后端服务器处理请求并返回结果给前端。
- 返回客户端:前端将处理结果返回给客户端。
2.4 负载均衡算法
HAProxy支持多种负载均衡算法,以满足不同的需求:
- 轮询(Round Robin):将请求依次分配给每个后端服务器。
- 最少连接(Least Connections):将请求分配给当前连接数最少的服务器。
- 源地址哈希(Source Hashing):根据客户端的IP地址分配请求,确保同一客户端的请求总是分配到同一台服务器。
- 加权轮询(Weighted Round Robin):根据服务器的权重分配请求,权重高的服务器分配更多的请求。
2.5 健康检查机制
为了确保请求只被分配到正常工作的服务器,HAProxy提供了健康检查机制。健康检查可以定期检测后端服务器的状态,并根据检测结果动态调整服务器的可用性。常见的健康检查类型包括TCP连接检查、HTTP请求检查等。
2.6 应用场景
HAProxy特别适用于那些负载特大的Web站点,这些站点通常又需要会话保持或七层处理。此外,HAProxy还可以用于数据库负载均衡、API网关、微服务架构中的服务发现与负载均衡等场景。
3 配置haproxy实验环境
搭建三个红帽9镜像的虚拟机并关闭防火墙
3.1 haproxy
配置IP

3.2 webserver1

配置IP

安装nginx
![]()

3.3 webserver2

配置IP

安装nginx
![]()

4 haproxy的基本部署方法及负载均衡的实现
haproxy
安装haproxy
![]()
haproxy配置文件
![]()
4.1 配置文件结构
HAProxy的配置文件通常包含五个主要部分:
- global:参数是进程级的,通常是和操作系统相关。这些参数一般只设置一次,如果配置无误,就不需要再次进行修改。
- defaults:配置默认参数,这些参数可以被用到frontend、backend、listen组件。
- frontend:接收请求的前端虚拟节点,Frontend可以基于规则直接指定具体使用的后端backend。
- backend:后端服务集群的配置,是真实服务器,一个Backend对应一个或者多个实体服务器。
- listen:Frontend和backend的组合体。
4.2 关键配置项
1. global部分
- 日志记录:定义日志记录的地址和级别,如
log 127.0.0.1 local0 info。 - chroot:将进程的根目录更改为指定目录,提高安全性。
- 用户和用户组:指定运行HAProxy的用户和用户组。
- 最大连接数:设置HAProxy可以处理的最大连接数。
- 其他系统级配置:如
daemon使HAProxy在后台运行,stats socket定义统计信息的Unix套接字位置等。
2. defaults部分
- 日志类型:如
option httplog启用HTTP日志。 - 连接配置:设置最大连接数、连接超时时间等。
- 负载均衡算法:如
balance roundrobin设置默认负载均衡方式为轮询。 - 健康检查:配置健康检查的相关参数,如重试次数、检查间隔等。
3. frontend部分
- 绑定地址和端口:定义HAProxy监听的地址和端口,如
bind 0.0.0.0:80。 - 协议:设置处理请求的协议,如HTTP或TCP。
- ACL和过滤器:配置访问控制列表(ACL)和过滤器,以决定如何处理请求。
4. backend部分
- 服务器列表:定义后端服务器列表,包括服务器的IP地址、端口号、权重等。
- 健康检查:配置对后端服务器的健康检查,确保只有健康的服务器才能接收请求。
5. listen部分
- 组合配置:将frontend和backend的配置组合在一起,形成一个完整的监听器配置。
4.3 示例配置
以下是一个简单的haproxy配置示例:

4.4 注意事项
- 在配置HAProxy时,需要根据实际的应用场景和需求来选择合适的配置参数。
- 配置完成后,需要仔细检查配置文件是否有误,并测试HAProxy是否能够正常工作。
- 在生产环境中,建议对HAProxy进行监控和日志记录,以便及时发现和解决问题。
5 haproxy的配置参数及日志分离
5.1 haproxy的配置参数
HAProxy的全局配置(global section)是其配置文件中的重要部分,它包含了影响HAProxy进程及其操作的全局性设置。这些参数通常是进程级别的,并且与操作系统相关。以下是对HAProxy全局配置的一些详细说明:
1. 进程管理及安全相关参数
- chroot:将HAProxy的工作目录更改到指定的目录,并在放弃权限之前执行chroot()操作。这可以提升HAProxy的安全级别,但需要注意的是,指定的目录必须为空且任何用户都不能有写权限。
- daemon:使HAProxy以守护进程的方式在后台运行。这等同于命令行中的"-D"选项。
- gid 和 group:分别以指定的GID(组ID)或组名运行HAProxy。建议使用专为运行HAProxy创建的GID或组名,以减少权限风险。
- log:定义全局的日志服务器和日志级别。可以指定最多两个日志服务器,并设置日志的级别(如info、warning、error等)。
- nbproc:指定启动的HAProxy进程数。默认情况下,只启动一个进程。但在某些情况下,可能需要启动多个进程以提高性能或进行调试。
- pidfile:指定HAProxy进程的PID文件位置,该文件包含HAProxy主进程的进程ID。
- uid 和 user:分别以指定的UID(用户ID)或用户名运行HAProxy。
2. 性能调整相关参数
- maxconn:设置每个HAProxy进程所能接受的最大并发连接数。这是一个重要的性能参数,需要根据服务器的实际负载进行调整。
- ulimit-n:设置每个HAProxy进程可以打开的最大文件描述符数。默认情况下,HAProxy会自动计算这个值,但在某些情况下,可能需要手动调整以优化性能。
3. 超时时长相关参数
- timeout connect:定义HAProxy将客户端请求转发到后端服务器所等待的超时时长。
- timeout client:客户端非活动状态的超时时长。
- timeout server:客户端与服务器端建立连接后,等待服务器响应的超时时长。
- timeout http-keep-alive:定义HTTP持久连接的超时时长。
- timeout check:健康检查时的超时时长。
4. 调试相关参数
- debug:启用调试模式,提供更详细的日志信息。这通常只在调试过程中使用,不建议在生产环境中启用。
- quiet:减少日志信息的输出量,使日志更加简洁。
5. 其他参数
- stats socket:定义一个UNIX域套接字,用于通过命令行工具(如socat)与HAProxy进行交互,获取实时统计信息。
- node:定义节点的名称,这在HA场景中特别有用,当多个HAProxy进程共享同一个IP地址时。
5.2 haproxy的日志分离
打开配置日志文件
![]()
在配置文件里打开UDP协议

配置haproxy日志位置

6 proxies中的常用配置参数
6.1 前端配置(frontend)
- bind:定义前端监听的地址和端口,例如
bind 0.0.0.0:80。 - mode:设置前端运行的协议(tcp或http)。
- option httplog:启用http日志(如果前端处理的是HTTP请求)。
- acl:定义访问控制列表(ACL),用于根据特定条件路由请求,例如
acl php_web path_end .php。 - use_backend:根据ACL的匹配结果,将请求转发到指定的后端服务器组,例如
use_backend php_server if php_web。
6.2 后端配置(backend)
- mode:设置后端运行的协议(tcp或http)。
- balance:定义后端服务器的负载均衡算法,如轮询(roundrobin)、最少连接(leastconn)等。
- server:定义后端服务器的地址、端口和其他参数,例如
server web1 192.168.1.1:80 check。 - option httpchk:开启对后端服务器的健康检查,通常通过HTTP请求完成,例如
option httpchk GET /index.html。
6.3 监听配置(listen)
- bind:定义监听的地址和端口,与frontend中的bind类似。
- mode:设置监听的协议(tcp或http)。
- stats:配置监控页面的相关参数,如启用监控、设置监控页面的URL和刷新间隔等。
6.4 server配置
6.4.1 基本参数
- name:为此服务器指定一个标识名称,这个名称将出现在日志文件中,用于区分不同的后端服务器。
- address:填写后端服务器的IP地址,也支持使用可解析的主机名称。
- port:指定将连接发往后端服务器的目标端口,如果未设定,则通常使用客户端请求的端口。
6.4.2 健康检查参数
- check:启用对此服务器的TCP健康状态检查。默认情况下,HAProxy会尝试连接到后端服务器的指定端口来检查其可用性。
- inter:设置健康状态检查的时间间隔(单位为毫秒),默认为2000毫秒。
- rise:设置后端服务器从离线状态转换为正常状态需要成功检查的次数。
- fall:设置后端服务器从正常状态转换为不可用状态需要检查的失败次数。
6.4.3 其他参数
- backup:将此服务器设置为备用服务器。在负载均衡场景中,当所有正常服务器均不可用时,此备用服务器将顶替提供服务。
- maxconn:指定此服务器接受的最大并发连接数。这有助于防止单个服务器过载,影响整体服务的稳定性。
7 haproxy热更新方法
7.1 安装socat
![]()
7.2 查看haproxy帮助
![]()
7.3 查看haproxy状态
![]()
7.4 更改权重
![]()
7.5 查看servers状态

7.6 关闭一台主机
![]()

7.7 打开一台主机
![]()

7.8 haproxy多进程热处理
在配置文件里


8 haproxy中的算法
8.1 静态算法
8.1.1 static-rr
不支持运行时利用socat进行权重的动态调整(只支持0和1,不支持其它值)
不支持端服务器慢启动
其后端主机数量没有限制,相当于LVS中的 wrr

8.1.2 first
根据服务器在列表中的位置,自上而下进行调度
其只会当第一台服务器的连接数达到上限,新请求才会分配给下一台服务
其会忽略服务器的权重设置
不支持用socat进行动态修改权重,可以设置0和1,可以设置其它值但无效

8.2 动态算法
8.2.1 roundrobin
1.基于权重的轮询动态调度算法
2.支持权重的运行时调整,不同于Ivs中的rr轮训模式
3.HAProxy中的roundrobin支持慢启动(新加的服务器会逐渐增加转发数
4.其每个后端backend中最多支持4095个real server
5.支持对real server权重动态调整
6.roundrobin为默认调度算法,此算法使用广泛

8.2.2 leastconn
leastconn加权的最少连接的动态
支持权重的运行时调整和慢启动,即:根据当前连接最少的后端服务器而非权重进行优先调度(新客户端连接)
比较适合长连接的场景使用,比如:MySQL等场景。

8.3 其他算法
8.3.1 source

8.3.1.1 一致性hash
一致性哈希,当服务器的总权重发生变化时,对调度结果影响是局部的,不会引起大的变动hash(o)mod n
该hash算法是动态的,支持使用 socat等工具进行在线权重调整,支持慢启动

8.3.2 uri
基于对用户请求的URI的左半部分或整个uri做hash,再将hash结果对总权重进行取模后根据最终结果将请求转发到后端指定服务器
适用于后端是缓存服务器场景
默认是静态算法,也可以通过hash-type指定map-based和consistent,来定义使用取模法还是一致性hash

8.3.3 url_param
url_param对用户请求的ur中的 params 部分中的一个参数key对应的value值作hash计算,并由服务器总权重相除以后派发至某挑出的服务器,后端搜索同一个数据会被调度到同一个服务器,多用与电商
通常用于追踪用户,以确保来自同一个用户的请求始终发往同一个realserver如果无没key,将按roundrobin算法

8.3.4 hdr
url_param对用户请求的ur中的 params 部分中的一个参数key对应的value值作hash计算,并由服务器总权重相除以后派发至某挑出的服务器,后端搜索同一个数据会被调度到同一个服务器,多用与电商,通常用于追踪用户,以确保来自同一个用户的请求始终发往同一个realserver如果无没key,将按roundrobin算法

9 haproxy的状态页面监控
9.1 在配置文件中编辑状态页

9.2 测试

10 基于cookie的会话保持
10.1 配置

10.2 测试


11 ip透传技术
11.1 七层穿透
11.1.1 关闭nginx并下载httpd

11.1.2 测试页面
![]()
11.1.3 打开httpd
![]()
11.1.4 在配置文件中编辑
![]()

11.1.5 测试



11.2 四层穿透

11.2.1 在配置文件中编辑

11.2.2 在webserver2的nginx配置文件编辑


12 haproxy的访问控制列表
解析

12.1 ACL-name名称
12.1.1 在配置文件中编辑

12.1.2 测试

12.2 ACL-criterion匹配规范
12.2.1 hdr_end()
12.2.1.1 在配置文件中编辑

12.2.1.2 测试

12.2.2 hdr_beg()
12.2.2.1 在配置文件中编辑

12.2.2.2 测试

12.2.3 base_sub()
12.2.3.1 在配置文件中编辑

12.2.3.2 测试


12.2.4 base_reg()
12.2.4.1 在配置文件中编辑

12.2.4.2 测试

12.2.5 path_sub()
12.2.5.1 在配置文件中编辑

12.2.5.2 测试

13 利用acl做动静分离等访问控制
13.1 基于域名
13.1.1 在配置文件中编辑

13.1.2 测试

13.2 基于网段
13.2.1 在配置文件中编辑

13.2.2 测试
![]()
13.2.2 在配置文件中编辑

13.2.4 测试


![]()
13.3 基于浏览器
13.3.1 在配置文件中编辑

13.3.2 测试


13.4 动静分离
![]()
13.4.1 静态分离
13.4.1.1 打开配置文件
![]()

13.4.1.2 在配置文件中编辑

13.4.1.3 测试

13.4.2 动态分离
13.4.2.1 在配置文件中编辑

13.4.2.2 测试


14 自动义错误页面内容
14.1 创建文件
![]()
14.2 在文件里编辑

14.2 在配置文件中编辑

14.3 测试

14.4 定向到百度
14.4.1 在配置文件中编辑

14.4.2 测试

15 hapoxy的四层负载示例
15.1 webserver1
安装数据库
![]()
![]()


15.2 webserver2
与webserver1一样


15.3 haproxy安装数据库
![]()
15.4 webserver1和webserver2都做用户密码

15.5 在配置文件里编辑

15.6 测试



16 https的加密访问
16.1 可视
16.1.1 创建目录并设置证书

16.1.2 在配置文件里编辑

16.1.3 测试

16.2 全站加密
16.2.1 在配置文件里编辑

16.2.2 创建webcluster.cfg文件并配置


16.2.3 测试