连接URI
连接 URI提供驱动程序用于连接到 MongoDB 部署的指令集。该指令集指示驱动程序应如何连接到 MongoDB,以及在连接时应如何运行。下图解释了示例连接 URI 的各个部分:

连接的URI 主要分为 以下四个部分
第一部分 连接协议
示例中使用的 连接到具有 DNS SRV 记录的 Atlas MongoDB 。自建MongoDB使用 mongodb作为协议 即可,
标准的连接字符串格式
mongodb://[username:password@]host1[:port1][,...hostN[:portN]][/[defaultauthdb][?options]]第二部分 账号密码认证
如果使用基于密码的身份验证机制,则在协议之后,连接字符串将包含您的凭据。将 user 的值替换为您的用户名,将 pass 替换为您的密码。如果您的身份验证机制不需要凭据,请忽略连接 URI 的这一部分。
第三部分 实例的地址端口
连接 URI 的下一部分指定主机名或 IP 地址,后跟 MongoDB 实例的端口。在示例中,sample.host 代表主机名,27017 是端口号。替换这些值以参考您的 MongoDB 实例。
第四部分 连接选项
连接 URI 的最后一部分包含作为参数的连接选项。 在此示例中,您设置了两个连接选项: maxPoolSize=20和w=majority 。 有关连接选项的更多信息,
连接到副本集
MongoDB 副本集部署是一组用于存储相同数据集的连接实例。这种实例配置提供了 数据冗余 和 高可用性。
要连接到副本集部署,请指定副本集节点主机名(或 IP 地址)和端口号。
如果您无法提供副本集中主机的完整列表,则可以在该副本中指定单个主机或主机子集,并指示驱动程序通过以下方式执行自动发现:
-
将副本集名称指定为
replicaSet参数的值
-
将
directConnection参数的值 指定为false
-
在副本集中指定多个主机
提示:
尽管可以指定副本集中主机的子集,但建议还是提供包含副本集中的所有主机的完整列表,以确保驱动程序能够在其中一台主机无法访问时建立连接。
ConnectionString
ConnectionString connectionString = new ConnectionString("mongodb://host1:27017,host2:27017,host3:27017/");
MongoClient mongoClient = MongoClients.create(connectionString);MongoClientSettings
ServerAddress seed1 = new ServerAddress("host1", 27017);
ServerAddress seed2 = new ServerAddress("host2", 27017);
ServerAddress seed3 = new ServerAddress("host3", 27017);
MongoClientSettings settings = MongoClientSettings.builder().applyToClusterSettings(builder ->builder.hosts(Arrays.asList(seed1, seed2, seed3))).build();
MongoClient mongoClient = MongoClients.create(settings);连接选项
读取偏好
读取偏好描述 MongoDB 客户端如何将读取操作路由到副本集
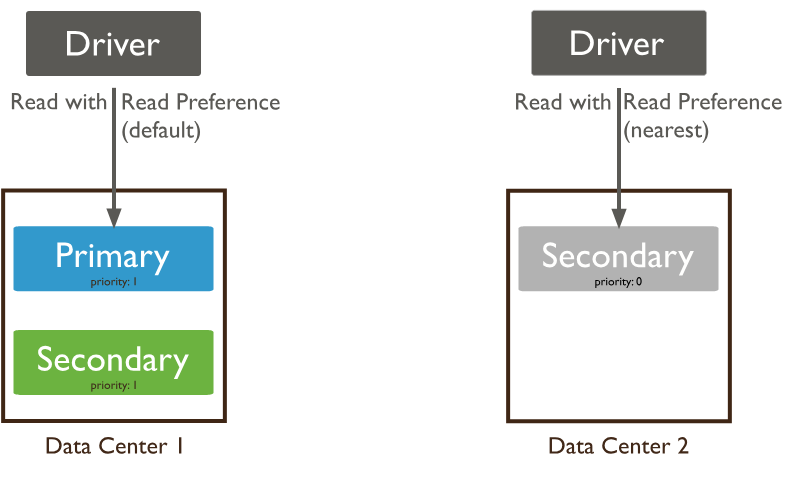
默认情况下,应用程序将其读取操作定向到副本集的主节点(即读取偏好模式“主节点”)。但是,客户端可以指定读取偏好以将读取操作发送到从节点。
读取偏好由读取偏好模式、标签集列表(可选)、maxStalenessSeconds 选项和对冲读选项构成。对冲读选项适用于分片集群,面向使用非 primary 读取偏好的读取。
读取偏好模式
下表给出读取偏好模式的简要摘要:
注意
非 primary 读取偏好模式支持对分片集群进行对冲读。
| 读取偏好模式 | 说明 |
|---|---|
| primary | 默认模式。从当前副本集主节点 分布式事务包含读取操作的primary必须使用读取偏好 |
| primaryPreferred | 在大多数情况下,操作将从主节点读取,但如果主节点不可用,则操作将从从节点成员读取。 读取优先级 primaryPreferred 支持分片集群上的对冲读。 |
| secondary | 所有操作均会从副本集的辅助成员中读取。 读取优先级 secondary 支持分片集群上的对冲读。 |
| secondaryPreferred | 操作通常从副本集的从节点成员读取数据。如果副本集只有一个主节点成员,并且没有其他成员,则操作将从主节点成员读取数据。 读取优先级 secondaryPreferred 支持分片集群上的对冲读。 |
| nearest | 根据指定的延迟阈值,从符合条件的随机副本集成员读取操作,无论该成员是主节点成员还是从节点成员。 该操作在计算延迟时会考虑以下因素:
读取偏好 nearest 支持在分片集群上进行对冲读,并默认启用对冲读选项。 |
行为
除 primary 之外的所有读取偏好模式都可能返回过时数据,因为从节点在异步过程中从主节点复制操作。[1] 如果选择使用非 primary 模式,请确保应用程序可以容忍过时数据。
读取偏好不影响数据的可见性;即客户端可以在写入结果被确认或传播到大多数副本集节点之前看到写入结果。有关详细信息,请参阅读取隔离、一致性和新近度
读取偏好不会影响因果一致性。因果一致性会话为具有 读关注的读取操作以及具有 "majority" 写关注的写入操作提供的适用于 MongoDB 部署的所有节点。
读取偏好模式
primary
所有读取操作仅使用当前副本集主节点。[1] 这是默认的读取模式。如果主节点不可用,则读取操作会产生错误或抛出异常。
primary 读取偏好模式与使用标签集列表或 maxStalenessSeconds 的读取偏好模式不兼容。如果指定标签集列表或带有 maxStalenessSeconds 的 primary 值,则驱动程序将产生错误。
分布式事务包含读取操作的primary必须使用读取偏好
primaryPreferred
在大多数情况下,操作都是从副本集的主节点读取。但是,如果主节点不可用(例如在故障转移期间),则操作将从满足读取偏好的 从节点 和标签集列表的maxStalenessSeconds读取。
当 primaryPreferred 读取偏好包含 maxStalenessSeconds 值且没有可供读取的主节点时,客户端会通过将从节点的最后一次写入与执行最近一次写入的从节点进行比较,从而估计每个从节点的陈旧程度。然后,客户端会将读取操作定向到估计延迟小于或等于 maxStalenessSeconds 的从节点。
当读取偏好包含标签集列表(标签集数组)时且没有可读取的主节点时,客户端会尝试查找具有匹配标签的从节点(按顺序尝试标签集,直到找到匹配项)。如果找到匹配的从节点,则客户端会从最近的匹配从节点群组中随机选择一个从节点。如果从节点没有匹配的标签,读取操作就会出错。
当读取偏好包含 maxStalenessSeconds 值和标签集列表时,客户端首先按过时程度筛选,然后按指定标签筛选。
使用 primaryPreferred 模式进行读取操作可能会返回过时数据。使用 maxStalenessSeconds 选项避免从客户端估计过于陈旧的从节点读取数据。
注意
读取优先级 primaryPreferred 支持分片集群上的对冲读。
secondary
操作只能从副本集的从节点读取。如果没有可用的从节点,则此读取操作会出现错误或异常。
大多数副本集至少有一个从节点,但在某些情况下可能没有可用的从节点。例如,如果节点处于恢复状态或不可用状态,则由主节点、从节点和仲裁节点构成的副本集可能没有任何从节点。
当 secondary 读取偏好包含 maxStalenessSeconds 值时,客户端通过将从节点的最后一次写入与主节点进行比较来估计每个从节点的过时程度。然后,客户端会将读取操作定向到估计延迟小于或等于 maxStalenessSeconds 的从节点。如果没有主节点,客户端将使用最近写入的从节点进行比较。
当读取偏好包含标签集列表(标签集数组)时,客户端会尝试查找具有匹配标签的从节点成员(按顺序尝试标签集,直到找到匹配项)。如果找到匹配的从节点,则客户端会从最近的匹配从节点群组中随机选择一个从节点。如果从节点没有匹配的标签,读取操作就会出错。
当读取偏好包含 maxStalenessSeconds 值和标签集列表时,客户端首先按过时程度筛选,然后按指定标签筛选。
使用 secondary 模式进行读取操作可能会返回过时数据。使用 maxStalenessSeconds 选项避免从客户端估计过于陈旧的从节点读取数据。
注意
读取优先级 secondary 支持分片集群上的对冲读。
secondaryPreferred
操作通常从副本集的从节点成员读取数据。如果副本集只有一个主节点成员,并且没有其他成员,则操作将从主节点成员读取数据。
当 secondaryPreferred 读取偏好包含 maxStalenessSeconds 值时,客户端通过将从节点的最后一次写入与主节点进行比较来估计每个从节点的过时程度。然后,客户端会将读取操作定向到估计延迟小于或等于 maxStalenessSeconds 的从节点。如果没有主节点,客户端将使用最近写入的从节点进行比较。如果没有估计滞后小于或等于 maxStalenessSeconds 的从节点,则客户端会将读取操作定向到副本集的主节点。
当读取偏好包含标签集列表(标签集数组)时,客户端会尝试查找具有匹配标签的从节点成员(按顺序尝试标签集,直到找到匹配项)。如果找到匹配的从节点,则客户端会从最近的匹配从节点群组中随机选择一个从节点。如果不存在具备匹配标签的从节点,则客户端忽略标签并从主节点读取。
当读取偏好包含 maxStalenessSeconds 值和标签集列表时,客户端首先按过时程度筛选,然后按指定标签筛选。
使用 secondaryPreferred 模式进行读取操作可能会返回过时数据。使用 maxStalenessSeconds 选项避免从客户端估计过于陈旧的从节点读取数据。
注意
读取优先级 secondaryPreferred 支持分片集群上的对冲读。
nearest
驱动程序从网络延迟处于可接受延迟窗口内的节点读取数据。路由读取操作时,nearest 模式中的读取不考虑节点是主节点还是从节点:主节点和从节点均被同等对待。
设置此模式可最大限度地减少网络延迟对读取操作的影响,而不会优先考虑当前或过时的数据。
当读取偏好包含 maxStalenessSeconds 值时,客户端会通过将从节点的最后一次写入与主节点的最后一次写入(如果可用)进行比较来估计每个从节点的陈旧程度;或者,如果没有主节点,则会将其与执行最近一次写入的从节点进行比较。然后,客户端会过滤掉其估计延迟大于 maxStalenessSeconds 的所有从节点,并将此读取操作随机定向到网络延迟不超过可接受延迟窗口
如果指定标签集列表,则客户端会尝试查找与指定标签集列表匹配的副本集节点,并将读取定向到最近的群组
当读取偏好包含 maxStalenessSeconds 值和标签集列表时,客户端首先按过时程度筛选,然后按指定标签过滤。然后,客户端从剩余的 mongod 实例中,随机将读取定向到处于可接受延迟时间范围内的实例。读取偏好节点选择文档详细描述了该过程。
使用 nearest 模式进行读取操作可能会返回过时数据。使用 maxStalenessSeconds 选项避免从客户端估计过于陈旧的从节点读取数据。
注意
读取偏好 nearest 默认指定使用对冲读来处理分片集群上的读取操作。
提示
另请参阅:
要了解特定读取偏好设置的使用案例,请参阅读取偏好使用案例
配置读取偏好
使用 MongoDB 驱动程序时,您可以使用驱动程序的读取偏好 API 指定读取偏好。请参阅驱动程序API 文档。您还可以在连接到副本集或分片集群时设置读取偏好(对冲读选项除外)。有关示例,请参阅连接字符串。
对于给定的读取偏好,MongoDB 驱动程序使用相同的节点选择逻辑
使用 mongosh 时,请参阅 cursor.readPref() 和 Mongo.setReadPref()。
读取偏好和事务
分布式事务包含读取操作的必须使用primary 读取偏好
所有连接选项
连接选项
参考
连接字符串 - MongoDB 手册 v7.0