首先感谢ctf平台和各位出题的大佬
其次感谢各位读者,对我的支持( •̀ ω •́ )y 有什么问题和建议可以私聊我
废话不多话开启你们的旅程吧 这个也是我这几天才看 一些见解和思路分享给你们
希望你们在旅途中玩的开心,学的开心✌( •̀ ω •́ )y
杂项签到

既然是签到就别往复杂想
直接010 搜索ctf

得到flag
ctfshow{a62b0b55682d81f7f652b26147c49040}
损坏的压缩包


010查看十六进制发现附件为png图片,修改后缀为png解得flag
ctfshow{e19efe2eb86f10ccd7ca362110903c05}
谜之栅栏


这个提示已经很明显了
使用010editor的文件比较功能找到两张图片的十六进制不同点,按顺序互相取一位数或者栅栏2位解得flag

010的功能远不如此 多多学习
ctfshow{f0a6a0b721cfb949a7fb55ab5d8d210a}
你会数数吗

无后缀拖010里查看源代码

一堆乱码
结合题目你会数数吗
想到可能是词频统计
这里还要用到010
工具直方图
得到直方图按照计数降序统计字符
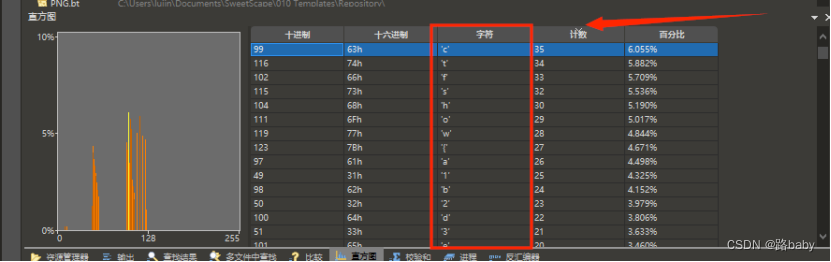
得到flag
ctfshow{a1b2d3e4g56i7j8k9l0}
这里也可以不使用010使用python
# -*- coding:utf-8 -*-
import re
from collections import Counter
#定义一个函数,用于统计字母的个数
def analyze_letter_count(text):# 从文本中提取出所有字母letters = re.findall(r'\S', text)# 统计所有字母的个数counter = Counter(letters)return counter# 将文本存入变量# 调用函数分析字母个数
def re_letter(s):regex = r'\'(.*?)\''new_string = re.findall(regex,s)return new_string
text=input("输入文本:")
letter_count = analyze_letter_count(text)
strings=str(letter_count)
#print(letter_count)
print(''.join(re_letter(strings)))同样最后也可以得到flag
ctfshow{a1b2d3e4g56i7j8k9l0}
你会异或吗
老规矩010走一遭
乱码一堆
根据题目提示(你会异或吗 神秘数字:0x50)
那我们就图片十六进制值异或十六进制50解得图片
这里还要使用010
全选代码工具十六进制运算二进制异或
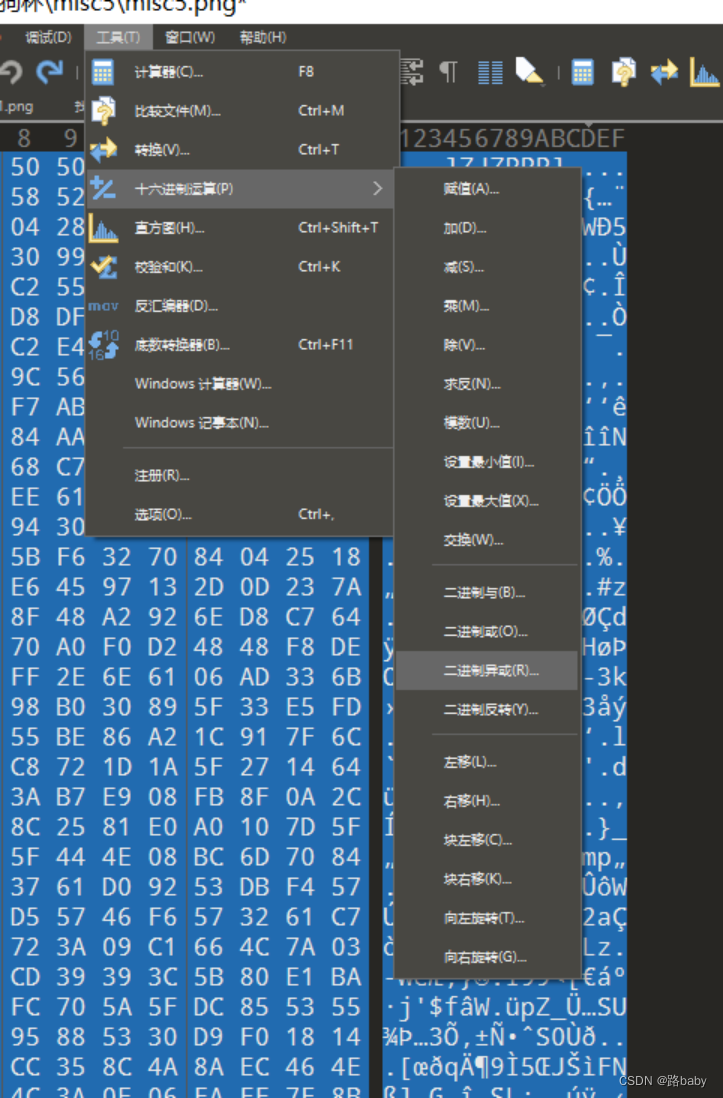
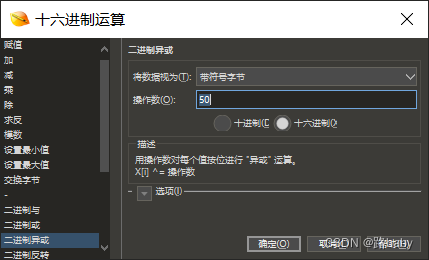
得到完整的png图片
保存如下图

得到flag
ctfshow{030d0f5073ab4681d30866d1fdf10ab1}
这里同样可以使用python
path = 'misc5.png'
# 新文件路径
new_path = 'new.png'
# 异或运算 def xor(file_path):# 以二进制读取图片with open(file_path, 'rb') as f:data = f.read()# 十六进制异或data = bytes([c ^ 0x50 for c in data])# 写入新的图片with open(new_path, 'wb') as f:f.write(data)
# 调用
xor(path)ctfshow{030d0f5073ab4681d30866d1fdf10ab1}
flag一分为二

仅仅从标题看,这个题就不可能只有一种隐写方式了
但不要慌,唯一好的一点她是个能正常打开的图了
挺好看的一个图片
使用StegSlove工具打开
查看file format

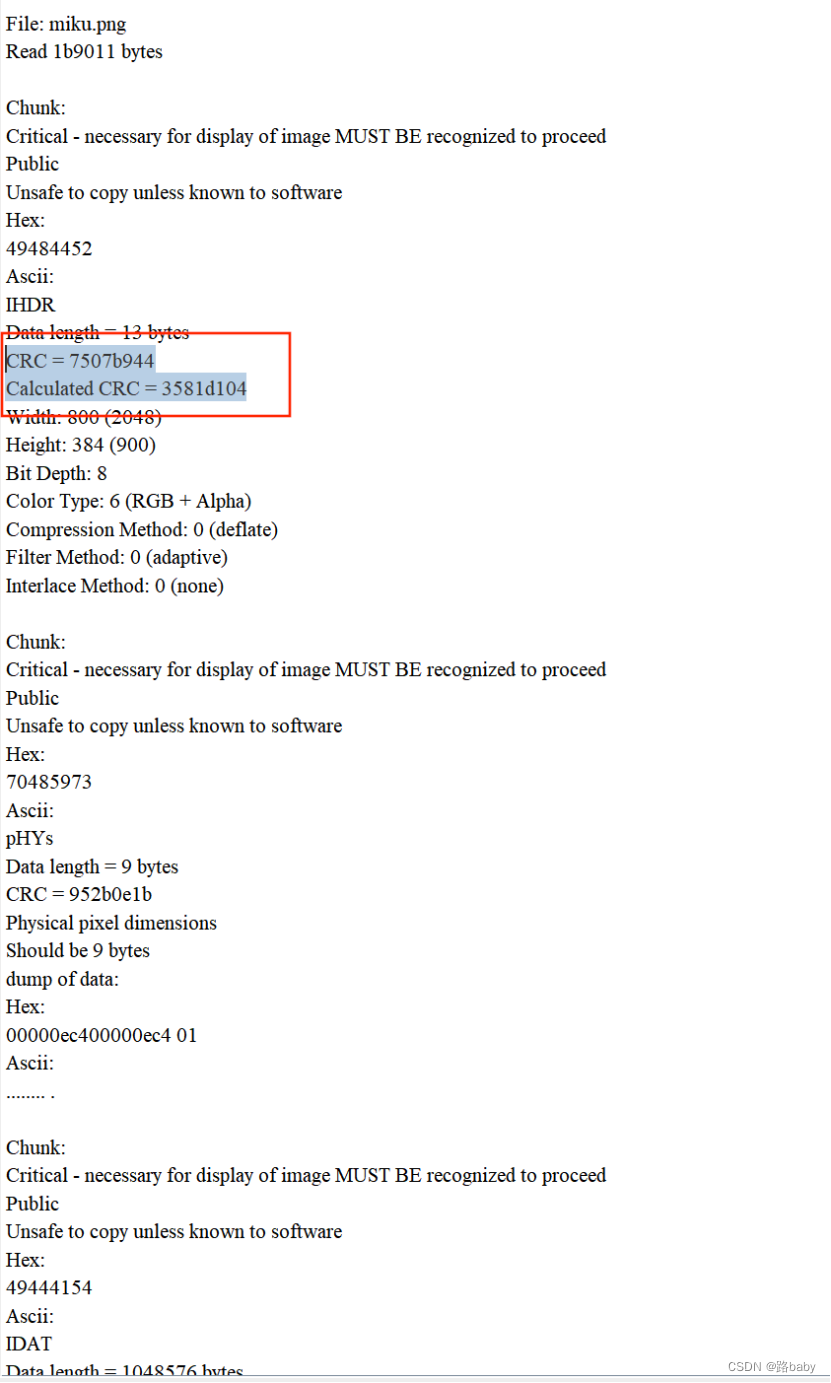
这时候你就会发现CRC(CRC) Calculated CRC(计算的CRC)不一样
这能证明什么有很大可能图片的高度被修改过
接下就是恢复高度(当然有些题你可以直接将高度调大,但我们是要精通一个题 所以我们可以使用工具。或者脚本找到图片的原始高度)
脚本
#png图片爆破宽高
import zlib
import struct
file = 'miku.png'
fr = open(file,'rb').read()
data = bytearray(fr[12:29])
#crc32key = eval(str(fr[29:33]).replace('\\x','').replace("b'",'0x').replace("'",''))
crc32key = 0x7507b944
#data = bytearray(b'\x49\x48\x44\x52\x00\x00\x01\xF4\x00\x00\x01\xF1\x08\x06\x00\x00\x00')
n = 4095
for w in range(n):width = bytearray(struct.pack('>i', w))for h in range(n):height = bytearray(struct.pack('>i', h))for x in range(4):data[x+4] = width[x]data[x+8] = height[x]#print(data)crc32result = zlib.crc32(data)if crc32result == crc32key:print(width,height)print(data)newpic = bytearray(fr)for x in range(4):newpic[x+16] = width[x]newpic[x+20] = height[x]
# fw = open(file+'.png','wb')fw = open(file, 'wb')fw.write(newpic)fw.closeprint("It's done!")
在010直接改高度就行

工具
链接:https://pan.baidu.com/s/1DHzIfRwb9zkn-qSHAl-1qQ
提取码:lulu
--来自百度网盘超级会员V3的分享
图片直接拖进去就行

不管那种都可以得到图片的原始高度

SecondP@rTMikumiku~}
后一半找到了
接下来只要找到前一半就行了
首先我们要试试分离lsb隐写之类的
后来发现是盲水印
使用waterMark.exe盲水印工具提取就可以

得到前一部分
ctfshow{FirstP@RT
最终得到flag
ctfshow{FirstP@RTSecondP@rTMikumiku~}
我是谁??

有意思的题目 感兴趣可以尝试
部署实例
刚开始还蛮期待的
其实就是找图片
在题目给出的链接里面玩游戏即可,眼睛好的可以快速通关,像我一样菜的需要点时间才能拿到flag。
当然也可以用脚本来做,找到视频的关键帧,然后截取出剪影部分,然后根据剪影在大图里找。
这里提供一个脚本供参考:(官方脚本)
import requests
from lxml import html
import cv2
import numpy as np
import jsonurl="http://xxxxxxxxxxxxxxxxxxxx.challenge.ctf.show"sess=requests.session()all_girl=sess.get(url+'/static/all_girl.png').contentwith open('all_girl.png','wb')as f:f.write(all_girl)big_pic=cv2.imdecode(np.fromfile('all_girl.png', dtype=np.uint8), cv2.IMREAD_UNCHANGED)
big_pic=big_pic[50:,50:,:]
image_alpha = big_pic[:, :, 3]
mask_img=np.zeros((big_pic.shape[0],big_pic.shape[1]), np.uint8)
mask_img[np.where(image_alpha == 0)] = 255cv2.imwrite('big.png',mask_img)def answer_one(sess):#获取视频文件response=sess.get(url+'/check')if 'ctfshow{' in response.text:print(response.text)exit(0)tree=html.fromstring(response.text)element=tree.xpath('//source[@id="vsource"]')video_path=element[0].get('src')video_bin=sess.get(url+video_path).contentwith open('Question.mp4','wb')as f:f.write(video_bin)#获取有效帧video = cv2.VideoCapture('Question.mp4')frame=0while frame<=55:res, image = video.read()frame+=1#cv2.imwrite('temp.png',image)video.release()#获取剪影image=image[100:400,250:500]gray_image=cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)#cv2.imwrite('gray_image.png',gray_image)temp = np.zeros((300, 250), np.uint8)temp[np.where(gray_image>=128)]=255#去白边temp = temp[[not np.all(temp[i] == 255) for i in range(temp.shape[0])], :]temp = temp[:, [not np.all(temp[:, i] == 255) for i in range(temp.shape[1])]]#缩放至合适大小,肉眼大致判断是1.2倍,不一定准temp = cv2.resize(temp,None,fx=1.2,fy=1.2)#查找位置res =cv2.matchTemplate( mask_img,temp,cv2.TM_CCOEFF_NORMED)min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(res)x,y=int(max_loc[0]/192),int(max_loc[1]/288)#为什么是192和288,因为大图去掉标题栏就是1920*2880guess='ABCDEFGHIJ'[y]+'0123456789'[x]print(f'guess:{guess}')#传答案response=sess.get(url+'/submit?guess='+guess)r=json.loads(response.text)if r['result']:print('guess right!')return Trueelse:print('guess wrong!')return Falsei=1while i<=31:print(f'Round:{i}')if answer_one(sess):i+=1else:i=1
You and me

下载解压俩小女孩

这一看就知道在干嘛吧
使用BlindWaterMark-master盲水印
盲水印工具下载
python3 bwmforpy3.py decode you.png you_and_me.png wm2.png


得到ctfshow{CDEASEFFR8846}
7.1.05

解压之后是个SAV的文件

这种文件不是内存取证就是游戏存档
这里信息非常少只能我们一个一个去找
使用strings检索关键字
strings flagInHere.SAV >4.txt
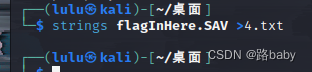
得到两个重要信息
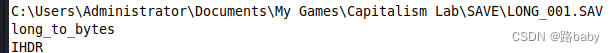
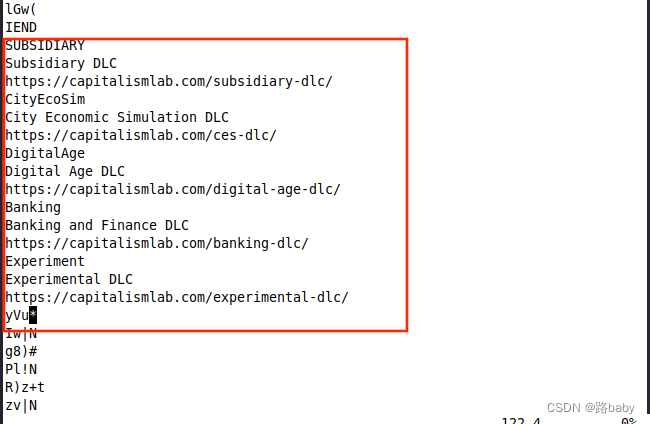
翻译一下
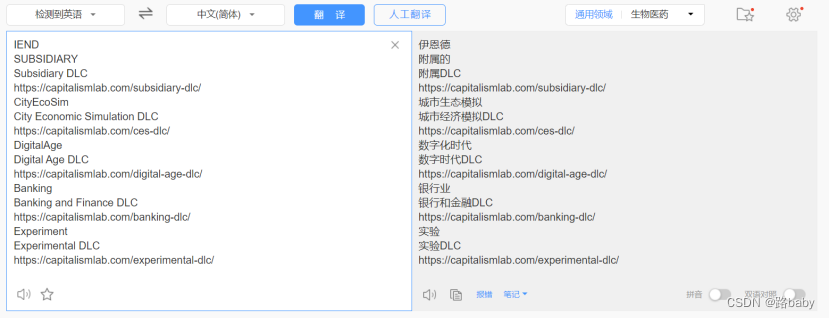
发现数个网址,点击其中一个进行访问:
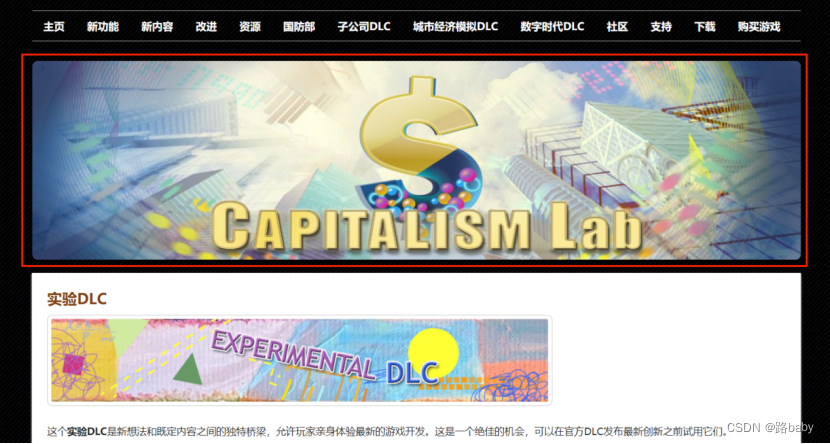
发现无论打开那个都有这张图片直接来个信息搜集
果然游戏没错那个文件八成就是游戏存档
在网上搜索游戏,发现游戏版本已经更新到了8.1.18版本。
结合题目中的7.1.05,不难联想到题目希望使用7.1.05版本的游戏来打开存档,所以使用capitalism lab v.7.1.05进行搜索

还有另一种方法:这个游戏有中文社群,可以加QQ群754365305然后找管理要。
下载后打开游戏,却不知道如何载入存档?
之前不是使用strings扫描关键字符吗 还有一段信息没有使用
“C:\Users\Administrator\Documents\MyGames\CapitalismLab\SAVE\LONG_001.SAV”,存档文件应该放置在我的文档下的MyGames文件夹中的\CapitalismLab\SAVE\中。然后打开游戏,载入存档

加载存档

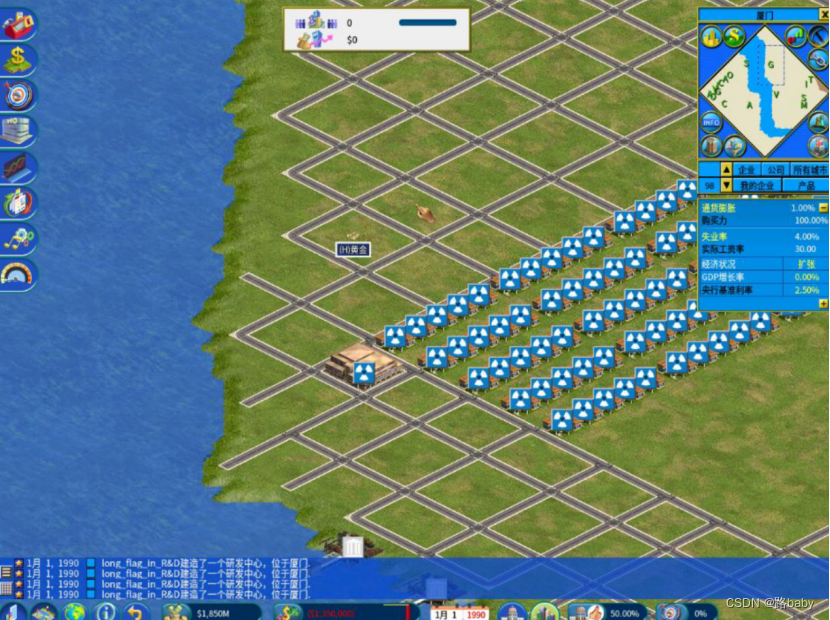
若载入存档时出错,请关闭所有MOD,并打开所有DLC。
载入存档后如上图所示。这时我们会注意到底下的flag和操作。
long_flag_in_R&D。
R&D的意思是Research&Develop
在游戏中能代表这个含义的,是研发中心。因此我们需要找到研发中心的秘密
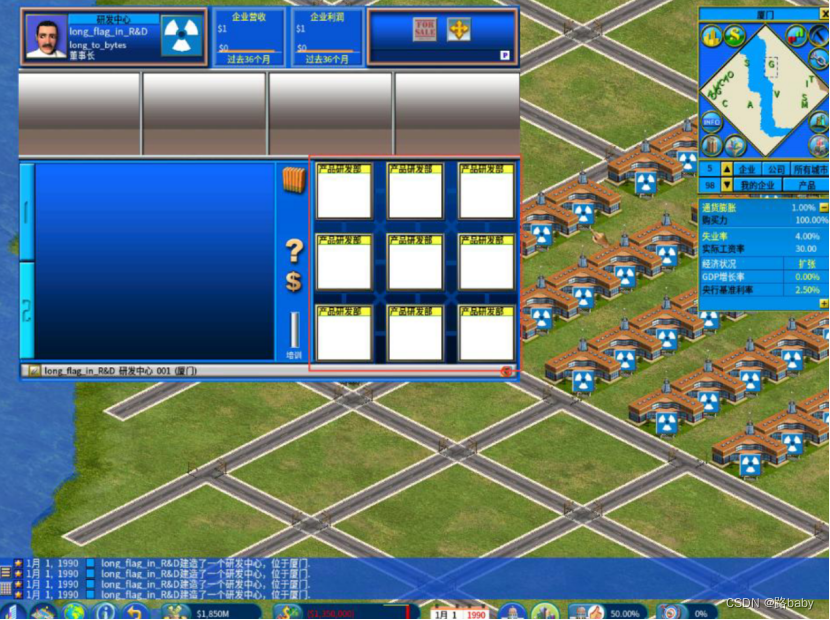
可以发现每个研发中心的研发部门的数量都不一样,将其按照从左下向右上,再行扫描的方式,可以得到这么一串数字:
9794598612147726669494087179782678475623253058262173164497949649813569030779924086502049160804再结合提示

long_to_bytes是一个常用于RSA的函数,用于将数字转成字节,来试一下:
>>> from Crypto.Util.number import long_to_bytes
>>> long _ to_bytes
(9794598612147726669494087179782678475623253058262173164497949649813569030779924086502049160804 )b " \ X01 , x84 ( xfa , xe7 ] FI & x84 ? \ \ \ \ \ \ \ \ \ \ xc1x08\ x03 / \ x9auo \ xc2;ek \ x9ed'
失败了,那有没有可能是被逆序了?
>>>long _ to _ bytes
(4080619402056804299770309653189469497944613712628503523265748762879717804949666277412168954979)
b'}3maG_d00G_0S_s1_baL_ms1lat1paC{wohsftc'
可以明显看到一个wohsftc,这是被逆序过的ctfshow。再逆序一遍即可得到flag
ctfshow{Cap1tal1sm_Lab_1s_S0_G00d_Gam3}
黑丝白丝还有什么丝?
这个题多说无意我们相信探姬师傅是为了出题才穿女装的

视频链接
https://www.douyin.com/video/7164477952082693414
提示已经非常明显了
白丝为 . 黑丝为 - 转场为
看视频手敲:.-- ....- -. - - ----- -... ...-- -- --- .-. . -.-. ..- - .

得到flag
ctfshow{w4ntt0b3morecute}
我吐了你随意
这是妥妥的拜师贴呀

当然这个提示也非常明确了零宽度字符的Unicode隐写术
零宽度字符的Unicode隐写术链接
http://330k.github.io/misc_tools/unicode_steganography.html
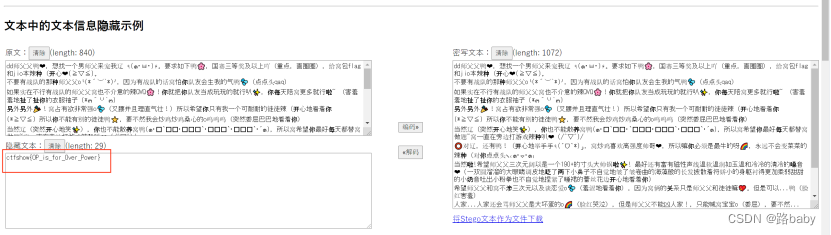
得到flag
ctfshow{OP_is_for_Over_Power}
这是个什么文件?

看见需要密码的压缩包 第一时间想到的应该是不是伪密码
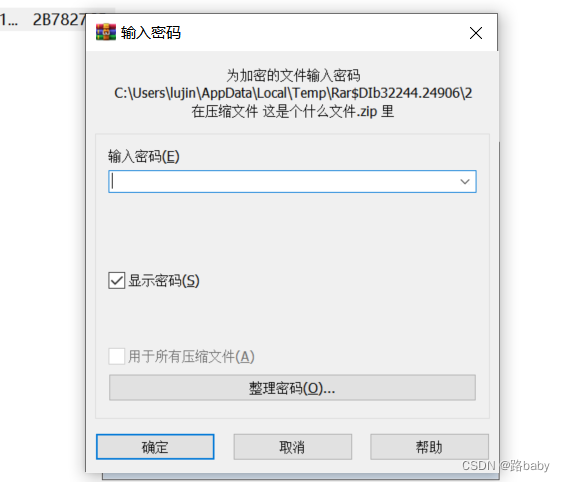
010查看 果然 把09改成00就好了

得到无后缀文件
010查看
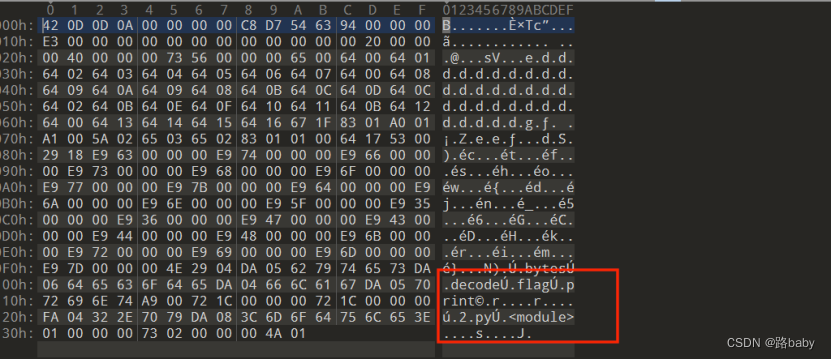
怀疑可能是pyc文件 假后缀

那就需要反编译成py文件
在线网站
https://tool.lu/pyc/

flag=bytes([99,116,102,115,104,111,119,123,99,100,106,110,106,100,95,53,54,53,102,95,71,67,68,72,95,107,99,114,105,109,125]).decode()
print(flag)运行一下就可以了

得到flag
ctfshow{cdjnjd_565f_GCDH_kcrim}
抽象画


题目说是图片打开确实乱码
说明这肯定是源代码编译过的
先试base
Base58到base32到base64
得到16进制代码
在010新建16进制文本 粘贴自十六进制文本
转化成图片保存png格式

果然够抽象
这里需要我们用到npiet这个工具
下载链接
https://download.csdn.net/download/m0_68012373/87428971?spm=1001.2014.3001.5501

npiet.exe -tpic 1.png

得到flag
ctfshow{dec8de_frejnv_frejer89}
迅疾响应
打开一看二维码 但一看就是扫不出来的那种果然什么都没有

正常思路就是图片隐写分离什么的
就使用strings搜索了一下关键字符

就发现这段字符(后来知道这是出题人设计的一个小坑)
既然什么都没有
那我们还就行走二维码这条路
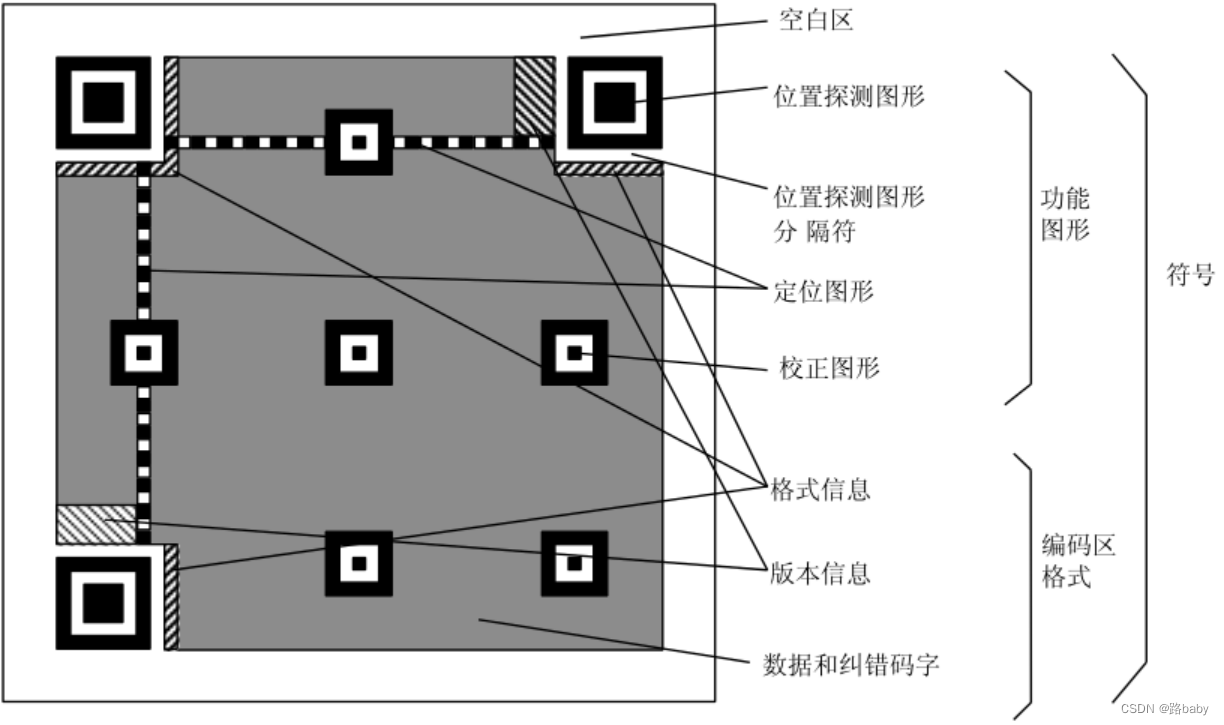
二维码识别最好用的还要看工具QRazyBox
工具在线链接https://merricx.github.io/qrazybox/
导入文件


工具提取QR信息

ctfshow{11451419-1981-
这也就表示还有一部分

使用画笔将纠错区给涂白如上图
然后工具刚刚的步骤在扫描一遍

就有了后面一部分
landexiangle}
拼起来得到flag
ctfshow{11451419-1981-landexiangle}
我可没有骗你
压缩包要密码(正常思路,肯定是密码被藏起来,需要我们去找,我们还满怀期待的去找,结果什么都没,不得不说,作者呀)

这个密码只能去爆破
使用ARCHPR,尝试爆破,选数字
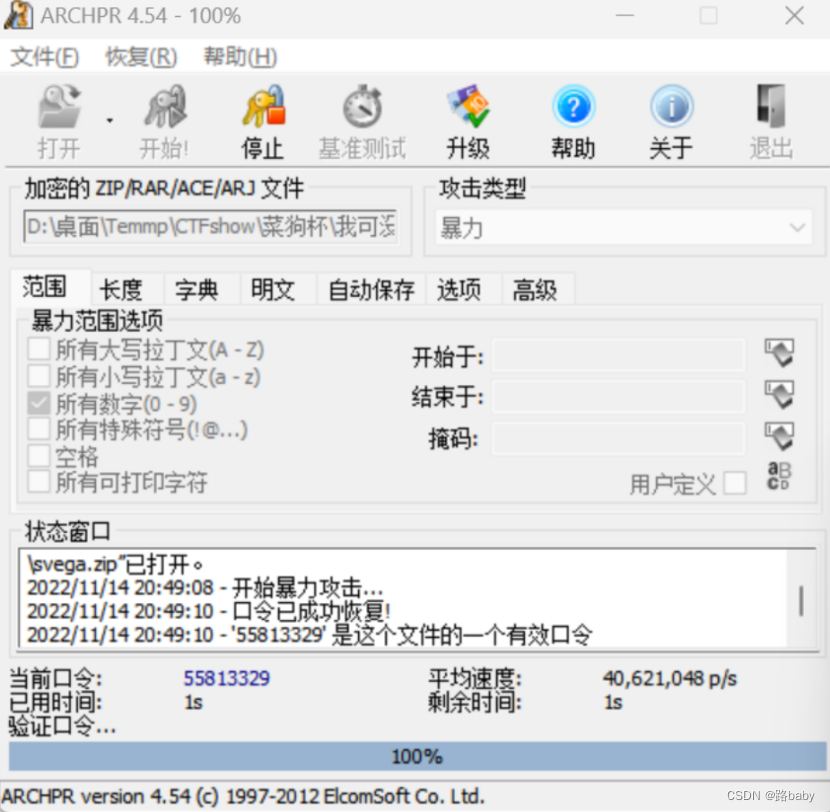

得到密码55813329
解压得到svega.mp3

直接听百分之九十九没有用但还是要听一听
然后查看源代码
没有什么特别奇怪的地方
就是文件后缀是MP3 但源代码的格式是wav
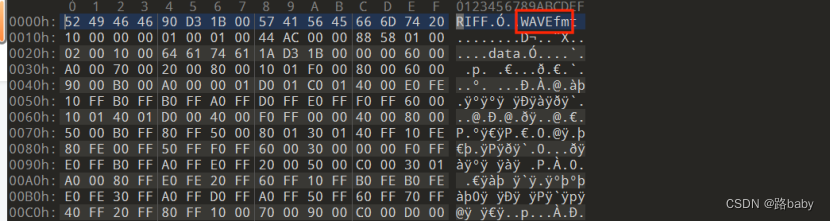
所以改后缀wav
正常顺序对文件分析分离隐写什么的一下但没有什么东西
那就绝大可能是工具隐写
关于音频隐写的工具wbStego silenteye等等就不多说了
这里使用的是静默之眼(silenteye)别为什么因为题目没有提示 那我们只能一个一个去试
先导入文件然后打开decode
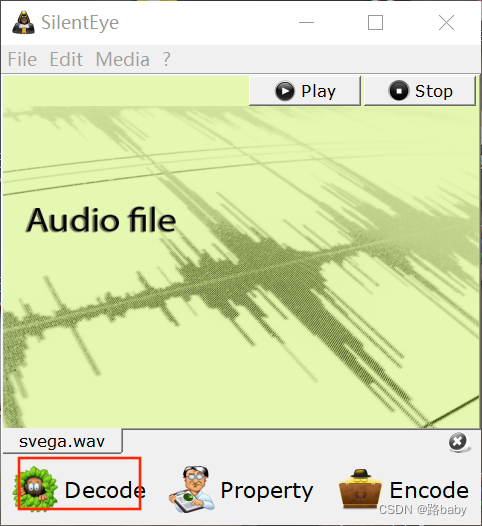
Sound qualit选择high

点击decode

解密
得到flag
ctfshow{aha_cdsc_jejcfe5rj_cjfr24J}
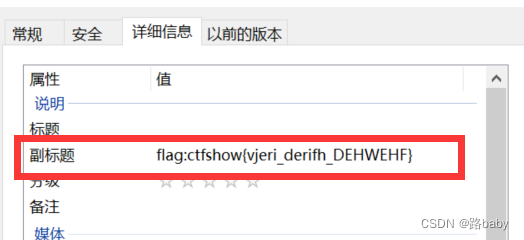
你被骗了

下载解压又是一个MP3文件

在属性详细信息里有个flag(但是误导性信息假的,照应了题目)
使用MP3Stego这个工具
(当还需要密码,先拿空密码试试,发现不是就拿标题试一下)
MP3StegoDecode.exe -X -P nibeipianle nibeipianle.mp3
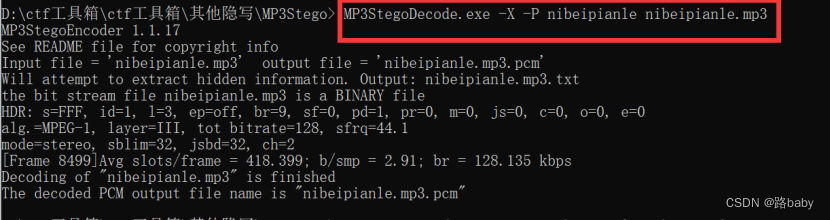
有个txt文件 里面就是flag

得到flag
ctfshow{chdv_1dcs_cjksnjn_NJDSjdcdjn}
一闪一闪亮晶晶
下载附件
两文件what is this 是不需要密码的 那个一闪一闪亮晶晶是需要的

打开二维码那就扫 普及一下这种图片形式叫汉信码。中国自己的二维码
在线网站(兔子二维码)
https://tuzim.net/hxdecode/


密码是CDBHSBHSxskv6
解压之后是一个小小音频
老规矩先仔细听听
不容易发现终于不再是单调的歌曲
它声音一响我还以为是摩斯密码
但等他放完发现根本不是
到一点无线电频的感觉
这就需要使用RX-SSTV这个工具了
这选项的解密方式是Robot36 点击Receiving然后播放音频就可以了
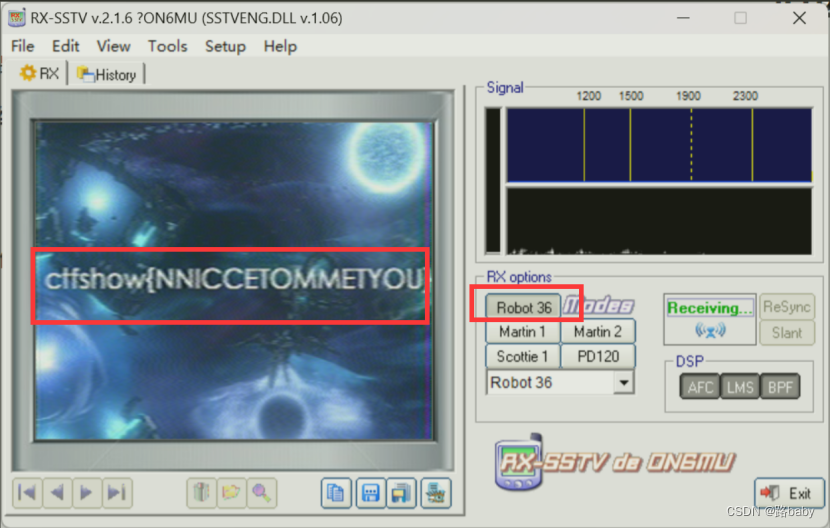
得到flag
ctfshow{NNICCETOMMETYOU}
一层一层一层地剥开我的♥
好名字如果你愿意一层一层地剥开我的心你会发现你会明白
哎名字挺好题肯定不简单一层一层的套呀

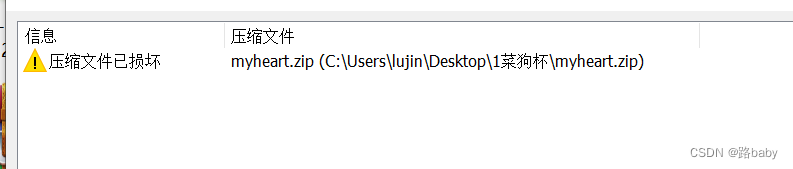
正常解压是会提示文件压缩文件已损坏
这时候肯定是要查看源代码

如上图我有理由怀疑这是一个word文档 改后缀伪docx

一段奇怪的字符


改一下字体改成宋体就行

Twinkle twinkle little star,how I wonder what you are
翻译一下

字面意思貌似没什么用 不知道后面有用吗
那就再看看之前压缩包的源代码吧
仔细查找一番貌似还有一个rar的压缩包

那就分离一下
使用binwalk
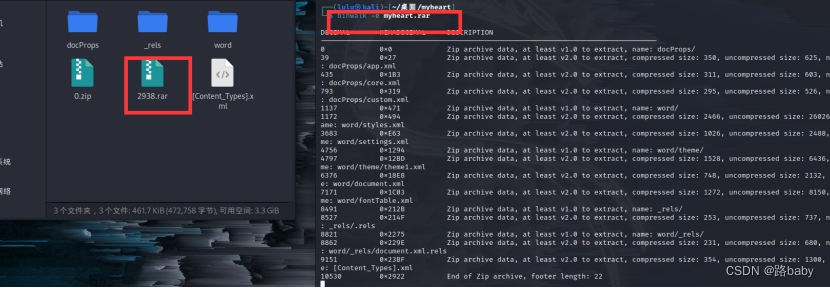

里面有一个jpg图片 和一个爱心的文件
但需要密码
猜测密码与word文档内容有关,
最后试出来是这两句歌曲的简谱数字:11556654433221
解压
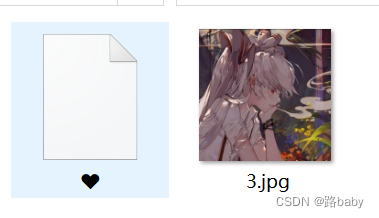
我们可以那个爱心里面是有一个txt的文件 我们有理由怀疑他是一个压缩包
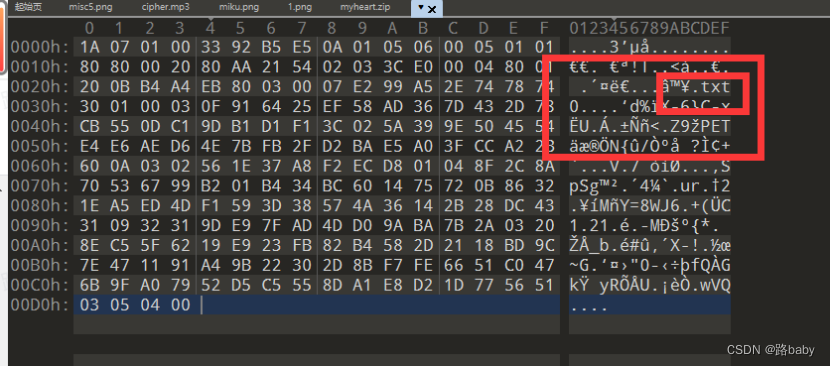
补全文件头52 62 72 21 保存

里面果然有一个txt文件 但需要密码

那先看图片吧

二话不说010走一波
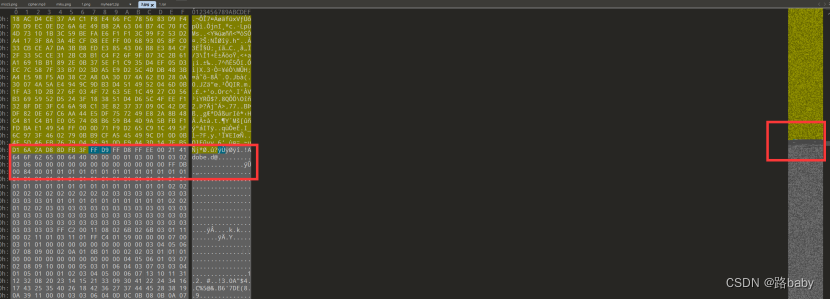
底下这么明显的分层如下图

肯定是有东西的而且底下怎么看就是一个完整的文件
用010单独提出来 保存

压缩包密码就是winkwink~
得到字符
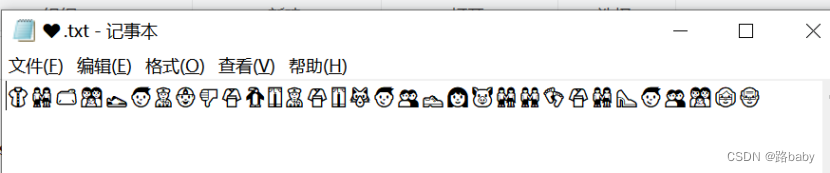
Emoji表情符号编码
在线网站
http://www.atoolbox.net/Tool.php?Id=937

得到flag
ctfshow{Wa0_wa_Congr@tulations~}
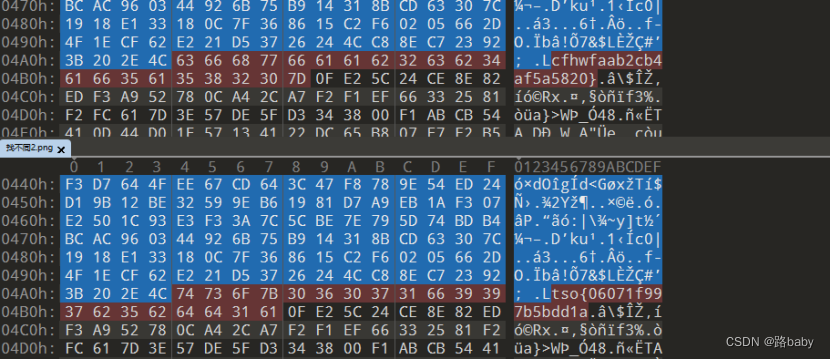
打不开的图片

压缩包里面有一张打不开的图片,使用010查看十六进制码,发现文件头与PNG文件头十六进制码相加为100,
故用0x100相减既得png图片。
写一个python脚本制作图片:
f1 = open("./misc5.5.png","rb")
f2 = open("./output.png","wb")
all_data = f1.read()
lt = []for i in all_data:if i == 0:lt.append(i)else:lt.append(0x100 - i)
f2.write(bytes(lt))
f1.close()
f2.close()得到如下图片

得到flag
ctfshow{84a3ca656e6d01e25bcb7e5f415491fa}







![8月 | O'Reilly好书推荐[每月送书]](https://img-blog.csdnimg.cn/img_convert/a12eecc40fb7989ab7480c84d7b27c42.png)