目录
链表分类:
双向链表初始化:
双向链表的插入:
双向链表的打印:
双向链表的删除:
双向链表的指定结点位置查找:
双向链表的在指定位置之后插入数据:
注意:通过上文的指定结点位置查找最后返回来的结点,可以作为指定位置后数据插入函数的pos结点(具体如下图所示)
双向链表的删除指定位置结点:
双向链表的销毁:
什么是接口一致性?
链表分类:
实际在链表领域,共有8种不同的链表。单链表的全称应该是不带头单向不循环链表,而本文讲解的双向链表全称为带头双向循环链表。
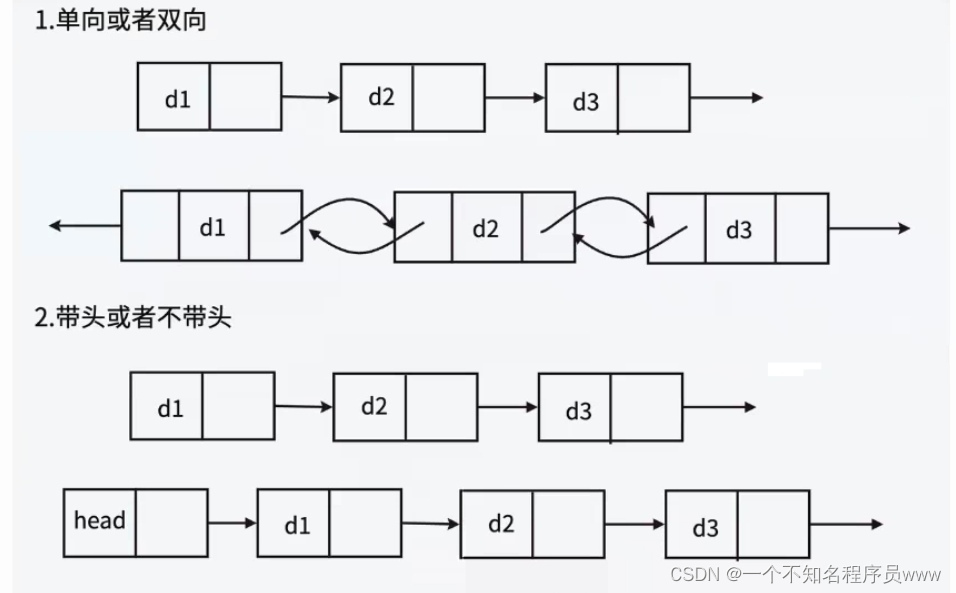
带头/不带头:含义为链表是否带有头结点。头结点只是为了后续操作的便捷,在对链表进行任意操作时,都不会发生变化。
单向/双向:结点与结点之间的关系是单向的还是双向的。
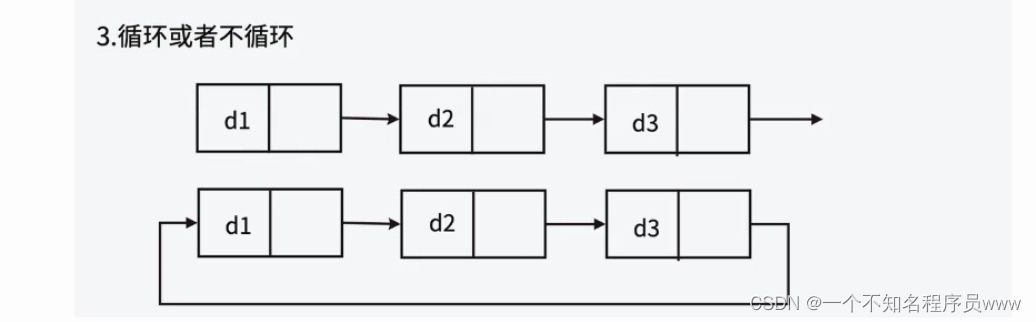
循环/不循环:循环链表意为链表的尾元结点和首元结点或头结点相连,不循环链表就没有这样的特点。
以上三个链表可能存在的特点,通过排列组合(死去的记忆又回来啦!!!), 2 × 2 × 2 = 8,因此能够得到链表可以有8种不同类型。
双向链表初始化:
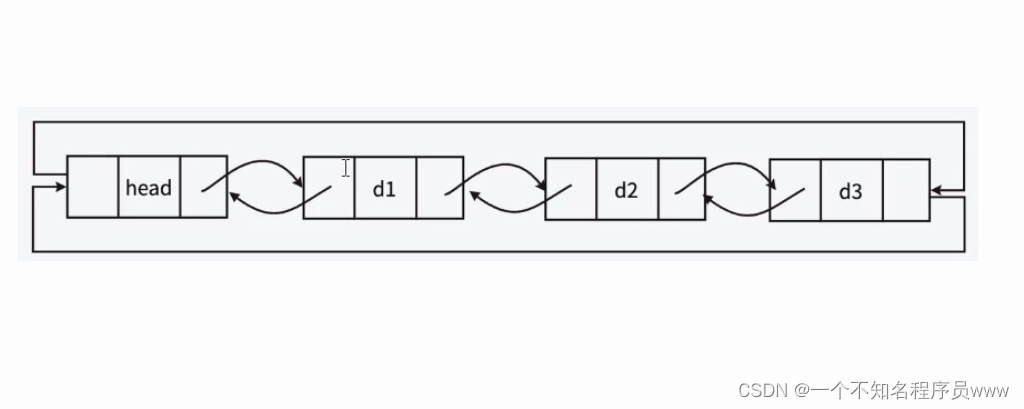
双向链表示意图
买一台电脑,初始化电脑,搞一个自己爱用的输入法,下载vs2022,在vs里创建3个小小的文件。一个测试、一个写功能实现、一个声明功能实现的函数还有头文件。
初始化方法:创建一个新链表,放一个头结点进去。那是不是我们时常得使用到新节点的开辟?
嗯🤔,那就搞一个函数专门来开辟新节点吧!
LTNode* LTBuyNode(LTDataType x)
{LTNode* node = (LTNode*)malloc(sizeof(LTNode));if (node == NULL){perror("malloc fail!");exit(1);}node->data = x;node->prev = node->next = node;return node;
}爱学习的小明同学看到这串代码,突发疑问。唉?不对啊!这不对啊!为什么代码会是
node->prev = node->next = node;
这样来写呢?!我的NULL呢?!
答曰:单链表由于是不循环的,所以尾元结点的next应该指向NULL;双向链表是一个循环链表,所以在开辟新节点时,一定要让其自己指向自己。
然后,写个初始化函数,完成初始化。这里传二级指针是因为,创建新链表头结点是需要对传来的参数有所改变的。如对一级二级指针有所疑惑,可以试着看看笔者的这篇文章:单链表复习 (C语言版)。

鉴于这篇文章,它又臭又长,笔者总结了一级二级指针的精华所在。

上面的解引用操作,讲的就是 * 操作符。如果还有疑惑,评论区见!(😀) 我是怎么用10149字写了两行字的内容的?
void LTInit(LTNode** pphead)
{*pphead = LTBuyNode(-1);//*pphead的data数据无需改变同时也不会使用,所以随便给个值即可
}完结撒花!!!(bushi)
双向链表的插入:
双向链表的插入要分为头插、尾插两种。
尾插,顾名思义,就是在链表末尾后面插入;头插,顾名思义,就是在链表表头插入。我家门前两棵树,猜猜两棵什么树(doge)
但此处请注意!!!!!!(看我打了那么多感叹号,知道重要了吧),无论是头插还是尾插,都是不算头结点的。打个比方,头插是先从头结点的后面开始插入,尾插也一样;然后,每一次头插都是在插入好的结点前插入新结点;尾插类比一下,就是在插入好的结点前后插入新结点(cv大法好)。如下图所示:
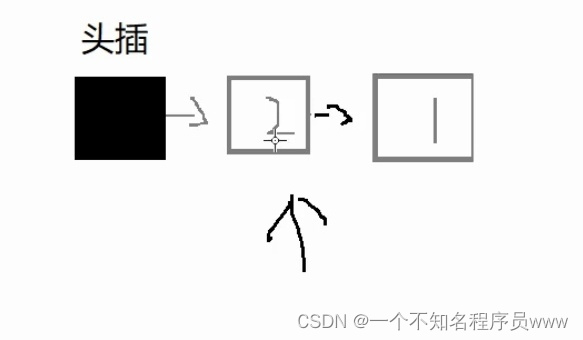
头插
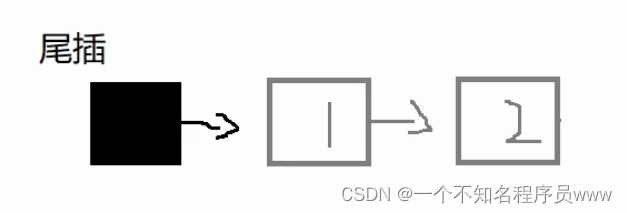
尾插
理清一些注意点以后,相信大家已经急不可待,想要上手啦。教练,我想敲代码!(超大声)
我说停停,让69岁的老同志再说两句。这边的插入,我们传给函数的是一级指针还是二级指针?
答曰:一级指针。在确定函数的形参到底是几级指针时,先得清楚传给函数的到底是什么内容。因为是插入,所以必须有一个具体类型的数据,作为结点的data值;同时,传给插入函数的应该是链表的头结点,头结点不能被改变!!!!!!所以,要传一级指针来确保头结点不被改变。
头插代码:
void LTPushFront(LTNode* phead,LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->next = phead->next;newnode->prev = phead;phead->next->prev = newnode;phead->next = newnode;
}一.链表只有一个结点的情况(不算头结点):
- 开创一个新结点(新节点的next、prev开辟成功后都先指向自己)
- 让头结点的next、prev(原本都指向自己)都指向新节点
- 让新节点的next、prev都指向头结点
- 注意:newnode->next 一开始表示的即为 newnode,因为新节点的next初始化时是指向自己的,其他的可以此类推,不难得到:四行对链表进行操作的代码,赋值号右边都是结点自身。phead->next->prev拆解开来理解,即phead自身的prev;phead->next为phead的next
所以,可以看出上文代码也能满足只有一个结点的情况。
二.链表有两个及两个以上结点的情况(不算头结点):
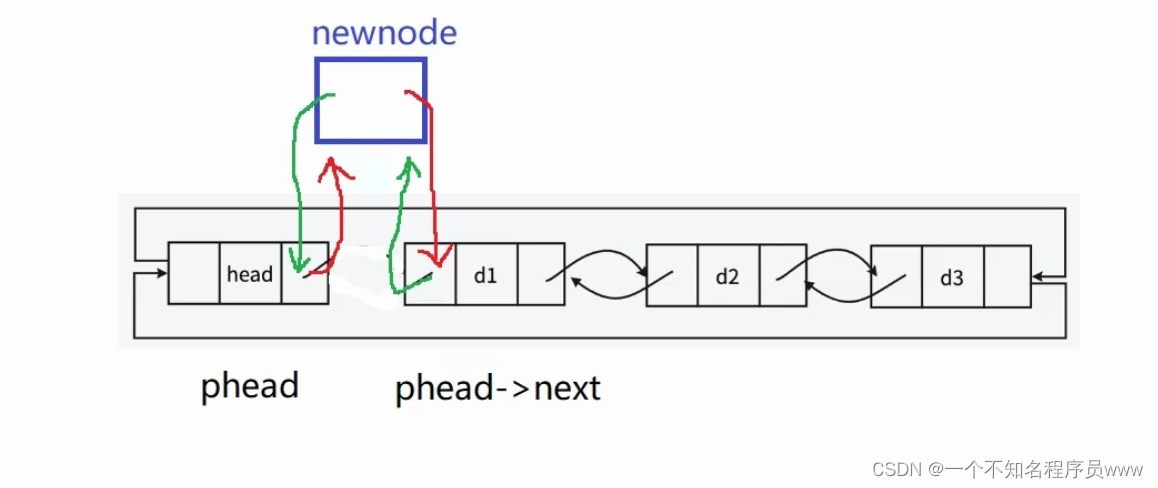
- 开创一个新结点
- 让新节点的next指向d1,prev指向头结点
- 让d1的prev指向新节点
- 让头结点的next指向新节点
- 注意:第3、第4步的顺序不能颠倒。如若颠倒,那么头结点的next就不是d1了,d1找不见了,d1的prev指向新节点就会出现问题。(当然,也可以从新结点出发,newnode的next依旧是d1)
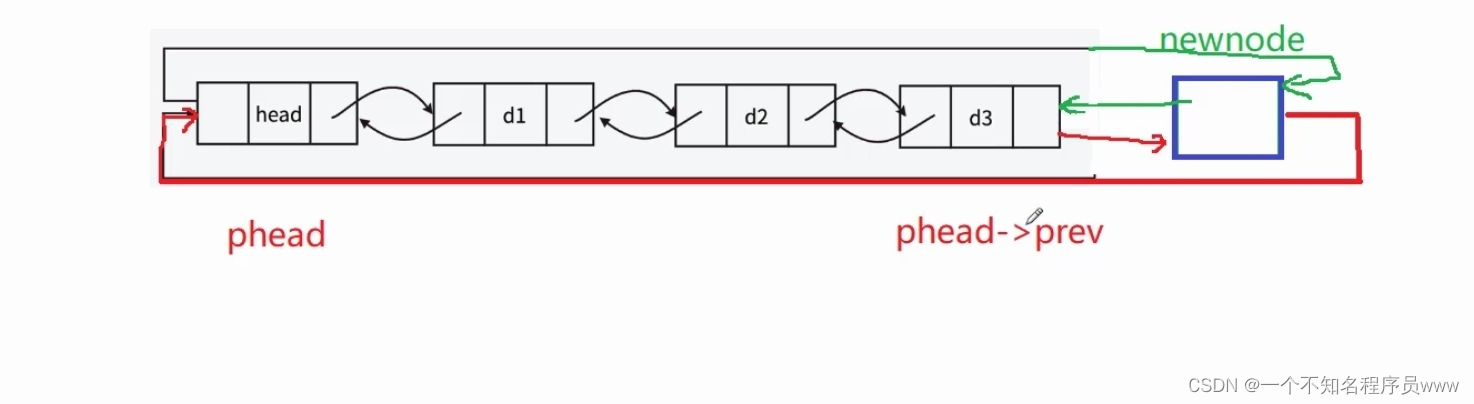
尾插代码:
void LTPushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = LTBuyNode(x);newnode->prev = phead->prev;newnode->next = phead;phead->prev->next = newnode;phead->prev = newnode;
}从上述代码,不难发现:只有一个节点时,newnode的prev指向头结点,next指向头结点;头结点的next指向新结点,prev指向新结点。满足要求。
对于两个及两个以上结点,如下图所示。尾插结束以后,双向链表的环形结构不能被破坏,所以还需要对头结点prev以及尾元结点的next进行一定的操作(尾的next指向头,头的prev指向尾)。d3和头结点的关系断开,改为和新结点的双向关系。
双向链表的打印:
完成了双向链表的插入,得要开始进行测试。如果把所有的代码都写完,然后再调试,我们就会看到:

一片欣欣向荣,那种勃勃生机万物竞发的境界犹在眼前!
如何测试?
可以通过调试,也可以直接尝试打印。笔者此处选择了后者。
双向链表打印代码:
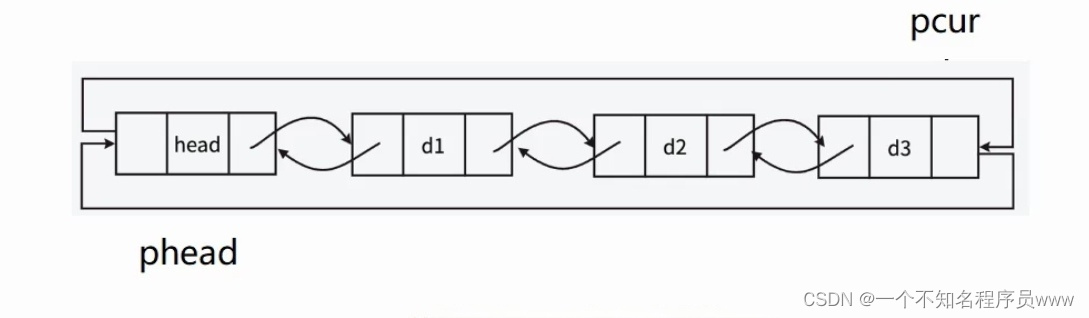
void LTPrint(LTNode* phead)
{assert(phead);LTNode* pcur = phead->next;while (pcur != phead){printf("%d->", pcur->data);pcur = pcur->next;}printf("NULL\n");
}注意点:
- 打印从头结点的下一个结点开始(形参即为头结点)
- 打印的循环退出条件不能是 == NULL,循环链表不会有为空的情况,需改为指向头结点的时候。因为尾元结点(需要打印的最后一个结点)的next为头结点,如下图所示:
进行声明,在测试文件中尝试执行。上文代码都是在List.c文件中写的。
双向链表的删除:
删除分为了头删、尾删,你是什么山?
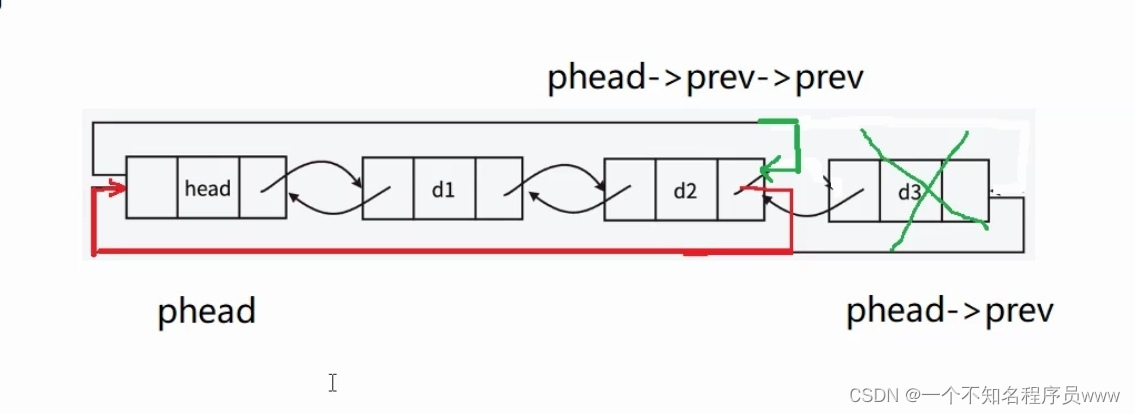
通过上图我们不难发现,尾删代码中会使用到 phead->prev->prev->next 这条语句,即链表的倒是第二个节点的next。这样一条语句又臭又长!改一改。
然后聪明的小王同学拍了拍脑袋就给了好办法,在尾删代码的开始处,直接定义一个 del = phead->next ,del恰好是需要删除的结点,很长的代码也可以简化了。(让我们一起谢谢小王同学)
del被删除以后,尾元结点变成了del->prev,因此要让 del->prev 指向头结点,然后再让头结点指向 del->prev。
尾删代码:
void LTPopBack(LTNode* phead)
{assert(phead && phead != phead->next);LTNode* del = phead->prev;del->prev->next = phead;phead->prev = del->prev;free(del);del = NULL;
}注意点:
- 对于del的free置空操作必须放在最后,要不然就会对空指针解引用
- assert断言要限制的不只是头结点不能为空,同时链表存放数据的结点也不能一个没有。可以理解成只有头结点时,链表只是完成了初始化,但链表依然为空链表。
写完尾删代码以后,依旧是声明尾删函数,测试尾删函数。(双向链表打印部分有讲解)
头删代码就是把尾删代码中,除断言语句外,其他语句中所有的next改为prev,所有的prev改为next。(聪明的你肯定也发现了,头插和尾插之间也存在这种关系)
void LTPopFront(LTNode* phead)
{assert(phead && phead->next != phead);LTNode* del = phead->next;del->next->prev = phead;phead->next = del->next;free(del);del = NULL;
}
双向链表的指定结点位置查找:
给该函数一个数据值,让函数在某个链表里寻找是否存在存放这个数据的结点,返回找到的那个节点。
LTNode* LTFind(LTNode* phead,LTDataType x)
{LTNode* pcur = phead->next;while (pcur != phead){if (pcur->data == x){return pcur;}pcur = pcur->next;}return NULL;
}该函数的撰写思路类似于双向链表的打印,可以通过上文的打印部分来理解该函数的实现。
双向链表的在指定位置之后插入数据:
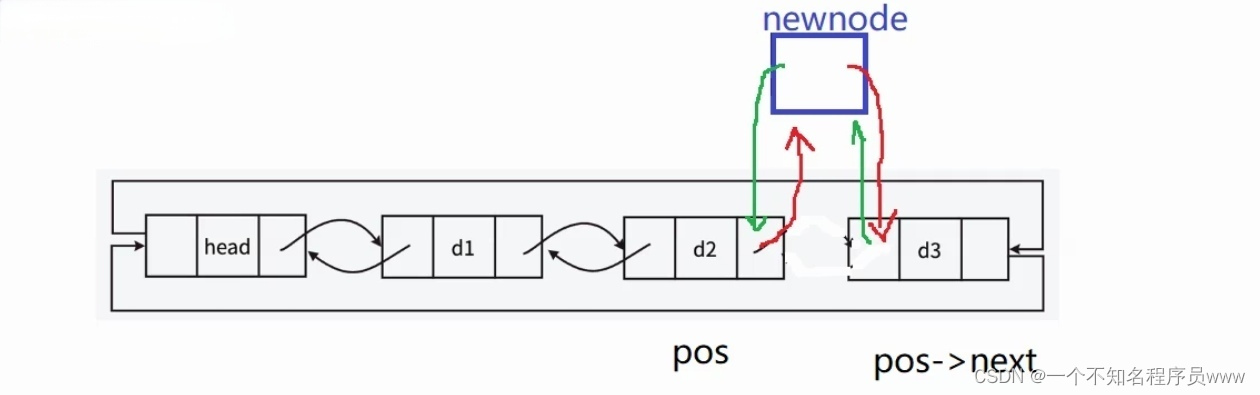
在指定位置后插入结点,一共分为两种情况。
- 在结点与结点之间插入:这种插入方式就是让新结点的next指向指定位置的下一个结点,prev指向指定位置;让指定位置的下一个结点的prev指向新结点,让指定位置的next指向新结点。是不是绕晕了?(doge)那请看下图!
- 尾插:请注意,请注意,请注意!此处的尾插代码不能直接用尾插函数。这是因为在指定位置后插入数据的函数,它的形参是指定位置的结点;而尾插函数(在插入部分有讲解),它的形参是头结点。尾插的具体方式如下图所示。
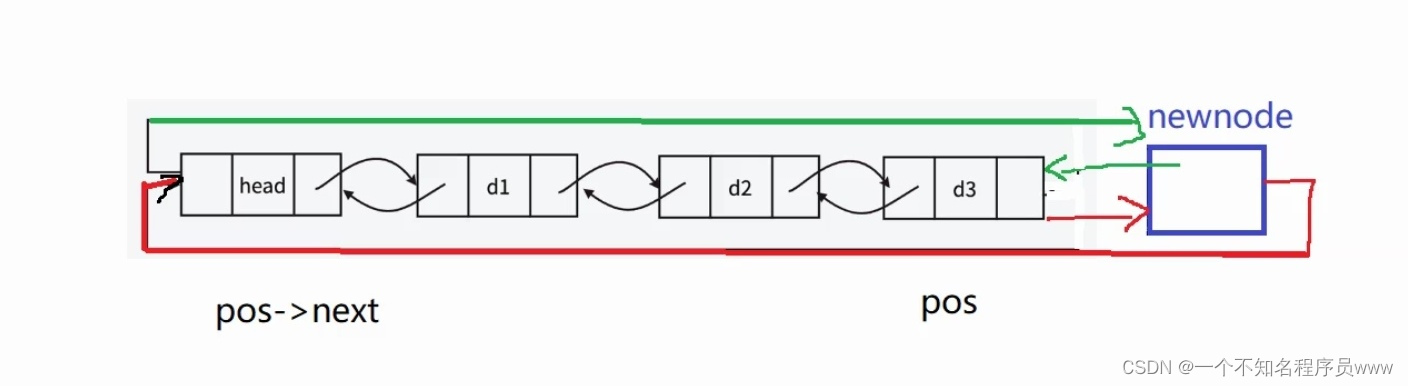
唉?!巧了,太巧了!两种情况的代码又重合上了。是的,双向链表极限情况和一般情况的代码重合率真的很高,我永远喜欢双向链表!单链表什么货色啊?是能来碰瓷双向链表的?(仅代表作者观点,如有冒犯到单链表厨,在此深感抱歉)
指定位置后插入数据的代码:
void LTInsert(LTNode* pos,LTDataType x)
{assert(pos);LTNode* newnode = LTBuyNode(x);newnode->next = pos->next;newnode->prev = pos;pos->next->prev = newnode;pos->next = newnode;
}注意:通过上文的指定结点位置查找最后返回来的结点,可以作为指定位置后数据插入函数的pos结点(具体如下图所示)

双向链表的删除指定位置结点:
写在前面:该函数的形参pos,对应的实参依旧是上图中所提到的find指针。
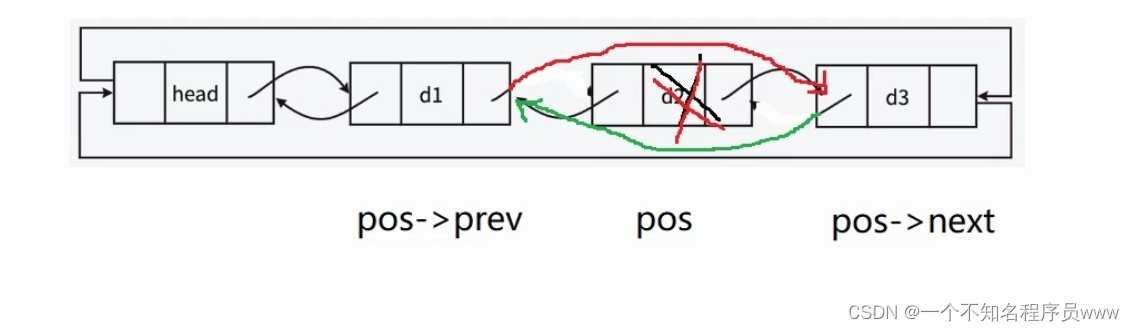
删除完pos结点,让pos的前一个结点指向头结点,让头结点指向pos的前一个结点,然后再把使用完的find free置空 。如此即可,代码如下所示:
void LTErase(LTNode* pos)
{assert(pos);pos->next->prev = pos->prev;pos->prev->next = pos->next;free(pos);
}嗯哼?!是不是少了什么东西?!pos = NULL呢?
是的,没有错。在这个函数里,并没有这条语句,这究竟是人性的扭曲,还是道德的沦丧?
答曰:都不是!因为pos是个一级指针,所以在函数内将pos置为空后,实参find不会发生改变,所以写了也起不到效果。
解决办法:不在函数里置空,在函数外置空。具体如下图所示。

双向链表的销毁:
双向链表的销毁会涉及到链表的所有结点,头结点也需要被free置空。而销毁函数的形式参数,为保持接口一致性(上一个函数传一级指针也是为了这个),最好也是头结点的一级指针形式。同时,依旧是在函数外,对实参(头结点)进行置空操作。
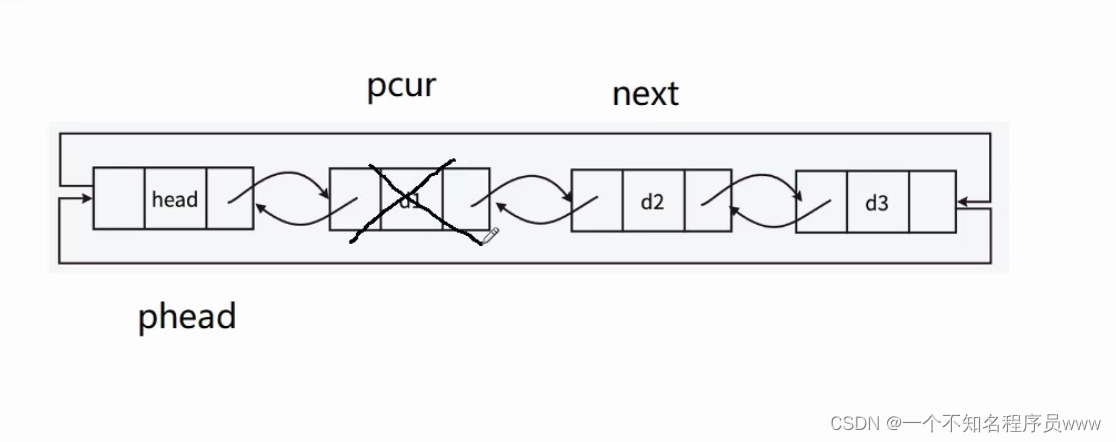
因为需要删除所有结点,所以需要用到循环语句,然后退出条件为pcur(一开始指向phead->next)指向头结点。
在循环语句中,因为直接删除pcur结点,pcur的后续链表结点就找不到了。所以需要先搞一个next指针,将pcur结点的下一个结点储存起来,然后删除pcur对应的结点,如下图所示。
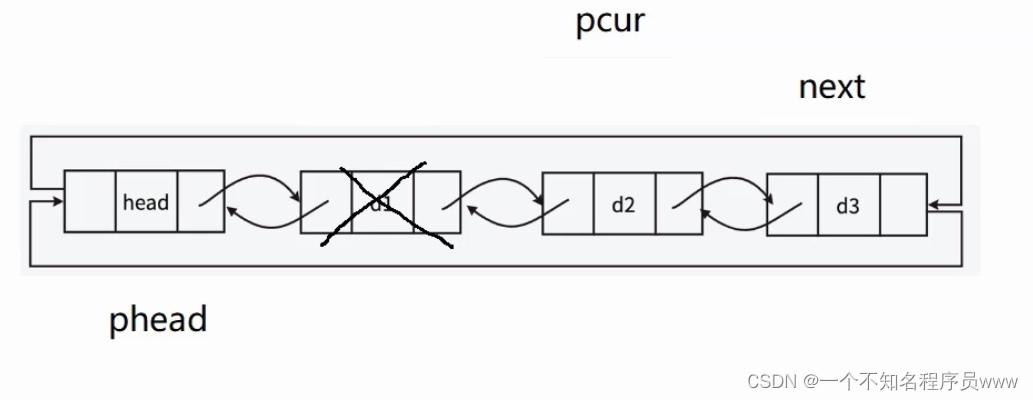
删除完以后,让pcur、next都往后走一个结点,如下图所示。重复上述操作,销毁完成。
销毁代码:
void LTDesTory(LTNode* phead)
{assert(phead);LTNode* pcur = phead->next;while (pcur != phead){LTNode* next = pcur->next;free(pcur);pcur = NULL;pcur = next;}free(phead);
}// phead = NULL; 这条语句写在函数外什么是接口一致性?

上述代码中,出现了大量函数,都有一个规律:即除了初始化函数外,传输的都是一级指针。这就是接口一致性。
在项目的实际开发过程中,一会传个一级指针,一会传个二级指针,会增加代码的出错率,所以为了降低这个问题的出现概率,接口一致性一定是越高越好的。(当然,迫不得已的时候还是可以不管这个问题的。毕竟代码和我,有一个能跑就行)
下班啦,下班啦!总算写完啦!