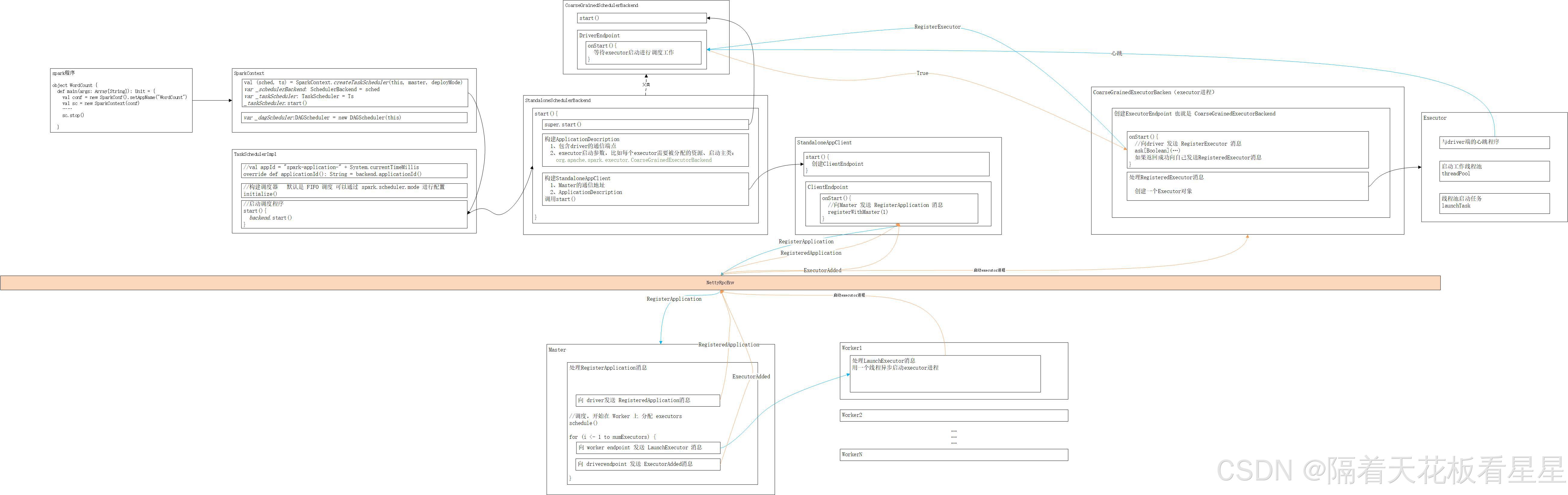
背景
通过对基础的学习和不断深入的实践,当我们已经能够制作出快速获取数据,以及制作出多个股票 乘上多种策略进行回测的部分的时候,我们就会明显发现数据有点多了,比如10支股票都用了3种策略就得到30段数据,一页显示不下,眼睛看不过来,也不知道怎么对比策略哪个好。所以这个时候我们就需要添加评价指标。
我们可以先看一下可能大家比较熟悉的对于基金进行PK时所展现的一些内容:
首先是业绩表现,即不同阶段的涨跌幅,能在一张图上画不同基金的线以看到它们之间的差别
- 近一周
- 近一月
- 近半年
- 近1年
- 今年来 等
然后有风险数据对比,包括
- 波动率
- 夏普比率
- 最大回撤
- 收益回撤比等
以上,就可以生成基本的对比和评价,我们也可以通过这个对于评价指标有一个简单的印象。后续我们再对评价指标的原理和定义进行细致的学习,我先把一些参考的资源列在这里
- Backtrader快速入门——2. 策略表现评估_backtrader 最大回撤-CSDN博客
股票软件评测系统
大部分的商用的股票及交易软件都会有类似交易评测系统的功能。在这个评测系统中,会有几个页面,包括
- 评测公式的选择(以MACD交易系统为例),
- 建仓规则(时间段和资金),
- 交易方式(手续费,多头/空头价,滑点),
- 平仓规则(止损,止盈,目标周期平仓),
- 评测品种(选择哪些股票)
在进行评测后,会出具报告,一些评价指标就会列举出来,比如 盈利数,胜率,净利润,收益率,最大回撤等,还有一些细节的数据例如平均盈利,盈亏比,连涨次数......

其实,大多数时候,大多数人只关心胜率和收益率,连回撤都懒得看,盈亏比也并不关心。对于单支或几支股票在单策略上的回测的确可以这样,注意力可能直接放在K线图上,这里买,那里应该卖,策略是否可以优化等。但如果股票数量很多,策略也很多,某些股票走势反常,有些股票就不适应某些策略等,那就需要得到更简洁、有效的评价指标,通过对这些评价进行分析处理(例如排序,加权计算等)来筛选出合适的股票以及合适的应用策略甚至合适的时机。
Backtrader内置评价
有哪些内置评价
我们已经看到了基金PK有模板式的评价指标,股票软件评价也有模板式的评价指标,那么我们在backtrader中也是有内置的评价指标的。
我们可以通过在spyder或其他IDE中按Ctrl+左键点击进入相关.py文件
# CTRL + 点击bt.analyzers的analyzers
cerebro.addanalyzer(bt.analyzers.TimeReturn, _name='pnl')# 跳到 \site-packages\backtrader\analyzers\__init__.py###############################################################################
from __future__ import (absolute_import, division, print_function,unicode_literals)# The modules below should/must define __all__ with the objects wishes
# or prepend an "_" (underscore) to private classes/variablesfrom .annualreturn import *
from .drawdown import *
from .timereturn import *
from .sharpe import *
from .tradeanalyzer import *
from .sqn import *
from .leverage import *
from .positions import *
from .transactions import *
from .pyfolio import *
from .returns import *
from .vwr import *from .logreturnsrolling import *from .calmar import *
from .periodstats import *
我们现在有AI助手了,直接把这些代码扔给AI,它就返回一个清楚的解释
您提供的代码片段看起来像是一个Python模块的导入语句,其中包含了多个与金融分析和交易策略相关的库。这些库涉及多种金融指标和分析工具,如年化收益率、最大回撤、时间收益率、夏普比率、交易分析、系统质量数(SQN)、杠杆率、持仓分析、交易记录分析、Pyfolio(一个金融分析库)、收益率分析、变异权重回报(VWR)和卡马尔比率等。
这些库和模块通常用于量化交易策略的开发和评估。例如:
annualreturn: 用于计算年化收益率。drawdown: 用于计算最大回撤。timereturn: 用于计算时间收益率。sharpe: 用于计算夏普比率。tradeanalyzer: 用于分析交易策略的表现。sqn: 用于计算系统质量数。leverage: 用于计算杠杆率。positions: 用于分析持仓情况。transactions: 用于分析交易记录。pyfolio: 用于金融分析和投资组合优化。returns: 用于分析收益率。vwr: 用于计算变异权重回报。logreturnsrolling: 用于计算对数收益率的滚动统计。calmar: 用于计算卡马尔比率。periodstats: 用于计算特定时间周期的统计数据。这些工具和库可以帮助投资者评估策略的表现,识别潜在的风险,并进行有效的策略优化。
了解了这个评价指标大概的信息后,我们要一步一步实践,看看这些评价指标具体是什么,哪些需要用,哪些看不懂,哪些不能用。
内置评价实践
00_评价程序
首先,Analyzer在哪里添加;然后,结果在哪里输出。
# 创建和配置Cerebro引擎
cerebro = Cerebro()# 添加策略和分析器
cerebro.addstrategy(MyStrategy)
cerebro.addanalyzer(xxxxx)# 运行回测
results = cerebro.run()# 获取分析结果
strat = results[0]
analysis = strat.analyzers.xxxx.get_analysis()由于我们有15个评价指标要实践,而我又不希望每次都把上面的部分重写一遍,所以做了一个函数来简化我们的工作量,这里的df_list是自选股列表,run_strategy是策略,i是自选股列表中的第i支股票,sdate1,sdate2分别是起始日期和结束日期,然后禁止了绘图,且不输出交易的log,防止它们占用屏幕空间,这样把焦点都只放到评价指标的输出上来。
def run_main_analyser1 (df_list,run_strategy,i, sdate1,sdate2, myplot=False, logoff=1): iSel = icode_ = df_list.iloc[iSel,0]df1 = get_bt_feed_data(code_)sdate = sdate1edate = sdate2cerebro = bt.Cerebro()cerebro = bt.Cerebro(stdstats=False) cerebro.addobserver(bt.observers.Broker)cerebro.addobserver(my_Trades)cerebro.addobserver(my_BuySell)cerebro.addobserver(bt.observers.DrawDown)add_analyzer_all(cerebro) # 加入---------analyzer -------------cerebro.addstrategy(run_strategy, log_off= logoff) data = bt.feeds.PandasData(dataname=df1, fromdate=sdate, todate=edate) cerebro.adddata(data, name=code_) cerebro.broker.setcash(100000.0) mycomm = StockCommission(commission=0.0002) cerebro.broker.addcommissioninfo(mycomm) cerebro.addsizer(bt.sizers.PercentSizer,percents=40) cerebro.broker.set_coc(True) result = cerebro.run() strat = result[0]analyzer_output(strat) # 输出--------analyzer -------------if logoff !=1:print('最终资产价值: %.2f' % cerebro.broker.getvalue()) # 打印最终结果if myplot:cerebro.plot(style='candle')这样我们这个函数就不需要每次进行更改,只要更新与Analyzer相关的两个函数就可以了。
01_年化收益率-annualreturn
年化收益率就是字面上的意思,以自然年(例如2023,2024)计算其年化收益率。
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.AnnualReturn, _name='_AnnualReturn') # 年化收益率def analyzer_output(result):print("--------------- AnnualReturn -----------------")sout = result.analyzers._AnnualReturn.get_analysis()print(sout)接着我们在notebook中再运行一下,这句每次都要运行一遍,后面就偷懒省略了:
run_main_analyser1(df,St_MACD_class,3,d2,d1,myplot=False, logoff=1)如果myplot=True,就会在notebook中绘制图形

得到的结果如下:
策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% --------------- AnnualReturn ----------------- OrderedDict([(2023, 0.167391800396119), (2024, -0.04428752311724082)])
这里得到的数据是OrderedDict()类型,我们可以使用几种不同的方式来处理它。
# 第一种方式 key,value处理
for key, value in sout.items():print(f'{key}: {value}')# 第二种方式 -- 使用pandas处理
series1 = pd.Series(sout))
print(series1)# 第三种方式 -- 转为dict再处理
dict1 = dict(sout)
print(dict1)-------------------------2023: 0.167391800396119 # 第一种
2024: -0.044287523117240822023 0.167392 # 第二种
2024 -0.044288
dtype: float64{2023: 0.167391800396119, 2024: -0.04428752311724082} # 第三种02_回撤-Drawdown
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.DrawDown, _name='_DrawDown') # 回撤def analyzer_output(result):print("--------------- DrawDown -----------------")sout = result.analyzers._DrawDown.get_analysis()print(sout)运行后得到结果为:
策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4%
--------------- DrawDown -----------------
AutoOrderedDict([('len', 80), ('drawdown', 13.72833873324972),
('moneydown', 17753.89797314338),
('max', AutoOrderedDict([('len', 150), ('drawdown', 14.18411680845229), ('moneydown', 18343.32380264625)]))])
很明显,这里的输出结果是个多重字典,我们直接用dict(sout)是得不到最终要的结果的,这里可以用pd.DataFrame(sout),但出来的表现形式并不是我们想要的。
于是,用了一个笨方法来进行输出,通过函数递归调用把每一层字典都遍历,先转成一个标准的字典类型,然后再按层级缩进进行打印输出:
from collections import OrderedDictdef convert_to_regular_dict(odict):if isinstance(odict, OrderedDict):return {k: convert_to_regular_dict(v) for k, v in odict.items()}else:return odictdef print_dict(d, indent=0):"""打印字典,按层级缩进。 """for key, value in d.items():print(' ' * indent + str(key) + ':', end=' ')if isinstance(value, dict):print()print_dict(value, indent + 1)else:print(value)这样能得到结果:
len: 80 drawdown: 13.72833873324972 moneydown: 17753.89797314338 max: len: 150drawdown: 14.18411680845229moneydown: 18343.32380264625
所以Drawdown得到的结果是2组,1是当前的回撤周期+回撤百分比+回撤金额;2是最大回撤的周期+回撤百分比+回撤金额,这些数据是我们最常用的评价指标之一。
03_timerun(时间序列收益 - 历史收益)
可以理解为基金信息中的历史收益,每天的收益率。这里偷懒直接用pandas.Series()处理得到Series类型的数据。
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.TimeReturn, _name='_pnl') # 返回收益率时序数据def analyzer_output(result):print("--------------- pnl -----------------")sout = result.analyzers._pnl.get_analysis()
# print(sout)s = pd.Series(result.analyzers._pnl.get_analysis()) print(s.tail(15))策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% --------------- pnl ----------------- 2024-06-26 0.008373 2024-06-27 -0.007266 2024-06-28 -0.001046 2024-07-01 0.005233 2024-07-02 0.009371 2024-07-03 0.013410 2024-07-04 -0.022394 2024-07-05 0.002082 2024-07-08 -0.012469 2024-07-09 0.003156 2024-07-10 -0.012586 2024-07-11 0.019120 2024-07-12 -0.003127 2024-07-15 -0.008365 2024-07-16 -0.002109 dtype: float64
04_夏普比率-SharpRatio
夏普比率是描述股票或组合在单位风险下的所能获得超额收益的程度。它将一只标的或组合的风险归一化,便于更好的比较组合之间的有效性。数值越高代表考虑风险的情况下股票或组合表现越好。这里我们先不探讨它是怎么得到的,我们先实践内置评价看它的输出是什么。
从下面的结果看,这里输出是只有1项的字典,key是"sharperatio",value为数值 0.487
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.SharpeRatio, _name='_SharpeRatio') # 夏普比率def analyzer_output(result):print("--------------- Sharp Ratio -----------------")sout = result.analyzers._SharpeRatio.get_analysis()print(sout)for key, value in sout.items():print(f'{key}: {value}') 策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4%
--------------- Sharp Ratio -----------------
OrderedDict([('sharperatio', 0.4870776964306147)])
sharperatio: 0.4870776964306147
05_tradeanalyzer 交易分析
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.TradeAnalyzer, _name='_TradeAnalyzer')def analyzer_output(result):print("---------------_TradeAnalyzer -----------------")sout = result.analyzers._TradeAnalyzer.get_analysis()
# print(sout)sdict = convert_to_regular_dict(sout)print_dict(sdict)在这里先说明一下交易分析的结构
total - 交易总次数/ open / closed次数
streak - 连胜/最高连胜次数 , 连败/最高连败次数
pnl - 毛利率(总,平均);净利率(总,平均)
won - 盈利(次数,总盈利,平均,最大盈利)
lost - 亏损(次数,总亏损,平均,最大亏损)
long - 买多 (次数,pnl, won, lost) -- A股只能做多,所以long有数据
short- 买空 (次数,pnl, won, lost) -- short没有数据,都是0
len - 各种情况的周期数(略)
---------------------------------------------------------------------
策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% ---------------_TradeAnalyzer ----------------- total: total: 11open: 1closed: 10 streak: won: current: 0longest: 1lost: current: 2longest: 2 pnl: gross: total: 15641.388419738887average: 1564.1388419738887net: total: 15232.749667811115average: 1523.2749667811115 won: total: 4pnl: total: 32567.260408578655average: 8141.815102144664max: 16320.18708936759 lost: total: 6pnl: total: -17334.51074076754average: -2889.0851234612564max: -7116.267063844403 long: total: 10pnl: total: 15232.749667811115average: 1523.2749667811115won: total: 32567.260408578655average: 8141.815102144664max: 16320.18708936759lost: total: -17334.51074076754average: -2889.0851234612564max: -7116.267063844403won: 4lost: 6 short: total: 0pnl: total: 0.0average: 0.0won: total: 0.0average: 0.0max: 0.0lost: total: 0.0average: 0.0max: 0.0won: 0lost: 0 len: total: 132average: 13.2max: 29min: 3won: total: 93average: 23.25max: 29min: 15lost: total: 39average: 6.5max: 11min: 3long: total: 132average: 13.2max: 29min: 3won: total: 93average: 23.25max: 29min: 15lost: total: 39average: 6.5max: 11min: 3short: total: 0average: 0.0max: 0min: 9223372036854775807won: total: 0average: 0.0max: 0min: 9223372036854775807lost: total: 0average: 0.0max: 0min: 9223372036854775807
06_SQN(System Quality Number)
SQN(System Quality Number)是一个由 Van Tharp 提出的评价指标,用于衡量交易系统的性能。<br>SQN 数值是基于交易结果的期望值、标准差和交易次数计算出来的。
- SQN 值大于 1.6 表示交易系统可能具有正期望值。
- SQN 值在 1.6 到 2.0 之间表示交易系统很好。
- SQN 值在 2.0 到 2.5 之间表示交易系统非常好。
- SQN 值大于 2.5 表示交易系统非常出色。
SQN的结果是有2个项的字典,分别是 'sqn' : 0.735 和 ’trades':10
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.SQN, _name='_SQN') def analyzer_output(result):print("---------------SQN -----------------")sout = result.analyzers._SQN.get_analysis()print(sout)print(f'SQN: {sout["sqn"]}, Trades: {sout["trades"]}')------------------------------
策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4%
---------------SQN -----------------
AutoOrderedDict([('sqn', 0.7349808981765108), ('trades', 10)])
SQN: 0.7349808981765108, Trades: 10
07_杠杆-leverage
毛杠杆率(Gross Leverage)的分析器,
输出的结果就是对应每个交易日,买了股票的那部分占净资产的比重,也可以简单理解为仓位;
这里我们用的是当前资金的40%左右(买100整数倍的股票会略有偏差),所以出来的数据基本上都是0.4上下,并且如果股票涨了,值会增加,跌了值会减小。
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.GrossLeverage, _name='_leverage') def analyzer_output(result):print("---------------_leverage -----------------")sout = result.analyzers._leverage.get_analysis()
# print(sout)
# for dt, leverage in sout.items():
# print(f'Datetime: {dt}, Gross Leverage: {leverage}')dfout = pd.Series(sout)print(dfout.iloc[40:60])策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% ---------------_leverage ----------------- 2023-03-15 0.000000 2023-03-16 0.000000 2023-03-17 0.000000 2023-03-20 0.000000 2023-03-21 0.000000 2023-03-22 0.000000 2023-03-23 0.401787 2023-03-24 0.396490 2023-03-27 0.397676 2023-03-28 0.397676 2023-03-29 0.395300 2023-03-30 0.403532 2023-03-31 0.407565 2023-04-03 0.401787 2023-04-04 0.395896 2023-04-06 0.388062 2023-04-07 0.000000 2023-04-10 0.000000 2023-04-11 0.000000 2023-04-12 0.000000 dtype: float64
08_ 持仓-positions
- positionsValue 就是持仓的值
- 一旦买入就有持仓,涨了则这个值会增大,跌了则这个值会减小
- 这样看positions与上面的leverage其次是非常类似的,它们都是每日的数据记录,不是直接的打分评价
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.PositionsValue, _name='_PositionsValue') def analyzer_output(result):print("---------------PositionsValue -----------------")sout = result.analyzers._PositionsValue.get_analysis()
# print(sout)for dt, v in sout.items():print(f'Datetime: {dt}, Value: {v}')策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% ---------------PositionsValue ----------------- Datetime: 2023-01-11, Value: [0.0] Datetime: 2023-01-12, Value: [0.0]Datetime: 2023-03-21, Value: [0.0] Datetime: 2023-03-22, Value: [0.0] Datetime: 2023-03-23, Value: [40293.39853300734] Datetime: 2023-03-24, Value: [39413.20293398534] Datetime: 2023-03-27, Value: [39608.801955990224] Datetime: 2023-03-28, Value: [39608.801955990224] Datetime: 2023-03-29, Value: [39217.60391198044] Datetime: 2023-03-30, Value: [40586.797066014675] Datetime: 2023-03-31, Value: [41271.393643031784] Datetime: 2023-04-03, Value: [40293.39853300734] Datetime: 2023-04-04, Value: [39315.40342298288] Datetime: 2023-04-06, Value: [38044.009779951106] Datetime: 2023-04-07, Value: [0.0] Datetime: 2023-04-10, Value: [0.0] Datetime: 2023-04-11, Value: [0.0]
09_交易记录-transaction
transaction在这里就表示交易的意思,它记录了每笔交易的数据。包括日期,金额,价格,sid是导入backtrader的股票的ID,symbol是股票代号,以及值。
我们的数据回测这里输出总共21条,从前面的tradeanalyzer可知 close的交易数为10,则有10对买和卖共20笔,open的1笔即还有一笔开仓但没卖,加起来总共21笔。
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.Transactions, _name='_Transactions') def analyzer_output(result):print("---------------Transactions -----------------")sout = result.analyzers._Transactions.get_analysis()
# print(sout)print(len(sout))for date, transactions in sout.items():print(f'Date: {date}')for x in transactions:print(x)print(f' Amount: {x[0]}, Price: {x[1]}, Sid: {x[2]}, Symbol: {x[3]}, Value: {x[4]}')
策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% ---------------Transactions ----------------- 21 Date: 2023-03-23 00:00:00 [9779.9511002445, 4.09, 0, '601086', -40000.0]Amount: 9779.9511002445, Price: 4.09, Sid: 0, Symbol: 601086, Value: -40000.0 Date: 2023-04-07 00:00:00 [-9779.9511002445, 3.89, 0, '601086', 38044.009779951106]Amount: -9779.9511002445, Price: 3.89, Sid: 0, Symbol: 601086, Value: 38044.009779951106 Date: 2023-05-04 00:00:00 [10454.333757131215, 3.75, 0, '601086', -39203.751589242056]Amount: 10454.333757131215, Price: 3.75, Sid: 0, Symbol: 601086, Value: -39203.751589242056......
10_金融投资组合分析库-pyfolio
我在学习和实践的过程中,看到很多关于pyfolio的文章,列了一些如下:
- Backtrader快速入门——3. 使用pyfolio进行可视化分析-CSDN博客
- backtrader:终于可以集成pyfolio了_qlib如何集成quantstats和pyfolio的-CSDN博客
从上面的文章,了解到一些信息
- 本来,backtrader可以集成PyFolio这个第三方库,方便地以可视化方法输出这些指标。
- 但是,由于PyFolio后来变更了接口,两者就没有集成了。
- 好在,还有一个第三方库quantstats,可以非常方便地与backtrader集成。
不过这些提到的pyfolio应该是另外一个库,而并非我们这里的backtrader内置评价指标,我们后续再去研究pyfolio库和quantstats库的使用,当前先把内置指标输出看看它做了哪些工作。
打开\backtrader\analyzers\pyfolio.py文件,如下
class PyFolio(bt.Analyzer):'''This analyzer uses 4 children analyzers to collect data and transforms itin to a data set compatible with ``pyfolio``Children Analyzer- ``TimeReturn``Used to calculate the returns of the global portfolio value- ``PositionsValue``Used to calculate the value of the positions per data. It sets the``headers`` and ``cash`` parameters to ``True``- ``Transactions``Used to record each transaction on a data (size, price, value). Setsthe ``headers`` parameter to ``True``- ``GrossLeverage``Keeps track of the gross leverage (how much the strategy is invested)由此可知,这里的pyfolio使用四个子分析器来收集数据,并将其转换为与 pyfolio 兼容的数据集。
PyFolio 包含以下四个子分析器:
- TimeReturn:用于计算全球投资组合价值的回报。 -- 03
- PositionsValue:用于计算每个数据的持仓价值。 -- 08
- Transactions:用于记录每个数据的交易(数量、价格、价值)。 -- 09
- GrossLeverage:用于跟踪毛杠杆率(策略的投资水平)。 -- 07
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.PyFolio, _name='_PyFolio') def analyzer_output(result):print("---------------_PyFolio -----------------")sout = result.analyzers._PyFolio.get_analysis()
# print(sout)for k,v in sout.items():print(f'key: {k}, Value: ...')------------------------------------------
策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4%
---------------_PyFolio -----------------
key: returns, Value: ...
key: positions, Value: ...
key: transactions, Value: ...
key: gross_lev, Value: ...放到函数中运行,的确是得到四组多重字典,这四组在前面都分别实践过了,就不重复了。
11_回报-returns
该分析器名为 Returns,用于计算总复合回报率、平均回报率、复合回报率和年化回报率。
返回的字典包含以下键:
- rtot:总复合回报率
- ravg:整个期间(时间框架特定)的平均回报率
- rnorm:年化/标准化回报率
- rnorm100:年化/标准化回报率,以100%表示
这里我们同样打开文件 \backtrader\analyzers\returns.py ,里面有参数的说明
- ``tann`` (default: ``None``)Number of periods to use for the annualization (normalization) of thenamely:- ``days: 252``- ``weeks: 52``- ``months: 12``- ``years: 1``于是我们把这四个参数都试了一遍,并参考某文章中对年化收益率的计算公式
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.Returns, _name='_Returns_day', tann=252) # 计算252日度收益cerebro.addanalyzer(bt.analyzers.Returns, _name='_Returns_week', tann=52) # 计算52周度收益cerebro.addanalyzer(bt.analyzers.Returns, _name='_Returns_month', tann=12) # 计算12月度收益cerebro.addanalyzer(bt.analyzers.Returns, _name='_Returns_year', tann=1) # 计算1年度收益def analyzer_output(result):print("---------------_PyFolio -----------------")sout1 = result.analyzers._Returns_day.get_analysis()sout2 = result.analyzers._Returns_week.get_analysis()sout3 = result.analyzers._Returns_month.get_analysis()sout4 = result.analyzers._Returns_year.get_analysis()print(sout1)print(sout2)print(sout3)print(sout4) 策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4%
---------------_PyFolio -----------------
OrderedDict([('rtot', 0.10947386238015983), ('ravg', 0.00029992839008262964), ('rnorm', 0.07851161276138774), ('rnorm100', 7.8511612761387735)])
OrderedDict([('rtot', 0.10947386238015983), ('ravg', 0.00029992839008262964), ('rnorm', 0.015718532957296315), ('rnorm100', 1.5718532957296316)])
OrderedDict([('rtot', 0.10947386238015983), ('ravg', 0.00029992839008262964), ('rnorm', 0.003605625365242038), ('rnorm100', 0.3605625365242038)])
OrderedDict([('rtot', 0.10947386238015983), ('ravg', 0.00029992839008262964), ('rnorm', 0.0002999733730993339), ('rnorm100', 0.02999733730993339)])
12_变异加权回报率-VWR
VWR (Variability-Weighted Return)是一种改进的夏普比率计算方法,它考虑了回报的变异性来加权回报,从而提供了一个更好的风险调整后收益的衡量标准。
同上,我们暂不考虑它的原理和计算,先把内置评价看输出结果。
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.VWR, _name='_VWR') def analyzer_output(result):print("---------------_VWR -----------------")sout = result.analyzers._VWR.get_analysis()print(sout)--------------------------------
策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4%
---------------_VWR -----------------
OrderedDict([('vwr', 4.415307366076662)])结果也是只有一项的字典结构,即 VWR的值。
13_滚动回报率-logreturnsrolling
# 分析器名为 LogReturnsRolling,用于计算给定时间框架和压缩的滚动回报。
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.LogReturnsRolling, _name='_LogReturnsRolling') def analyzer_output(result):print("---------------_LogReturnsRolling -----------------")sout = result.analyzers._LogReturnsRolling.get_analysis()
# print(sout)for key, value in sout.items():print(f'{key}: {value}')策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% ---------------_LogReturnsRolling ----------------- 2023-01-11 00:00:00: 0.0 2023-01-12 00:00:00: 0.02023-03-21 00:00:00: 0.0 2023-03-22 00:00:00: 0.0 2023-03-23 00:00:00: 0.002849920446183877 2023-03-24 00:00:00: -0.008815650741360098 2023-03-27 00:00:00: 0.0019657606321923085 2023-03-28 00:00:00: 0.0 2023-03-29 00:00:00: -0.003935393091582192 2023-03-30 00:00:00: 0.013706647466756726 2023-03-31 00:00:00: 0.006783509431897122 2023-04-03 00:00:00: -0.00970487369790382 2023-04-04 00:00:00: -0.009799982039630341 2023-04-06 00:00:00: -0.012885266481896753 2023-04-07 00:00:00: -0.00027168001429825724 2023-04-10 00:00:00: 0.0
14_卡马尔比率-Calmar
Calmar 分析器用于计算Calmar比率,这是一个衡量投资组合风险调整后收益的指标
Calmar = 最大回撤期间前的高峰回报率 / 最大回撤期间的回撤百分比
不知道为什么出来的值都是NaN,这个评价指标就暂时不用了
def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.Calmar, _name='_Calmar') def analyzer_output(result):print("---------------_Calmar -----------------")sout = result.analyzers._Calmar.get_analysis()print(sout)for key, value in sout.items():print(f'{key}: {value}')策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% ---------------_Calmar ----------------- OrderedDict([(datetime.datetime(2023, 1, 31, 0, 0), nan), (datetime.datetime(2023, 2, 28, 0, 0), nan), (datetime.datetime(2023, 3, 31, 0, 0), nan), (datetime.datetime(2023, 4, 30, 0, 0), nan), (datetime.datetime(2023, 5, 31, 0, 0), nan), (datetime.datetime(2023, 6, 30, 0, 0), nan), (datetime.datetime(2023, 7, 31, 0, 0), nan), (datetime.datetime(2023, 8, 31, 0, 0), nan), (datetime.datetime(2023, 9, 30, 0, 0), nan), (datetime.datetime(2023, 10, 31, 0, 0), nan), (datetime.datetime(2023, 11, 30, 0, 0), nan), (datetime.datetime(2023, 12, 31, 0, 0), nan), (datetime.datetime(2024, 1, 31, 0, 0), nan), (datetime.datetime(2024, 2, 29, 0, 0), nan), (datetime.datetime(2024, 3, 31, 0, 0), nan), (datetime.datetime(2024, 4, 30, 0, 0), nan), (datetime.datetime(2024, 5, 31, 0, 0), nan), (datetime.datetime(2024, 6, 30, 0, 0), nan), (datetime.datetime(2024, 7, 31, 0, 0), nan)]) 2023-01-31 00:00:00: nan 2023-02-28 00:00:00: nan 2023-03-31 00:00:00: nan 2023-04-30 00:00:00: nan 2023-05-31 00:00:00: nan 2023-06-30 00:00:00: nan 2023-07-31 00:00:00: nan 2023-08-31 00:00:00: nan ...
15_周期统计-periodstats
这是内置的最后一个指标了,我们直接读.py里的说明
get_analysis 方法返回一个字典,其中包含以下键:
average:平均回报率。
stddev:回报率的标准差。
positive:正回报率的数量。
negative:负回报率的数量。
nochange:无变化回报率的数量。
best:最佳回报率。
worst:最差回报率。def add_analyzer_all(cerebro):cerebro.addanalyzer(bt.analyzers.PeriodStats, _name='_PeriodStats') def analyzer_output(result):print("---------------_PeriodStats -----------------")sout = result.analyzers._PeriodStats.get_analysis()
# print(sout)for key, value in sout.items():print(f'{key}: {value}')策略为 经典MACD , 期末总资金 111569.09 盈利为 11569.09 总共交易次数为 11 ,交易成功率为 36.4% ---------------_PeriodStats ----------------- average: 0.06155213863943909 stddev: 0.10583966175667991 positive: 1 negative: 1 nochange: 0 best: 0.167391800396119 worst: -0.04428752311724082
内置评价实践小结
总体看下来,可以把这些内置评价的类分为2个大类:
第1个是直接打分或统计结果的类
- 01_AnnualReturn - 以自然年为分组的,比如 2023年 年化收益% , 2024年 年化收益%
- 02_drawdown - 当前回撤(周期,值,百分比) + 最大回撤(周期,值,百分比)
- 04_Sharp Ratio - 夏普比率,直接给出回测周期的夏普率
- 05_TradeAnalyzer - 交易分析,多重字典,包括交易次数(完成的,open),毛利率,净利率,连胜,连败,这里的Long short应该是开多,开空
- 06_SQN or SystemQualityNumber - 交易系统的性能得分
- 11_Returns - 回报 有4个数值,分别是总收益,平均收益,年化收益,年化收益百分比, 这个跟01的自然年不同,应该是计算近1年的(验证下?)
- 12_VMR Variability-Weighted Return, 是一种改进的夏普比率计算方法,可变加权回报率
- 15_PeriodStats 基本统计数据,包括回报率,标准差,正/负数量,最佳回报率和最差回报率
第2个其实是数据存贮类
- 03_TimeReturn 相当于每天的涨跌幅记录
- 07_GrossLeverage 类似每天的仓位%
- 08_PositionsValue 每天持仓数据
- 09_Transactions 每笔交易的数据
- 10_pyfolio ,这个是前面4个数据存贮的合集(03,07,08,09)
- 13_LogReturnsRolling 滚动回报率,好像还是对数形式的
简单的与股票软件的评价系统对比起来看一下,大部分的都有
对于某些可以自己根据数据存贮那几个类取数据再进行相关的运算,甚至还可以自己写继承自bt.Analyzer的类...


![[创业之路-141] :产品经理 - NPDP概述](https://img-blog.csdnimg.cn/img_convert/417b8b507676305ad57eed857c4dc536.png)
![[数据集][目标检测]夜间老鼠检测数据集VOC+YOLO格式316张1类别+视频文件1个](https://i-blog.csdnimg.cn/direct/3c31e661150241fe855d8e65e8a96ab5.png)