0、企业级实战问题
在使用 Elasticsearch 进行搜索时,我们常常关心匹配查询的文档总数而将 track_total_hits 设置为 true,如下截图所示,在数据量非常大的情况下这种检索导致的问题是:查询特别慢,聚合会更慢!

那么问题来了:
track_total_hits 引入的背景是什么?哪个版本才有的?
track_total_hits 含义是什么?
track_total_hits 什么时候需要设置 true ?
track_total_hits 什么时候设置 false?
track_total_hits 什么时候设置值?
track_total_hits 如何使用?
基于这些问题,本文逐步展开探讨。
1、track_total_hits 引入背景
在搜索引擎领域中,性能与准确性一直是开发者需要平衡的两个关键点。随着 Lucene 8(2019年4月前后)的推出,我们看到了几项重要的优化,这些优化不仅提升了搜索速度,还改变了我们获取搜索结果的方式。
特别是关于 track_total_hits 参数的变化,它直接关系到查询结果的性能表现和命中数的准确性。
Elasticsearch 在 7.0 版本集成了 Lucene 8 并引入这个特性。
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/breaking-changes-7.0.html
track_total_hits 参数控制着 Elasticsearch 在返回查询结果时,如何计算匹配文档的总数。
过去,Elasticsearch 总是精确地计算总命中数,这意味着它必须遍历所有匹配的文档。显然,处理大量文档时代价高昂。
2、 track_total_hits 的工作原理
默认行为:track_total_hits 设置为 false。
在Lucene 8中,如果不设置 track_total_hits,Elasticsearch 将默认使用 WAND 优化(WAND 优化算法本质——通过跳过不可能产生高分的文档来加快查询速度)。
这意味着当查询结果的总命中数超过一定阈值时(默认:10,000),Elasticsearch不再返回精确的命中数,而是返回一个下限值。
准确计数:track_total_hits 人为修改设置为 true。
如果用户确实需要精确的命中数,可以通过将track_total_hits设置为 true 来强制Elasticsearch计算所有匹配文档的总数。然而,这会禁用WAND优化,从而导致性能下降(前文截图说慢,很大可能就是这里的原因)。
设置阈值:用户自己设置 track_total_hits 阈值大小。
用户自己设置track_total_hits 为整数值(例如1000)时,如果匹配的文档总数超过了这个阈值,Elasticsearch 会返回的下限值就是我们设置的阈值本身,即1000,并指示命中数大于或等于1000。
如果这里有不理解,没关系,继续往后看,一会我们完整演示一遍。
3、 track_total_hits 设置后,和老版本(6及之前)显示不同点
当 track_total_hits 设置为默认值或较小的数值时,响应中的hits.total字段将包含一个对象,该对象包括命中数的值和关系,例如:
"hits": {"total": {"value": 10000,"relation": "gte"},当 relation 为 gte 时,表示实际的命中数大于或等于这个值。
当 relation 为eq时,表示命中数是精确的。
除此之外,没有别的情况了。
4、拿真实样例数据演示一把
基础索引数据 test_index_0618, 共 100万条文档。


4.1 track_total_hits 默认情况
如前所述,如果不做设置,默认支持最大文档数为 10000。
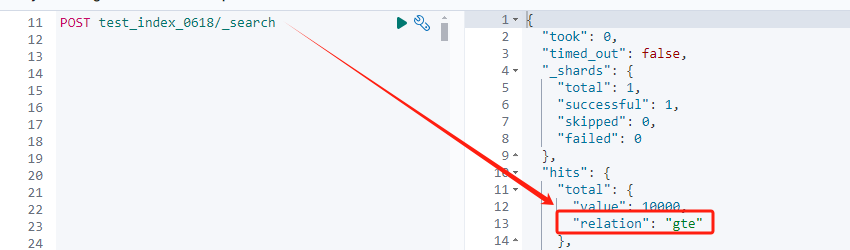
通过执行结果可以看出,召回了 10000条数据,relation 代表确切含义:真实数据大于等于 10000。
4.2 track_total_hits 设置为 true
如果我们把 track_total_hits 设置为 true,依然执行 4.1 相同的检索语句。
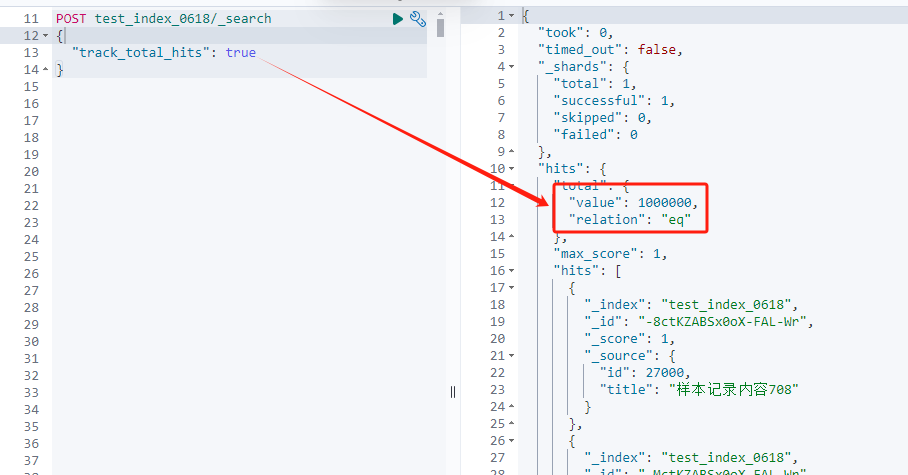
执行结果可以看出,显示了真实文档数 100万,relation 是 “eq” 代表相等。
这个示例,也间接告诉我们:企业级实战环节,如果我们有复杂的检索、聚合操作,且数据量级也巨大(千万、亿、十亿甚至更多),如果track_total_hits 设置为 true,真的有可能产生检索效率极低的“灾难性”后果(相同硬件资源的前提下,数据量越大,检索可能越慢的共识大家都很清楚)。
4.3 track_total_hits 设置为给定值
这里的给定值,本质上是我们要修改的默认的阈值大小。比如这里,我们设置为 1000。
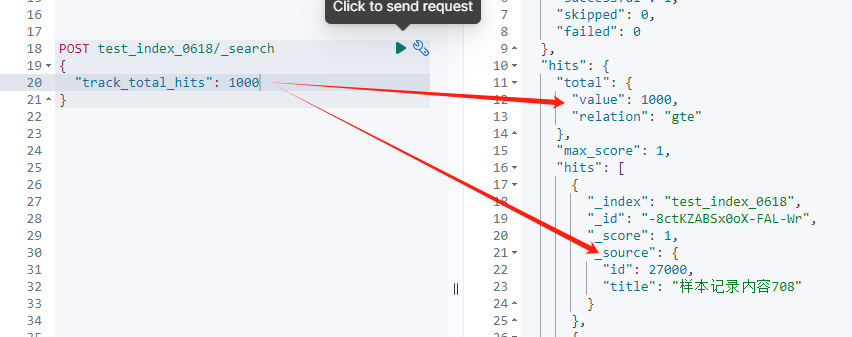
如结果展示,我们设置多大,最后召回数据就是多少。这个在真实业务场景中有选择的使用即可。
4.4 track_total_hits 设置为false
在一些性能敏感的场景下,我们可能根本不需要知道总命中数。
在这种情况下,我们可以将track_total_hits设置为false,以提高查询速度。
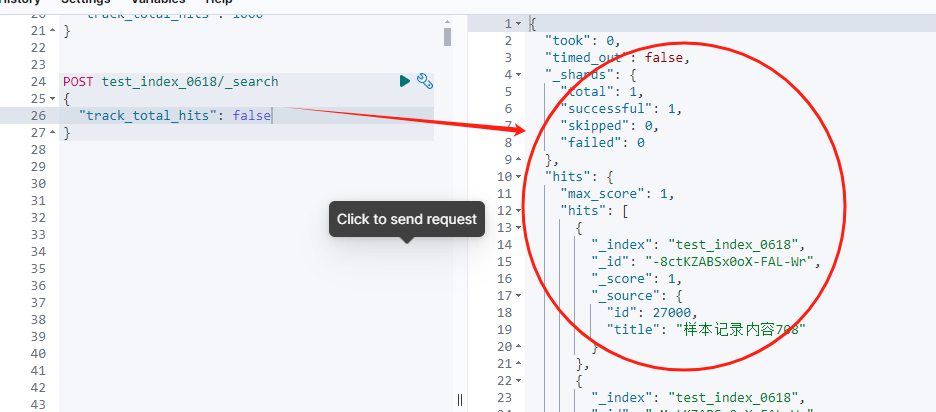
如果所示,在这种情况下,返回结果中没有 total.value,意味着Elasticsearch并未计算总命中数,从而节省了大量的计算资源。
5、 track_total_hits 的性能权衡
track_total_hits 参数的核心在于它允许我们在命中数的准确性和查询性能之间做出权衡。
具体而言,如第4部分演示所示,这里总结如下表所示。
| 参数设置 | 含义 | 应用场景 |
| 精确计算所有匹配文档的总数 | 适用于需要确切命中数的场景,但会牺牲查询性能。 |
| 精确计算匹配文档的总数,直到达到指定上限(如1000) | 在大部分情况下只关心部分准确的命中数,如需要快速查询并展示前几个结果。 |
| 完全忽略总命中数的计算 | 对命中数不敏感且更关注查询速度的场景,例如仅需快速返回文档内容而不关注总命中数。 |
再次提醒:设置 track_total_hits 为 true时,会禁用 Max WAND 优化,这可能显著影响查询性能。因此,除非确有必要,否则建议谨慎使用。
6、总结
理解并合理使用track_total_hits参数,能够帮助我们在Elasticsearch中实现更高效的查询,同时避免不必要的性能开销。
其实所有的参数都建议我们抠一下细节后,必要时做一下性能测试后再应用到实战环节。
参考
https://github.com/elastic/elasticsearch/issues/33028
https://www.elastic.co/cn/blog/whats-new-in-lucene-8
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/breaking-changes-7.0.html
https://www.elastic.co/guide/en/elasticsearch/reference/8.15/search-your-data.html#track-total-hits
更多推荐
Elasticsearch 使用误区之一——将 Elasticsearch 视为关系数据库!
Elasticsearch 使用误区之二——频繁更新文档
Elasticsearch 使用误区之三——分片设置不合理
《一本书讲透 Elasticsearch》读者群的创新之路

更短时间更快习得更多干货!
和全球超2000+ Elastic 爱好者一起精进!
elastic6.cn——ElasticStack进阶助手

抢先一步学习进阶干货!