
人工智能(AI)领域的创新一直在不断推进,而下一个前沿领域,很可能就是文本到视频生成模型。在不久的将来,我们将会看到许多中小型公司推出自己的文本到视频生成模型,这一技术将会迅速发展。而这正是为什么当我偶然发现CogVideo模型时,我感到非常激动的原因。
CogVideo模型的创新与特点
CogVideo模型只有20亿参数的规模。尽管目前视频生成模型还处于早期阶段,生成视频在时间和资源方面仍然非常昂贵,但我们依然可以通过一些高性能的硬件来尝试它的潜力。如果你想进行真实的测试,我强烈建议使用至少配备80GB显存的Nvidia A100 GPU的多GPU集群。
接下来,我们将安装CogVideo X模型,并尝试生成一个视频。需要注意的是,这个模型使用了大规模的扩散变换器模型来基于文本提示生成视频。为了高效地建模视频数据,他们提出了使用3D变分自编码器(VAE)来压缩视频的空间和时间维度。为了改进文本与视频的对齐,他们还提出了专家变换器(Expert Transformer)和专家自适应层归一化(Expert Adaptive Layer Norm)技术,促进两种模态之间的深层融合。
CogVideo X通过渐进训练技术,擅长生成具有显著运动特征的连贯长时间视频。他们还开发了一个高效的文本视频数据处理管道,包括各种数据预处理策略和视频字幕方法,这显著提高了CogVideo X的性能,改进了生成质量和语义对齐。
根据多种机器指标和人类评估结果,CogVideo X表现出了最先进的性能。有关此模型的更多信息可以在模型卡中找到,我会在视频描述中提供链接。
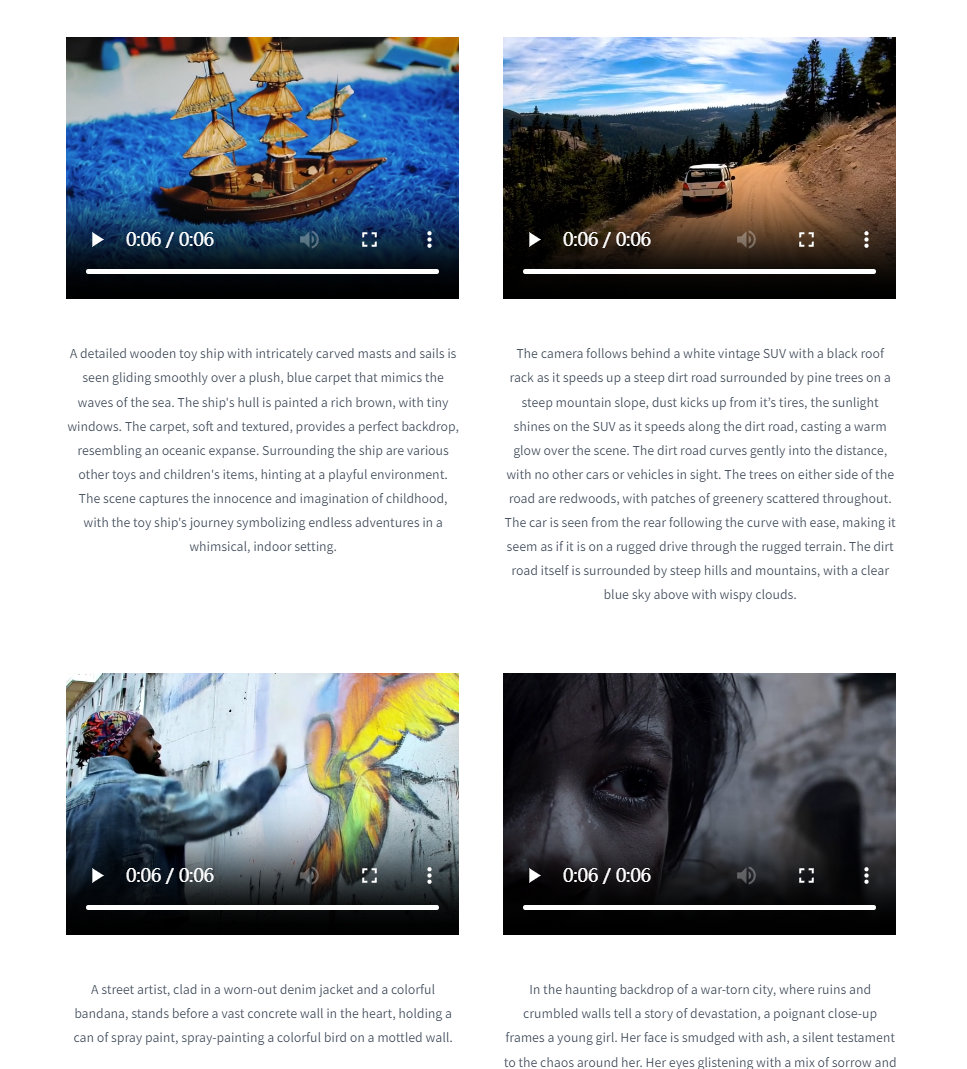
安装和运行CogVideo模型
- 创建虚拟环境:首先,我们创建一个名为
Cog的虚拟环境,并确保使用的是Python 3.10到3.12版本之间的版本。我使用的是3.11版本,虚拟环境已经创建并激活。 - 克隆仓库:接下来,我们克隆CogVideo的仓库,并切换到相应的目录。
- 安装依赖项:我们需要安装所有的依赖项,其中包括OpenCV库,这是计算机视觉领域常用的库。
- 启动Jupyter Notebook:然后,我们启动Jupyter Notebook,并在浏览器中下载模型。
- 定义和运行推理:我们定义一个简单的文本提示,并设置相关的超参数。然后我们开始进行推理。
为了演示,我们生成了一个视频,文本提示是:“一只穿着小红夹克和小帽子的熊猫坐在宁静的竹林中的木凳上”。生成视频大约需要两分钟时间,结果令人惊叹:熊猫穿着红色夹克,坐在木凳上,背景是宁静的竹林。
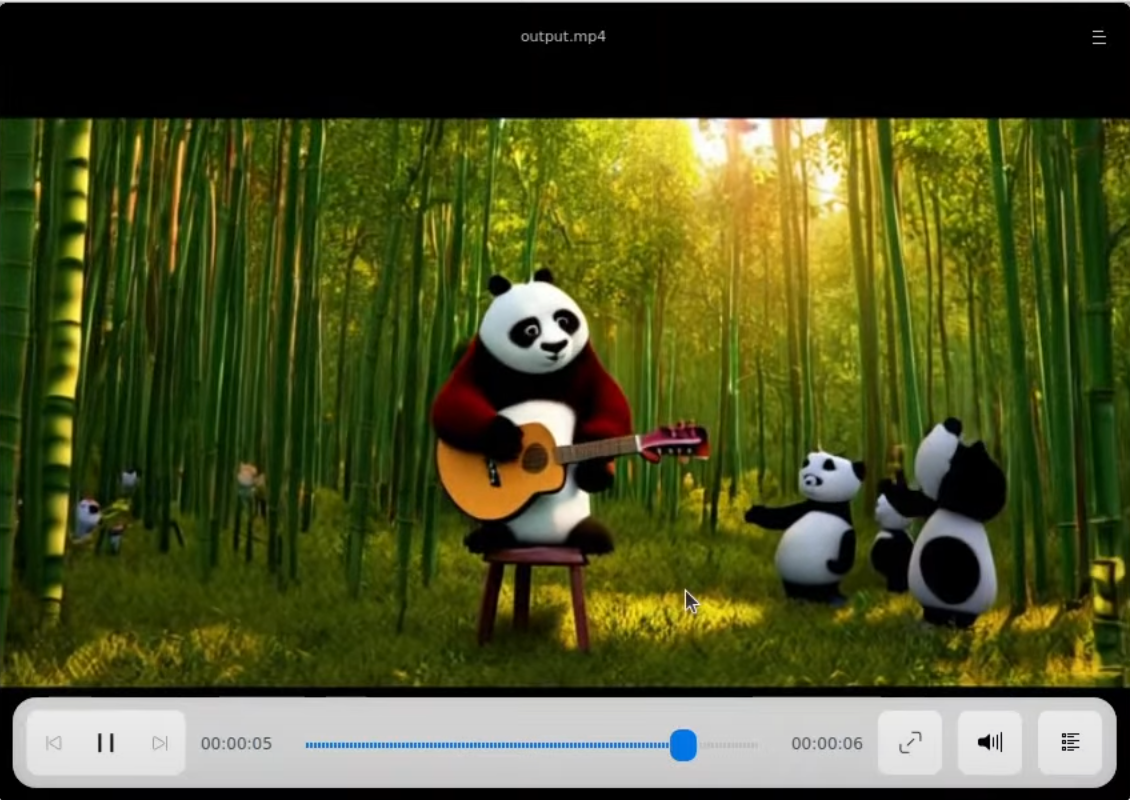
进一步的测试
我们继续进行更多的测试,例如:“一位金发碧眼的女孩站在清澈的绿松石湖边,周围是郁郁葱葱的绿植和鲜花”。尽管生成的人脸效果没有之前的熊猫视频那么好,但整体场景还是相当符合预期。
最后,我们测试了一段关于一级方程式赛车的文本提示:“一辆红色一级方程式赛车在阳光照射的赛道上高速转弯,轮胎发出尖锐的声音,并溅起火花”。生成的视频展示了赛车的高速运动和转弯时的细节,效果十分出色。

总结
通过这次演示,我们可以看到CogVideo模型在文本到视频生成方面的强大能力。尽管目前生成视频仍然需要高性能的硬件支持,但这一技术的潜力是显而易见的。
此外,CogVideo X模型的成功得益于它使用的多种创新技术,如大规模的扩散变换器模型、3D变分自编码器、专家变换器和专家自适应层归一化等。这些技术不仅提高了视频生成的质量和效率,还加强了文本与视频的对齐,从而实现了更为自然和连贯的视频内容。
在未来,文本到视频生成技术有望在多个领域发挥重要作用。无论是娱乐、教育,还是广告、医疗,这一技术都将带来革命性的变化。我们可以期待,随着技术的不断进步,文本到视频生成模型将变得更加高效和普及,让更多人能够享受到这一技术带来的便利和乐趣。
总的来说,文本到视频生成模型是AI领域的一项重要创新,它不仅展示了AI在理解和生成多模态内容方面的潜力,还为未来的技术发展指明了方向。正如CogVideo X模型所展示的那样,通过不断的技术创新和优化,我们有理由相信,未来的AI将变得更加智能和强大,为我们的生活带来更多惊喜和便利。
关注我,每天带你开发一个AI应用,每周二四六直播,欢迎多多交流。




![[Meachines] [Easy] Bastion SMB未授权访问+VHD虚拟硬盘挂载+注册表获取NTLM哈希+mRemoteNG远程管理工具权限提升](https://img-blog.csdnimg.cn/img_convert/4f2ad2a6650f029833a67f8c861b42d1.jpeg)













