此次目的:
hello大家好,俺是没事爱瞎捣鼓又分享欲爆棚的叶同学!!!准备出几期博客来记录我学习kaggle数据科学入门竞赛的过程,顺便也将其中所学习到的知识分享出来。这是第一集(了解赛题),后面还会更新更详尽的代码和讲解等。(所学主要的内容来自与b站大学恩师“编程教学-Python“的教学视频内容)
在获取到数据后的第一步,我们一个去加载数据,将数据导入,代码如下:
1. 导入相关包
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import seaborn as sns
首先,导入了一些基础的Python库:
- warnings:用于管理Python警告。通过
warnings.filterwarnings('ignore')这行代码,忽略了所有的警告信息,确保在运行代码时不会因为警告而导致输出过多无关信息。 - numpy:一个强大的数值计算库,主要用于数组和矩阵的操作。
- pandas:用于数据处理和分析的库,特别擅长处理结构化数据,如表格。
- seaborn:基于Matplotlib的高级数据可视化库,提供了更为简洁和美观的绘图风格。
2. 设置Seaborn样式
sns.set(style='white', context='notebook', palette='muted')
这行代码设置了Seaborn的全局绘图样式。具体参数的含义如下:
- style='white':背景样式为白色。
- context='notebook':设置绘图的上下文为笔记本,这通常意味着图表元素的大小适合于Jupyter Notebook。
- palette='muted':颜色调色板为柔和的颜色,适合数据分析和展示。
3. 导入Matplotlib库
import matplotlib.pyplot as plt
Matplotlib是Python中最常用的绘图库,而pyplot是其子模块,用于快速绘制各种类型的图表。
4. 导入数据
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
这两行代码分别从指定的文件路径加载训练集和测试集数据。数据以CSV格式存储,通过pandas的read_csv函数加载到DataFrame中,这是一种用于处理表格数据的结构。(这里的./train.csv和./test.csv是两个文件存放地址,可能与我不一样哈)
5. 显示数据头部信息
display(train.head())
head()函数用于查看DataFrame的前几行数据。默认情况下,head()函数会返回前5行数据。display()函数用于在Jupyter Notebook中更友好地显示输出。(默认是输出5行,如果想输出例如10行,就可以改为“head(10)”)
6. 完整代码
#导入相关包
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pandas as pd
import seaborn as sns#设置sns样式
sns.set(style='white',context='notebook',palette='muted')
import matplotlib.pyplot as plt#导入数据
train=pd.read_csv('./train.csv')
test=pd.read_csv('./test.csv')
display(train.head())7.运行结果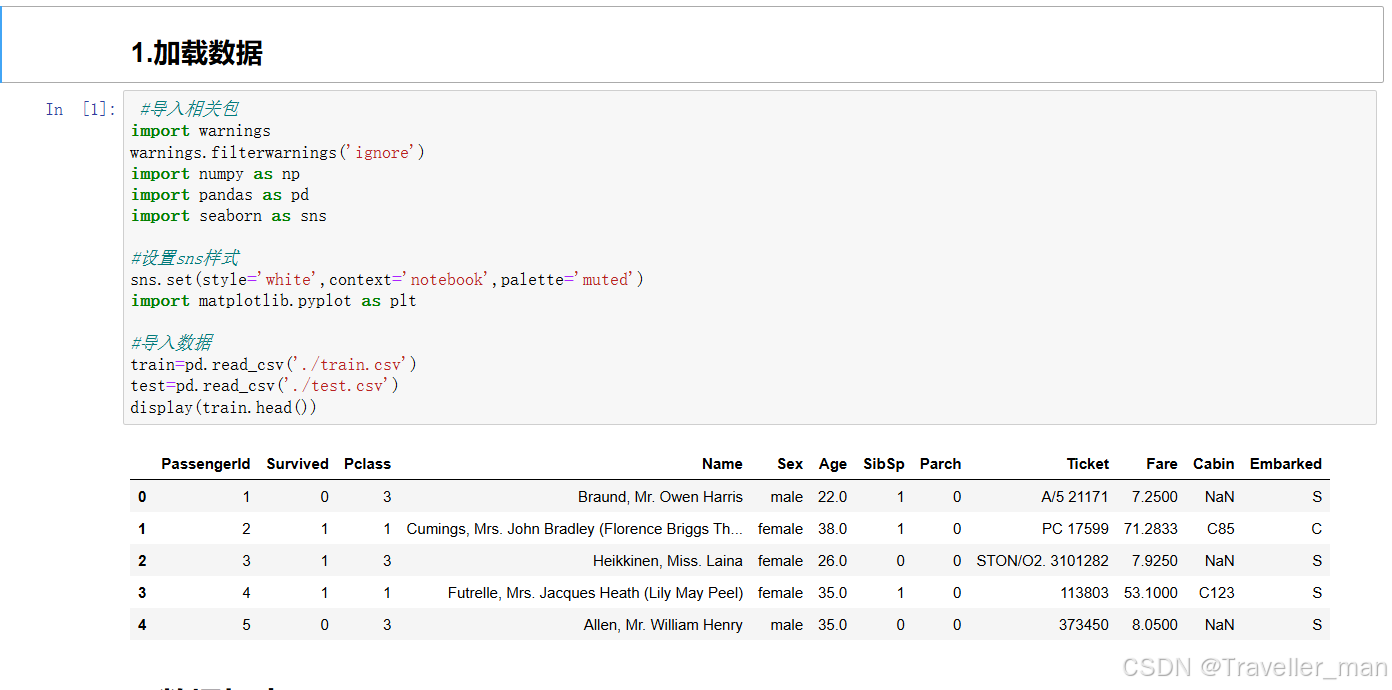
我们可以看到该表中有几个基本数据:
Passengerld(编号),
Survived(生存 0 = 否,1 = 是),
Pclass(机票等级 1 = 第一等,2 = 第二等,3 = 第三等),
Name(名字),
Sex(性别),
Age(年龄),
SibSp(同胞:泰坦尼克号上的兄弟姐妹/配偶人数),
Parch(泰坦尼克号上的父母/儿童人数),
Ticket(机票号码),
Fare(乘客票价),
Cabin(舱位号),
Embarked.(登船港 C = 瑟堡、Q = 皇后镇、S = 南安普敦)
8.总结与鼓励哈哈哈
这一集是比较基础的几个操作,主要就是将两个csv文件中的数据加载出来,并显示前几行。然后了解各列数据的含义。大家如果感兴趣的话也可以去了解一下Seaborn知识,如果需要的话,我也可以出一期相关介绍的博客。大家加油!!!俺自己也加油嘿嘿嘿!!!(情绪小妙招:每天鼓励夸奖自己很有效哦)