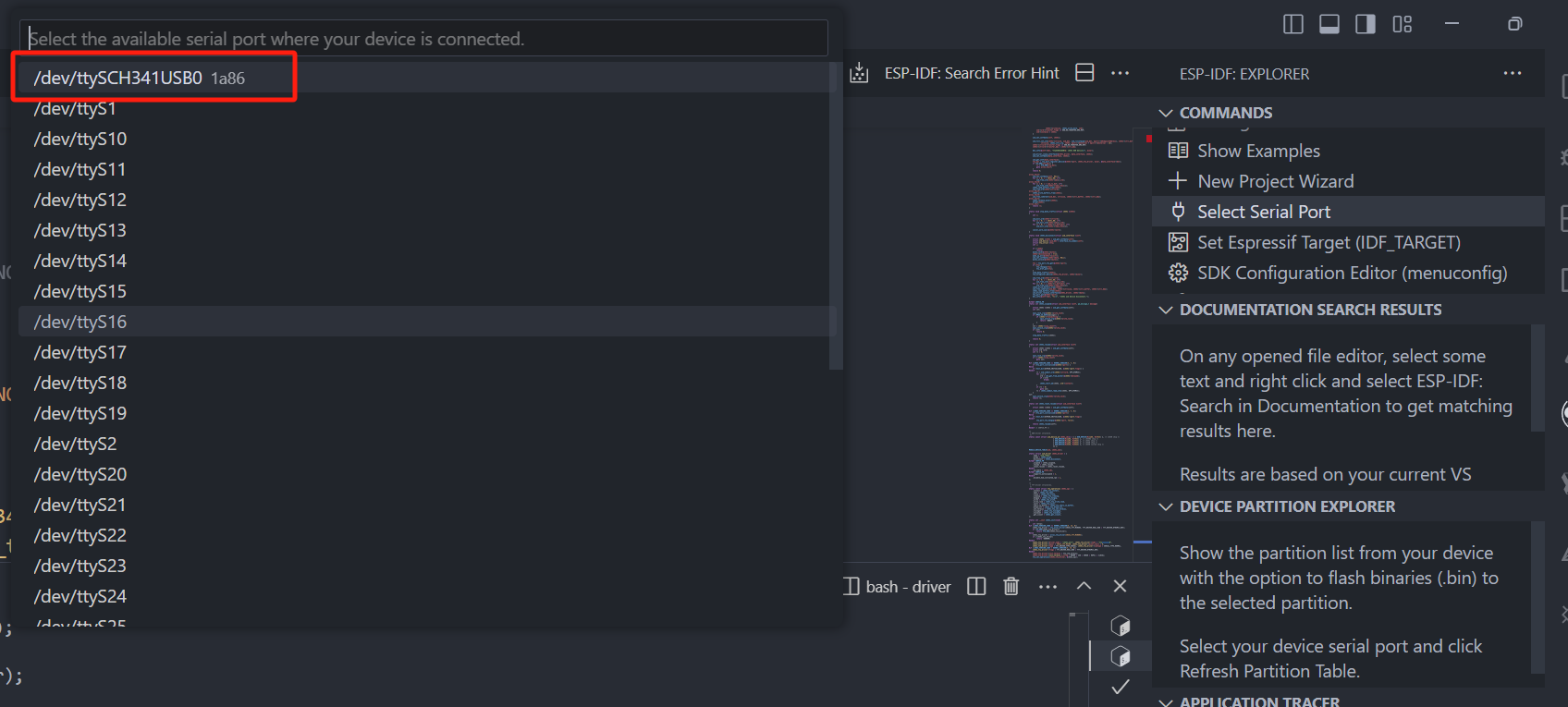
一、工程化体系介绍
1、什么是前端工程化
- 前端工程化 = 前端 + 软件工程;
- 前端工程化 = 将工程方法系统化地应用到前端开发中;
- 前端工程化 = 系统、严谨、可量化的方法开发、运营和维护前端应用程序;
- 前端工程化 = 基于业务诉求,梳理出最符合当前需要的架构设计;
软件工程:将工程方法系统化地软件工程应用到软件开发中;
工程方法:以系统、严谨、可量化的方法开发、运营和维护软件;
2、前端工程化发展
- 前后端分离:B/S架构兴起,有了前后端之分;
- 模块化:随着前端复杂度上升,模块复用、实践规范重要性提升;
- 自动化:管理&简化前端开发过程,前端框架、自动化、构建系统应运而生;
- 最佳实践:基于行业内最佳实践,开箱即用的框架(dva)、工具体系逐渐建立起来;
- 好、快、稳:依赖vite、esm、wasm、低代码等能力;
二、项目开发全流程
项目全流程包含5个阶段:
评审阶段、准备阶段、开发阶段、发布交付阶段、产后阶段

1、评审阶段
该阶段主要包括:
- 项目立项
- 编写需求
- 需求评审
- 开发设计、开发设计评审
- 视觉交互评审
2、准备阶段
该阶段主要包括:
- 新建仓库
- 构建或选择脚手架
- 项目初始化
3、开发阶段
该阶段主要包括:
- 开发/打包配置
- 本地mock
- 业务实现
- 单元测试
4、发布交付阶段
该阶段主要包括:
- git commit规范;
- changeLog规范;
- 打包构建;
- 部署、验收;
5、产后阶段
该阶段主要包括:
- 错误监控
- 数据分析
开发全流程的5个阶段,最终目的是确保需求按期上线,且上线后正常运行,没有生产问题,但是前端页面上线后需要有工程化工具来进行打分,也就是用户体验度量。
三、体验度量
1、体验度量要解决的问题

上图是度量面临的问题,针对这些问题,我们通过体验度量想要达到的目标是:

2、体验度量设计

上图中的FCP、LCP是通过前端性能监控工具performance给出的重要指标,我们会专门针对性能监控开一篇。

同时像error上报、用户基础数据日志上报、埋点事件、访问上报、卡顿率等指标都是用来评价前端页面性能的,这样可以让体验度量具像化。
四、规范流程
1、研发效能定义:
团队能够持续地为用户产生有效价值的效率,包括有效性(Effectiveness)、效率(Efficiency)和可持续性(Sustainability)三个方面。简单来说,就是能否长期、高效地交付出有价值的产品;

五、稳定性建设
随着业务迭代的发展,前端(to B/to C端)或多或少都有迭代周期快的压力,在业务的眼里,前端可能更多是“切图仔”,针对前端的具体实现并不关心。导致单人或小团队内很容易造成技术选型自由松散,缺乏约束和专门的技术限制,经常每个人或几个人自己维护一套代码开发流程,技术上更多体现在“拿来主义",工程链路不统一,代码重复度高,页面一致性差,各业务域松散,缺失共享,同时,在代码发布集成后的监控告警几乎没有,缺乏有效的监控手段与快速定位问题(可监控),及时止血(可恢复)的能力,并且缺乏项目的灰度与极值流量的压测,其实以上都是前端稳定性建设需要解决的核心问题。
基于上述内容,总结为三点:
- 可预防;
- 可监控;
- 可回滚;
通过以上三点,我们主要从研发态与运行态出发,通过研发流程的源码框架、工程规范,依赖检测去提高开发质量,发布过程中通过在发布节点上添加监控,做灰度卡口,避免问题带到线上,线上运行时通过实时监控告警实现快速定位问题,快速止血。
稳定性建设流程

1、可预防
(1) 规范团队代码研发流程
通过统一规范前端文档及开发工具,最大可能减少前端研发时差异化部分;
团队文档建设&新人指导
属于软机制,通过文档记录,保证团队在研发基础、故障认知上达成一致;
开发脚手架
通常要支持以下能力:
- git hooks、git commit配置;
- eslint配置;
- 根据命令行配置选择框架template;
- 支持测试用例集成;
组件&物料市场
针对业务属性,梳理常见的开发通用代码,包括但不限于: - npm包;
- 通用代码snippet集合;
- 业务组件物料市场;
(2) 攻防演练
通过日常及大促前的攻防演练,训练面对问题快速止血的演练机制;
故障&压测演练
考察针对流量异常、断网弱网等场景下的降级方案的处理;
代码CR注入
通过在代码code review时加入无效信息,检测是否认真查看CR内容,记录团队攻防数;
(3)灰度方案
- CDN分流
- 并不是所有项目都需要灰度发布,在CDN做层拦截对所有项目都有侵扰;
- 根据单一职责,CDN不应该做灰度分流的工作,若用代理模式再CDN前加一层代理分流,实际会造成无效流量的增长;
- CDN要记录用户是否命中灰度,通常需要加cookie,若命中多灰度,cookie增长会过多;
- N个版本文件打包到一个文件里
- 灰度比例可以通过随机数比例生产,但是要记录用户是否命中灰度,需要使用localStorage记录;
- 需要将文件*n(n为灰度个数)融合,会造成带宽的浪费;
- 前端分流后加载CDN
前端代码加载前先加载一次HTTP请求
- 虽然有优化,能解决文件体积过大的问题,但可能会导致一但出错,阻塞后续方案,且会额外调一次接口;
2、可监控

(1)数据采集
- 无埋点:自动采集
- 脚本异常
- 接口异常
- 资源异常
- 手动上报埋点:需要业务手动上报
- 脚本异常
script error:window.onError;
window.addEventListener('error', () => {})


-
addEventListener(‘unhandledrejection’):用于处理promise.reject没有处理的异常;

-
react错误上报(V16):componentDidCatch、getDerivedStateFromError;
componentDidCatch(error, info)class ErrorBoundary extends React.Component {constructor(props) {super(props);this.state = { hasError: false };}static getDerivedStateFromError(error) {// 更新 state 使下一次渲染可以显示降级 UIreturn { hasError: true };}componentDidCatch(error, info) {// "组件堆栈" 例子:// in ComponentThatThrows (created by App)// in ErrorBoundary (created by App)// in div (created by App)// in ApplogComponentStackToMyService(info.componentStack);}render() {if (this.state.hasError) {// 你可以渲染任何自定义的降级 UIreturn <h1>Something went wrong.</h1>;}return this.props.children;}
}
- 请求异常
XMLHttpRequest/fetch

- 性能采集

(3)数据上报
上报方式
- get 1*1像素GIF:体积小,不会带cookie,无跨域,无页面阻塞,服务器不需要响应;
- sendBeacon;
- xhr/fetch;
发送时机
- 立即发送、批量发送:requestIdleCallback;
(4)数据清洗
- 阈值处理:单位时间内错误数超过,抽样处理;错误数重复,只统计数量;
- 数据预处理:去除无用信息;
- 数据聚合:聚合有用数据;
(5)数据持久化
- 时效性高:告警 -> 大量数据查询,要求错误信息及时暴露,如 Elasticsearch;
- 时效性低:数据报表&大图展示 -> 大量数据存储,对数据量级有要求,时效性要求不高:如Mysql;
(5)数据可视化
- 数据告警:在上传CDN时添加卡口,支持手动上传sourcemap,定位问题上下文;
- 数据大图:支持按业务指标进行搜索;
- 健康报告:通过定时任务跑出系统内各个业务线的定量数据指标,进行指标的排名、治理,通过榜单形成红黑榜,正向推动循环;
3、可回滚
1、容器化部署
如果将代码和配置分开部署,在回滚的时候就会遇到"应该是先回滚代码还是回滚配置"的难题,所以,要想轻松回滚,在部署的时候,一定要将代码和配置整体打包,这里建议使用容器化部署,保证代码和配置可以整体回滚;
2、数据迁移
在业务变更涉及数据迁移时,应对数据表的字段采取"只增不删"的原则。因为当某个字段被当前代码引用的字段被删除后,线上业务是会出问题的,但新增一个没有被当前代码引用到的字段,则不会有问题。
等到确认新版代码工作完全正常,不会再回滚到旧版本时,才将旧字段删除。一旦旧字段被删除,引用到旧字段的旧版本代码就无法工作,也就无法回滚到旧版本了。
4、总结
总结上述内容,其实前端的稳定性建设更多地是对整个研发流程节点上故障的预防与治理,分别从可预防、可监控、可回滚三个维度进行梳理,简要介绍了一个完整的前端项目中在稳定性建设上的发力点,实际项目还是结合业务诉求,选择最合适的切入点,优先解决最痛点的问题。