如果一棵树节点过多,表明该模型可能对数据进行了过拟合。
通过降低决策树的复杂度来避免过拟合的过程称为剪枝。提过提前终止条件,实际上就是在进行一种所谓的预剪枝;另一种形式的剪枝需要使用测试集和训练集,称作后剪枝。
预剪枝
树构建算法其实对输入的参数tolS和tolN非常敏感,如果使用其他值将不容易达到这么好的效果。为了说明这一点,可以尝试:
print(createTree(myDat,ops=(0,1)))
与之前的只包含两个节点的树相比,这里构建的树过于臃肿,它甚至为数据集中的每个样本都分配了一个叶节点。
用新数据构建新的树:

这里构建的树都有很多叶节点,产生这个现象的原因在于,停止条件tolS对误差的数量级十分敏感。如果在选项中花费时间并对上述误差容忍度取平方值,或许也能得到仅有两个叶节点组成的数:
print(createTree(myDat,ops=(10000,4)))

然而,通过不断修改条件来得到合理结果并不是很好的办法。事实上,我们常常甚至不确定到底需要什么样的结果。这正是机器学习所关注的内容,计算机应该可以给出总体的概貌。
后剪枝
使用后剪枝的方法需要将数据集分成测试集和训练集。首先指定参数,使得构建出的树足够大、足够复杂,便于剪枝。接下来从上而下找到叶节点,用测试集来判断将这些叶节点合并是否能降低测试误差,如果是的话就合并。
函数prune()的伪代码如下:
基于已有的树切分测试数据:
如果存在任一子树是一棵树,则在该子集递归剪枝过程
计算将当前两个叶节点合并后的误差
计算不合并的误差
如果合并会降低误差的话,就将叶节点合并
实际代码实现:
def isTree(obj):return (type(obj).__name__=='dict')def getMean(tree):if isTree(tree['right']):tree['right']=getMean(tree['right'])if isTree(tree['left']):tree['left']=getMean(tree['left'])return (tree['left']+tree['right'])/2.0def prune(tree,testData):if shape(testData)[0]==0:return getMean(tree)if (isTree(tree['right']) or isTree(tree['left'])):lSet,rSet=binSplitDataSet(testData,tree['spInd'],tree['spVal'])if isTree(tree['left']):tree['left']=prune(tree['left'],lSet)if isTree(tree['right']):tree['right']=prune(tree['right'],rSet)if not isTree(tree['left']) and not isTree(tree['left']):lSet,rSet=binSplitDataSet(testData,tree['spInd'],tree['spVal'])errorNoMerge=sum(power(lSet[:,-1]-tree['left'],2))+sum(power(rSet[:,-1]-tree['right'],2))treeMean=(tree['left']+tree['right'])/2.0errorMerge=sum(power(testData[:,-1]-treeMean,2))if errorMerge<errorNoMerge:print('merging')return treeMeanelse:return treeelse:return tree上述代码中,包含3个函数:isTree()、getMean()、prune()。
其中isTree()用于测试输入变量是否为一棵树,返回布类型结果。
getMean()是一个递归函数,它从上往下遍历树直到叶节点为止。如果找到两个叶节点则计算它们的平均值。该函数对树进行塌陷处理(即返回树平均值),在prune()函数中调用该函数时应明确这一点。
prune()是主函数,它有两个参数:待剪枝的树与剪枝所需的测试数据testData。prune()函数首先需要确认测试集是否为空。一旦非空,则反复递归调用函数prune()对测试数据进行切分。因为树是由其他数据集(训练集)生成的,所以测试集上会有一些样本与原数据集样本的取值范围不同。一旦出现这种情况,假设发生了过拟合,对树进行剪枝。
接下来要检查某个分枝到底是子树还是节点。如果是子树,就调用prune()来对该子树进行剪枝。在对左右两个分支完成剪枝之后,还需要检查它们是否仍然还是子树。如果两个分支已经不再是子树,那么就可以进行合并。具体做法是对合并前后的误差进行比较,如果合并后的误差比不合并的误差小就进行合并操作,反之则不合并直接返回。
运行测试:
myDat=loadDataSet('test/ex2.txt')
myDat=mat(myDat)
myTree=createTree(myDat,ops=(0,1))
myDatTest=loadDataSet('test/ex2test.txt')
myMat2Test=mat(myDatTest)
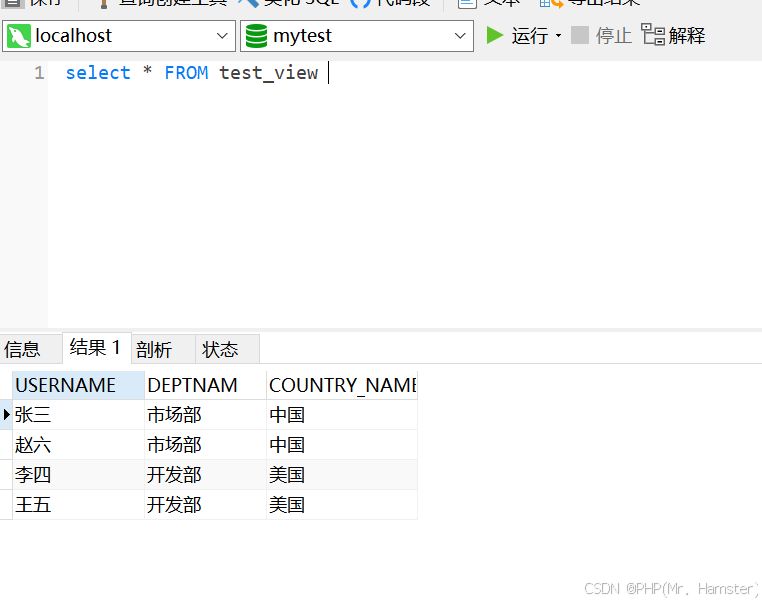
print(prune(myTree,myMat2Test))

从结果上来看,大量的节点已经被剪枝掉了,但是没有像预期的那样剪枝成两部分,这说明后剪枝可能不如预剪枝有效。一般来说,为了寻求最佳模型可以同时使用两种剪枝技术。





![buuctf [2019红帽杯]easyRE](https://i-blog.csdnimg.cn/direct/3b1eac1bb84049bca74c660921585562.png)